[ニュースリリース] NTTコム オンライン、ソーシャルリスニング業務における抽出精度の課題をJubatusの活用により大幅に改善
~ テキストマッチ方式に対してF値(精度指標)が大幅に改善~
2015年1月15日
NTTコム オンライン・マーケティング・ソリューション株式会社(本社:東京都品川区、代表取締役社長:塚本良江、以下 NTTコム オンライン)は、Twitterをベースとしたソーシャルリスニング業務の効率化・高精度化を目的とした検証を行いました。
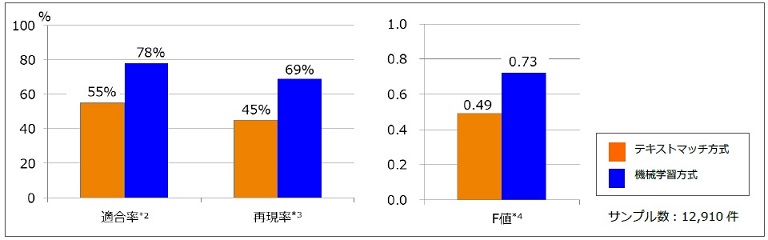
検証は、機械学習技術のリアルタイム分析処理基盤「Jubatus」を活用して実施しました。ツイートを抽出する作業においては、一般的に用いられているキーワードによるテキストマッチ方法と比較してF値が0.49から0.73に改善し、高い精度で抽出できるという結果が得られました。
ソーシャルメディア上の膨大なデータにはビジネス活用には無関係な情報も多く含まれています。その中から事業に役立つ顧客の声を、効率的に、かつ精度高く拾い上げることが企業には求められています。
今回の検証結果から、機械学習方式ではテキストマッチ方式と比較し、正解ツイート1件あたりの抽出作業工数*1が、当社試算で約30%削減でき、かつ必要な情報をより多く収集することができます。NTTコム オンラインは、この結果をふまえて、リアルタイムソーシャル分析ツール「BuzzFinder」での活用に加え、リアルタイムに顧客の関心、不満、要望を把握するソーシャルリスニングサービスのさらなる品質向上につなげてまいります。
<検証結果>
*1 抽出作業工数: 抽出結果を確認する工数÷抽出結果の中の正解ツイート数
*2 適合率:抽出結果のうち、どれだけ正解が含まれているか、の割合
*3 再現率:全ての正解データのうち、正しく抽出できた割合
*4 F値:(2×再現率×適合率)÷(再現率+適合率)
今回のテストはある特定のインターネット接続サービス(A社)に関する不満を対象に抽出テストを行った結果です。
機械学習とテキストマッチ方式での差分の例は以下になります。
例1:テキストマッチ方式により誤判定された例
「ゴミB社から神A社に乗り換えた!」
(A社を「神」と評価されているにも関わらずA社に対する不満と判定)
例2:機械学習でのみ抽出できた例
「A社信用してたのに……」
(テキストマッチ方式では事前のキーワード設定が困難なため抽出できなかった)
(参考)
リアルタイム分析処理基盤「Jubatus」
Jubatus は株式会社 Preferred Networks と NTT ソフトウェアイノベーションセンタ が共同開発を行っている、大規模データをリアルタイムに解析するための、”大規模分散リアルタイム 機械学習基盤”です。
(本件に関連するサービス)
ソーシャルリスニングサービス
https://www.nttcoms.com/service/sl/
リアルタイムソーシャル分析ツール「BuzzFinder」
https://www.nttcoms.com/service/buzzfinder/
■NTTコム オンラインについて
NTTコミュニケーションズ株式会社の100%出資グループ会社として2012年10月1日営業開始。
「マルチチャネル顧客接点構築」「ソーシャルCRM」「ビッグデータ解析」を事業の柱として、ビッグデータ時代の企業のオンラインマーケティングを支援しています。
会社名:NTTコム オンライン・マーケティング・ソリューション株式会社
所在地:〒141-0032 東京都品川区大崎1丁目5番1号 大崎センタービル
代表取締役社長:塚本 良江
株主 :NTTコミュニケーションズ株式会社 100%
URL :https://www.nttcoms.com/
本件に関するお客様からのお問い合わせ先
NTTコム オンライン・マーケティング・ソリューション株式会社
テクノロジー本部 片桐(かたぎり)、 嶋田(しまだ)