登録属性の中から、居住地や世帯構成などで抽出したり、性別や年代などで割付回収することもできます。 基本属性以外の条件は、スクリーニング(事前調査)を実施することで、抽出が可能です。



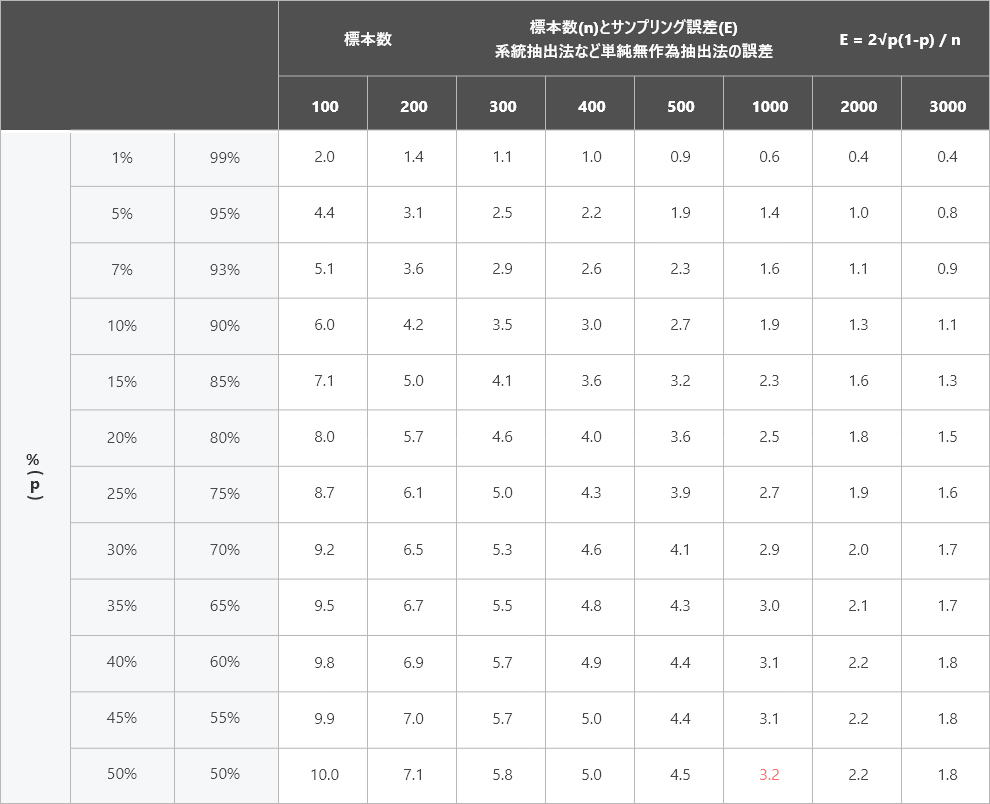
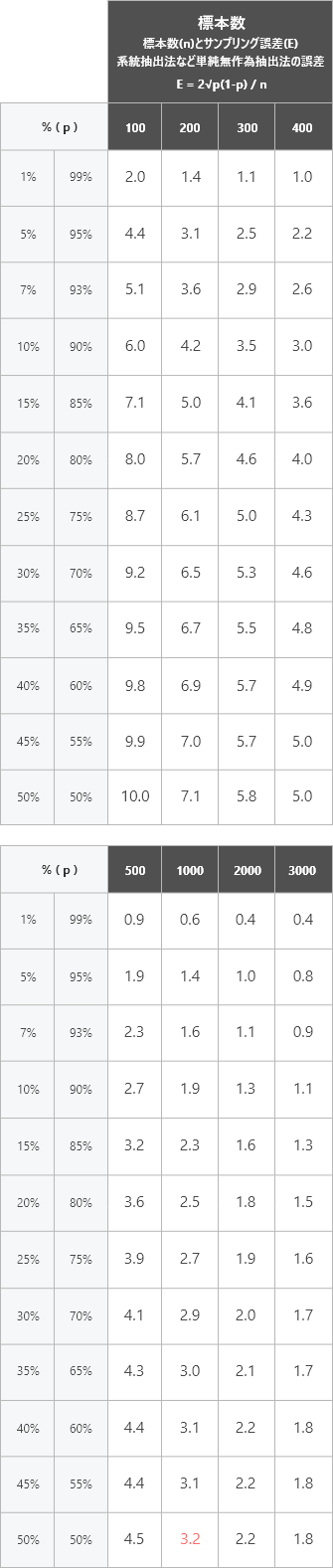
目標精度に必要な標本数を、主に下表「標準誤差早見表」で求め、決定していきます。
単純無作為抽出で「サンプルを○○件とり、その結果○○%の回答が得られた場合にプラス・マイナス何%の誤差があるか」をあらわしたサンプリング誤差早見表になります。
下表は、単純無作為抽出で「サンプルを○○件とり(下表横軸)、その結果○○%の回答が得られた場合(下表縦軸)に プラス・マイナス何%の誤差があるか」をあらわしたものです。
最も誤差が生じ易い「回答比率50%」で見た場合でも、「1,000サンプル」の場合ある回答で50%の回答が得られた場合「プラスマイナス3.2%(53.2%または46.8%)」になります。(下表 赤部分)
尚、下表の信頼係数は95%ですので、95%の確率で誤差は±3%の範囲内に収まるといえます。
(単位:%)
(※)年齢、年収、地域等のクロス集計を検討する場合、1グループ最低50サンプルは必要とされています。