![]()
![]()
![]()
![]()
2021/12/09
みなさんは業務フローという言葉をご存じでしょうか。よくご存知の方、今日も悪戦苦闘した方もいらっしゃるでしょう。業務フローとは、一連の業務の流れを個々のプロセスに分解し、部門で仕切った「スイムレーン」に時系列で並べて前後関係の矢印をつけたものです。矢印はデータの受渡しを意味する場合もあります。データまで描くとシステム化業務フローであって業務フローじゃないという流派もありますが、ここは目をつぶっていただければと思います。
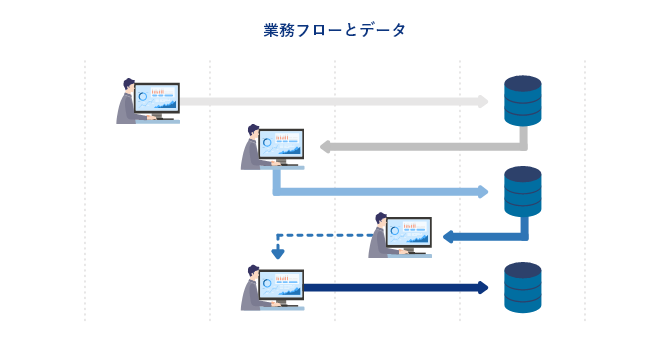
ここで注目したいのは、データの受渡しが「直列」で行われているということです。

プロセスには明確に前後関係があります。矢印をはさんで先行プロセス、後続プロセスなどと呼称することもあります。例えば、受注→出荷→請求→回収という業務プロセスは順番です。出荷を行うから請求ができ、請求したからお金が入ってくるという順番が存在します。Amazonが考えていた「注文を予想して自動で出荷する」というアイデアが革新的だったのは、受注の後で出荷するという順番をひっくり返すことだったからです。
プロセスは人が行っても、システムで実行してもかまいません。システム的には何らかのデータをインプットし何らかのデータをアウトプットすることがプロセスだからです。RPA (Robotic Process Automation)は、手動で行ってきたプロセスを自動化する仕組みです。単なる作業、つまり特に意思決定の必要がなく情報としての付加価値がないものを省力化するのは良いことだと思います。
さて、データに直列があるなら並列もある。これが今回のメインテーマです。自動化の対象は単なる作業と述べました。もちろんそれ以外の業務プロセスも多くあり、そちらの方が重要です。世の中でオペレーショナル・エクセレンス(圧倒的生産性向上)やデータドリブンと言われるのは、つまり単なる作業を省力化して、その代わりに意思決定とそれに伴うアクションをより優れたものにすることです。そして、同じ人が同じことをするなら、より多くのデータ、より正しいデータをより素早く活用する必要があります。
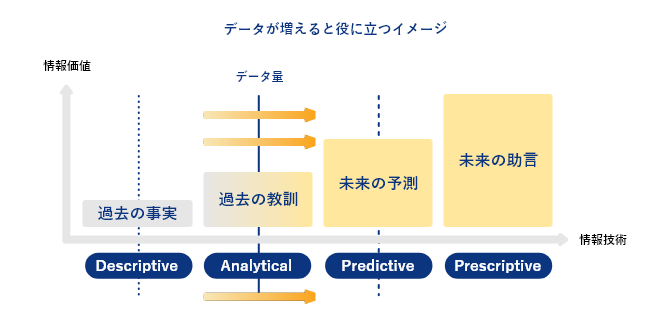
データ分析、ビジネスインテリジェンスには進化に伴う四つの段階があると言われています。第一段階は”Descriptive”(デスクリプティブ=描写的)です。過去をデータで見られることです。簡単そうに書いていますが、データ連携やデータウェアハウスの役割はここを整えることです。次の段階に行くためにはこの第一段階をクリアしなくてはなりません。
第二段階は”Analytical”(アナリティカル=分析的)です。過去に起きた事象(ファクト)の因果関係や起承転結を把握できることです。現時点で問題があるのであれば、その原因がデータを通じて把握できるようになることです。色々なファクトの関連付けを行うため、データの種類、粒度、精度いずれもレベルの高いものが必要です。
第三段階が”Predictive”(プレディクティブ=予測的)です。過去をもとに未来を予測するところまでいきます。過去に問題があったなら、その対策を立てるまでをデータに基づいて行います。データサイエンスやAIはこの段階で真に活かされます。当然ながら第二段階よりもさらに大量かつ正確なデータが必要になります。
私たちがジャパン・ディストリビューターを務めるTIBCOでは、”PREDICT”というビジョンを掲げ、TIBCO Spotfireというビジュアルアナリティクスソリューションを活用そして進化させています。それと同時にデータの収集と統合、精製、解釈にも力を入れています。
第四段階が"Prescriptive"(プレスクリプティブ=処方的)です。日本語では処方的と訳されますが、つまりは「何をすれば良いのか」までをデータから作りだします。人の意思決定そのものまである程度踏み込んだ支援を行うのが第四段階のデータ活用です。現在、オペレーションズ・リサーチやジェネレーティブデザインなど限られた領域で実現していますが、今後は加速度的に範囲が広がっていくことでしょう。これは入手できるデータの量、質、そしてスピードの増加にかかっています。
いずれの段階もデータを活用してプロセスに役立てます。その原理がデータの並列利用です。
直列とは仕事の流れに沿ってデータを流していくことでした。その中で業務プロセスや意思決定の出来を左右する要素をEnabler(イネーブラー)と呼びます。これは経験や知見などの武器のことです。とはいえ経験や知見は属人的なものです。
ここでデータを使いたい。より優れた判断を行うための指標をデータに求めたい。これがデータの活用です。そのために今必要なデータをあるだけ欲しい、できるだけ新しいデータを幅広く「今」欲しい。すべて「今」ほしい。場所は関係なく同時に必要である。これが並列の意味です。このデータはフローの上流にいるかもしれません、方や別のデータは下流にいるかもしれません。データの並列利用とは色々な業務フローという川の断面をどこからでもスパッと切って、すべてのデータを同時に活用することです。
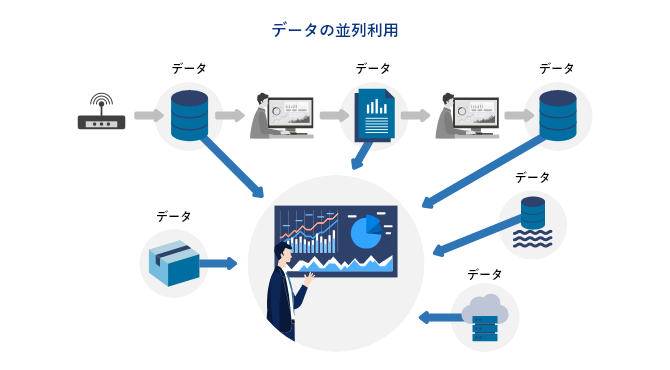
しかし、一方で従来のシステム構築の発想は直列です。言ってしまえば夜間バッチでのデータ連携です。既に持っているデータを一箇所に集めるだけなのに、データウェアハウスの構築には数ヶ月以上かかります。項目を一つ追加するのも何週間とかかります。なぜなら、設計、テスト、他システムとの整合性確保が必要とされるからです。直列をつかって並列に情報を集めている以上、色々なところに無理が発生します。では、直列の延長線上の発想ではなく、既存のシステムから並列にデータを収集できる新しい発想や方法は無いのでしょうか?
現時点でのベストアンサーがデータ仮想化です。
以下の内容や不安をすべて実現・解消し、データの並列利用を実現するのがデータ仮想化です。
データにもCSVありRDBMSありXMLがありHDFSがありますが、基本的に表形式になります。それであれば、データを表形式に直しさえすれば、あとはJOINでもSELECTでも思いのまま操作できるはずです。
データベースが分散していても、それぞれユーザーIDとパスワードを貰えばログインできます。それであれば、代表で一つのログインIDを取得しツールに代行ログインをしてもらえば問題ありません。
そんなことをしたらセキュリティが心配でしょうか?代表IDでログインしても誰がどのデータをいつ見たのかを完全に追いかけることができれば安心です。個人情報、部門情報などにシルシをつけ、誰が見ていいかを決めてシステムが自動マスキングしてくれるなら完璧です。
クラウド環境があちこちに散らばっているため、SQLで直接データベースに問い合わせるだけというのは不自由でしょうか?データベースとしてSQLの問合せを受けるだけでなく、APIとして公開することもできれば、外部のプログラムからAPIを叩いてデータを取得することもできるようになります。
リアルタイムでデータを取得するにしても、相手システムが夜間バッチ中だったり落ちてたりしたらどうするのか?それぞれのデータをキャッシュで持てれば心配ありません。もしフィルタリング後やサマリ後のデータでよければキャッシュも一層軽量化ができます。
いくら便利でも、データの意味がわかって探せなければ意味がないでしょうか?
もしデータにタグや注釈をつけられて、それを検索できれば労力の9割は削減できるはずです。
TIBCOのデータ仮想化ソリューション TIBCO Data Virtualization(TDV)は、データの並列利用を実現し、これからのデータ活用、データドリブンな組織作りを強力にご支援します。




