![]()
![]()
![]()
![]()
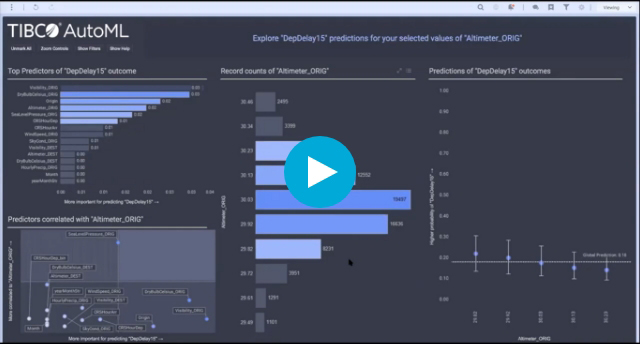
組織全体で機械学習を民主化し、コラボレーションし、運用化する
データサイエンスはチームスポーツです。データサイエンティスト、シチズンデータサイエンティスト、データエンジニア、ビジネスユーザー、および開発者は、分析ワークフローに関するコラボレーションと、分析ワークフローの自動化、再利用を促進する柔軟で拡張可能なツールを必要としています。アルゴリズムは高度な分析パズルのほんの一部にすぎません。予測的インサイトをビジネスに活用するために、企業は分析モデルのデプロイ、管理、およびモニタリングにさらに重点を置く必要があります。スマートなビジネスには、エンタープライズレベルのセキュリティとガバナンスを提供しながら、エンドツーエンドの分析ライフサイクルをサポートするプラットフォームが必要です。Spotfire® Data Scienceにより、企業は複雑な問題をより迅速に革新・解決して、予測的知見を迅速に最適な結果に変えることができます。
膨大なアルゴリズムで探索的分析を可能にするWorkbenchの詳細はこちら
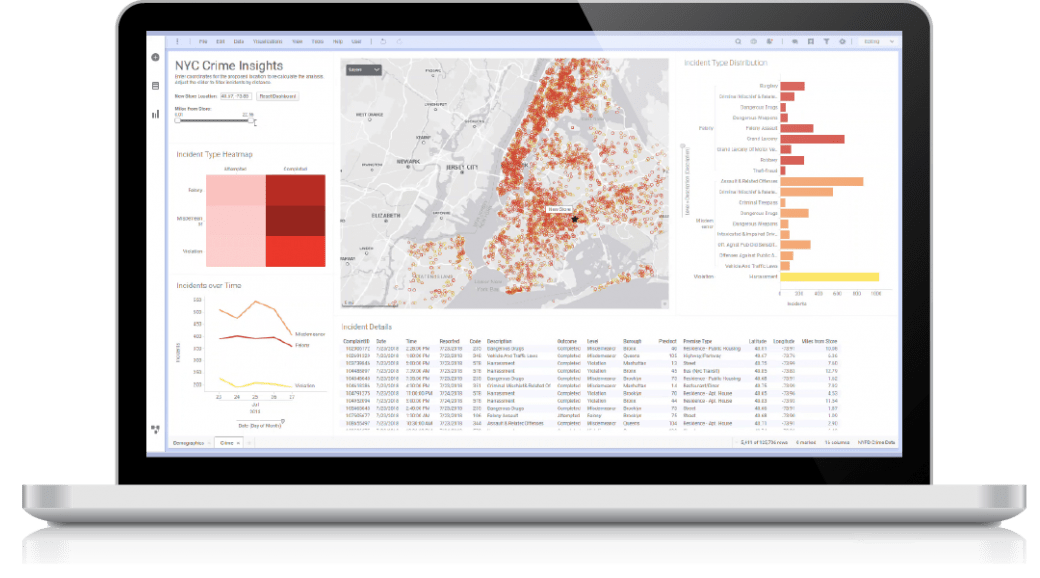
Spotfire® Data Scienceソフトウェアを使用すると、データ前処理からモデルの構築、デプロイ、モニタリングに至るまで、日常業務を自動化し、問題を解決する機械学習(MachineLearning : ML)アルゴリズムを活用したビジネスソリューションを作成できます。作成済みのテンプレートを使用してアプリケーション開発を迅速に実現しましょう。
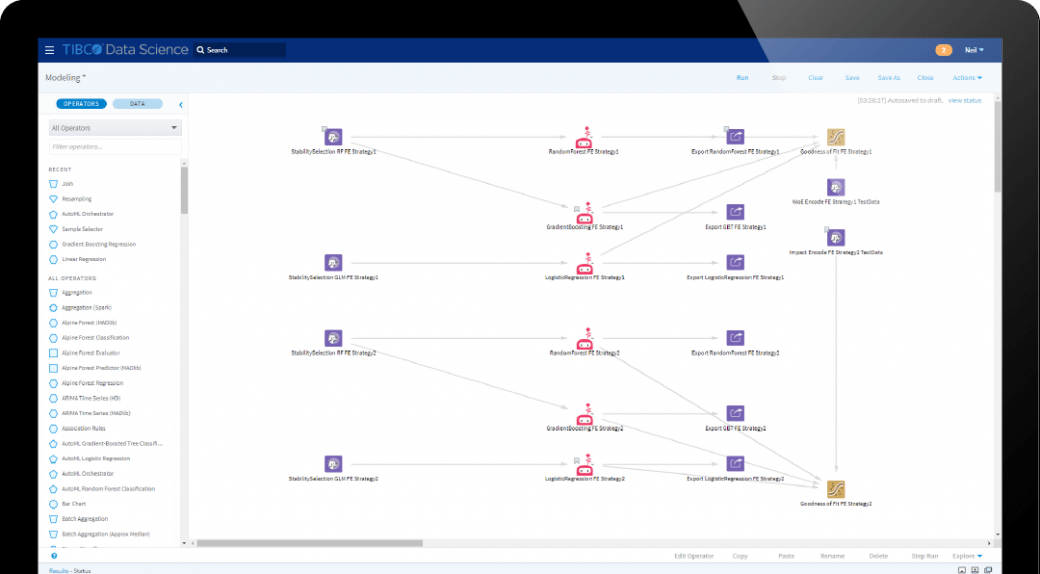
チーム全体、シチズンデータサイエンティストから専門家までの創造性を活用します。AutoML、直感的なドラッグアンドドロップワークフロー、組み込みのJupyter Notebookを組み合わせて、再利用可能なモジュールの作成と共有を簡単にします。また、開発・運用に必須となる、情報の透明性、セキュリティ、バージョン管理、および監査可能性を維持します。更に、Spotfire® からワークフローを実行することにより、機械学習、データ、プロセスと、人による分析を組み合わせた運用ソリューションを実現します。
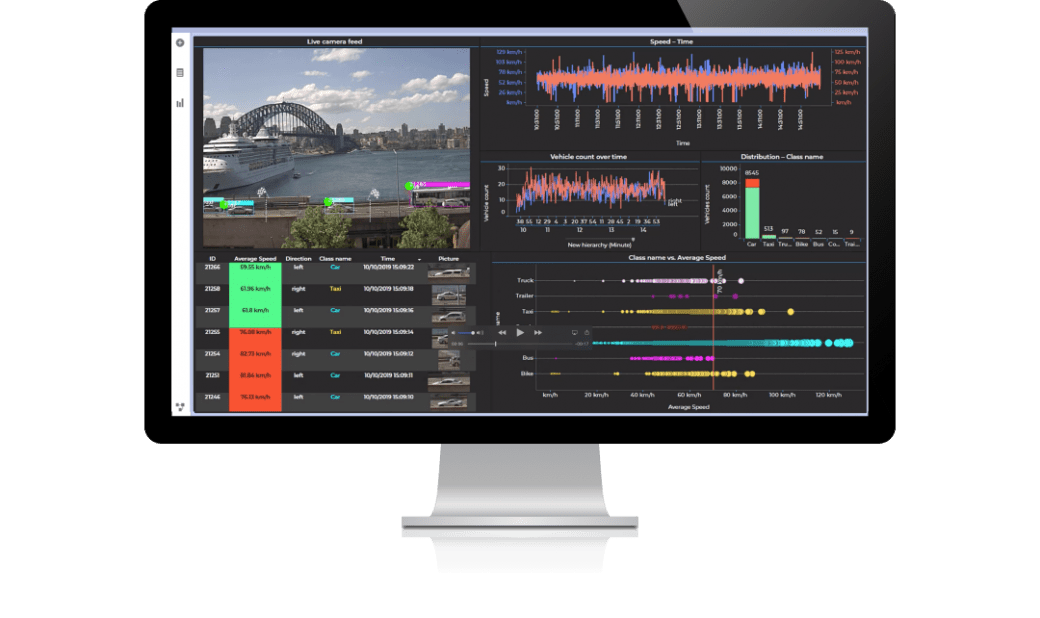
クラウドサービス、フレームワーク、PythonやRなどのオープンソーステクノロジーは複雑でハードルが高い可能性があります。Spotfire® Data Scienceは、ハイブリッドエコシステム全体でデータサイエンスと機械学習をシンプルにします。Spotfire® Data ScienceとTensorFlow、SageMaker、Rekognition、Cognitive Servicesなどを使用して、オープンソースの複雑さを解決し、革新的なソリューションを作成します。
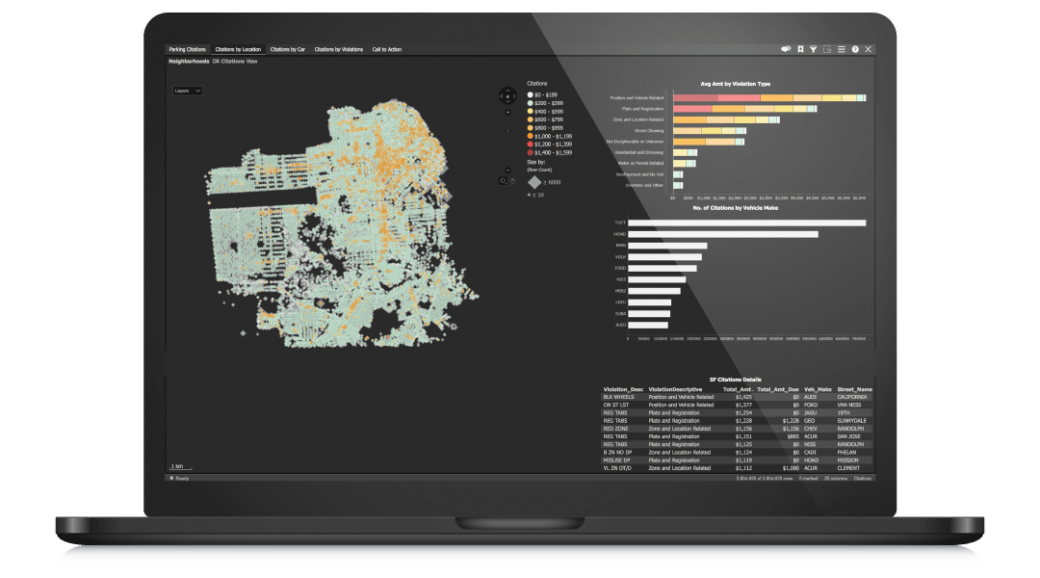
多くの組織は、作成した分析モデルの本番環境へのデプロイ、運用に苦労しています。データがドリフトし、モデルが衰退するにつれて、新しい分析モデルをエッジ、またはビジネスシステム内で直接モニタリング、再トレーニング、再モデル化、および自動的にデプロイできるため、信頼できる結果に基づいて考え、行動することができます。
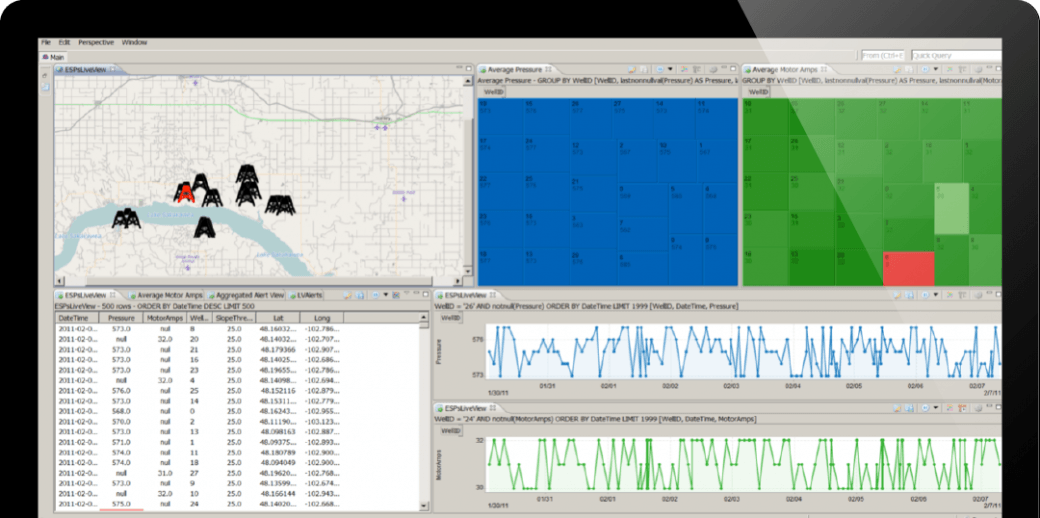
TIBCO Flogo®、Spotfire® Streamingとの組み合わせにより、組織は任意のエッジデバイス、ゲートウェイ、またはマイクロコントローラ上で実行することができる、最新の深層学習、予測的、処方的、AI等の分析技術を組み合わせた革新的なパイプラインを作成することができます。持続的な競争上の優位性により、新しいビジネスチャンス、収益源、資産の収益化を導き出します。
分析の信頼性を確保するためには、まず信頼できるデータが必要です。 データ仮想化製品TIBCO® Data Virtualizationは信頼できる唯一の情報源として、最新のデータをユーザー権限に応じて提供します。マスターデータ管理製品TIBCO EBXは組織全体のデータの整合性と流通性を確保します。これらのデータ統合製品との連携により、現在および将来のビジネス目標の成功に必要なデータ管理/分析のスイート機能を提供します。
回帰分析、クラスタリング、決定木、ニューラルネットワークといった統計手法や機械学習アルゴリズムをはじめ、テキスト分析やグラフ/ネットワーク分析、SPC(統計的工程管理)、実験計画法(DOE)など、16,000以上の関数やアルゴリズムが組み込まれ、これらを簡単に利用できます。
HadoopやSpark上で実行できる機械学習アルゴリズムを用いて、大規模データから自動で学習しパフォーマンスを最適化します。プログラミングすることなく、新たなパターンを発見しインサイトを発掘できます。
データの取り込みから前処理、モデル構築、デプロイまで、ドラッグアンドドロップによる直感的なUIで簡単に実装し、分析プロセスを共有できます。プロジェクトへの関与を少数のデータサイエンティストに限定せず、ビジネスエキスパートや開発者、データエンジニアに広げ、チーム全体の創造性を活用できます。データやスクリプト、モデル、ワークフローを共有・再利用ができ、チーム間のコラボレーションを容易にします。
作成した分析モデルの有効性は、チャンピオン/チャレンジャーテストで比較します。モデル精度を監視し、簡単にモデルの更新が可能です。また、ワークフロー自体をデプロイし、スケジュール実行も行います。PMMLやPFA形式の分析モデルをCloud FoundryやAWS、Google App Engineへプッシュし、リアルタイムスコアリングを実現できます。EMRやRedshiftでモデルを構築し、オンプレミス環境でOracleやTeradataにデプロイすることも可能です。
Spotfire® Data Scienceは、データセキュリティポリシーのもと、セキュアなクラスターと連携しHiveやSpark上で高度な分析を実行します。システム内の全てのアセットに対して、ロールベースでのセキュリティを実現します。バージョン管理、監査ログ、承認プロセスの機能が組み込まれています。
AmazonやAzure、Google等クラウドエコシステムとシームレスに統合しながら、オープンソースのPythonやR、Jupyter Notebook、C#、Scalaを利用して、分析ワークフローを拡張できます。これらの技術を使用することで、データのカバナンスとセキュリティを維持しながら、新しい柔軟なソリューションを迅速にプロトタイプできます。

人工知能 (AI) や機械学習 (ML) の取り組みを組織全体にとって価値あるものにするためには、AI/ML が提供するインサイトを適切な人やシステムに対して、適切なタイミングで提供する必要があります。本資料では、AI とML を運用化し、データサイエンスで競争優位を獲得するためのわかりやすい9つのレシピについて解説します。