![]()
![]()
![]()
![]()

2021/03/05
想像してみてください。あなたはフォーチュン1000社に属するデータエンジニアです。あなたの会社には何千ものデータベースがあり、14,000人ものビジネスインテリジェンス(BI)ユーザーがいます。あなたはデータ仮想化を利用して、データビューを作成し、セキュリティの設定を行い、データを共有しています。簡単でしょう?しかし時々、それが困難になる場合があります。
データ仮想化には6つのフロンティアがあるのです。
最新のデバイス、乗り物、ロボット機器の殆どはセンサーが組み込まれています。世の中のサプライチェーン管理者は天候変化を予測したいと考えています。これらは全て流れているデータ(data in motion)です。しかし、第一世代のデータ仮想化ツールは保存されたデータ(data at rest)用に設計されています。ここでデータエンジニアが頻繁にリクエストされる内容を見てみましょう。
「123番のマシンのメンテナンス履歴と現在のセンサーの読み取り値を見せてくれ」
ストリーミングデータの前処理(英語)ツールは、流れているデータをストリーミングテーブルに変換します。テーブル内のレコードはイベントごとに更新されます。ディスク上のデータに接続するのではなく、データストリームに直接接続します。前処理を実行することで、Kafka、MQTT、ドローンデータ、気候情報、IoTセンサーの読み取りから発生するイベントを整備、集約、拡張します。
ストリーミングデータの仮想化には、まずストリーミングテーブル をデータ仮想化ツールのデータソースに変換します。
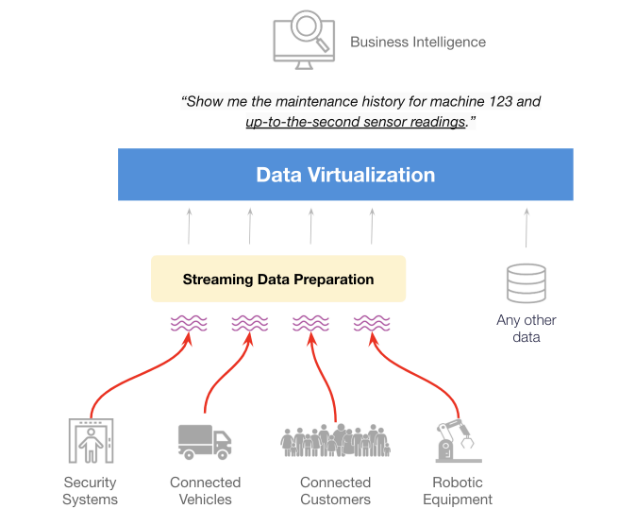
デジタルトランスフォーメーション推進において、流れているデータの管理は新たな重要課題となっています。ストリーミングデータの仮想化は流れているデータをインサイトに変換します。これがデータ仮想化の第1のフロンティアです。
AIおよびデータサイエンスは白熱したテクノロジー分野です。データサイエンティストは貪欲にデータを収集し、アルゴリズムを創造します。これらのアルゴリズムによって、ローデータを元にした予測データが導出されます 。データ仮想化の新たなフロンティアは、これらのモデルの入出力をデータサービスとして提供し、関係者やステークホルダー、そして利用アプリケーションに一貫性を持たせることです。ここで典型的なビジネス部門からのリクエストを見てみましょう。
「顧客Xが何を購入したのか、そして次に何を購入する可能性が高いのか教えてくれ」
データサイエンス・ラブストーリーの悪役は、データサイエンスのサンドボックスです。データサイエンスチームはアルゴリズム開発のため、しばしばプライベートなデータストアを作成します。データサイエンスのサンドボックスは数学者の実験室のようなものです。
データサイエンス・ラブストーリーの悪役は、データサイエンスのサンドボックスです。データサイエンスチームはアルゴリズム開発のため、しばしばプライベートなデータストアを作成します。データサイエンスのサンドボックスは数学者の実験室のようなものです。
肝となるのは、サンドボックス環境に依存する部分をアルゴリズムから除外し 、本番環境に移すことです。一方、企業によってはパフォーマンス、セキュリティ、スケールを確保するためにアルゴリズムを書き換えています。そこで2つの新しいテクノロジーが、この摩擦を軽減するのに役立ちます。
まず初めに、正確で実用性のあるモデルを開発するためには、アルゴリズム評価に利用可能な一貫性のあるデータが必要となります。これをデータ仮想化のデータビューとして作成することで、データサイエンスを加速させることができます。
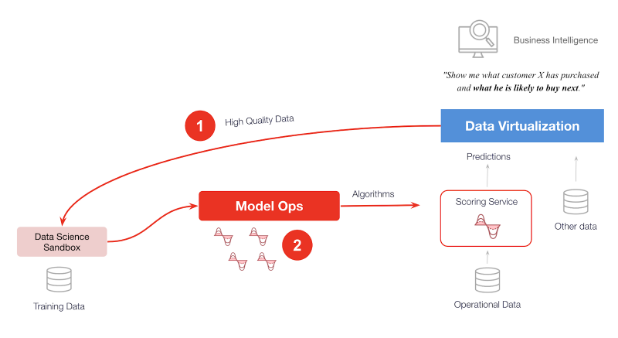
(1)データ仮想化は研究用の高品質なデータを提供します。(2)データ仮想化は効果的なアルゴリズムやモデルの発見およびModel Opsによるサンドボックスから本番環境への展開を加速します。得られた予測モデルはビジネスインテリジェンスなどのオペレーショナルシステム上で利用されます。
データサイエンスチームが有用なアルゴリズムを見つけたら、次は何をする?
新しい選択肢としてModel Ops(モデルオペレーション)ツールに、アルゴリズムを格納するというものがあります。Model Opsツールはアルゴリズムのライフサイクルとデプロイを管理します。例えて言えば、アルゴリズムの駐車場のようなものです。データサイエンティストは、顧客が次に何を買うかを予測するアルゴリズムをModel Opsツールに駐車します。するとデータエンジニアは駐車場からモデルを選択し、データ仮想化環境にデプロイすることができ、アナリストは顧客が既に購入したものとあわせて、顧客が次に何を購入する可能性が高いかを問い合わせることができるようになります。
仮想データサイエンスは、企業のAIドリブン化を支援します。データサイエンスチームはより良いデータを手に入れることができ、チーム内のコラボレーションは向上し、より多くの優れたアイデアの発見に繋がり、活用されます。仮想データサイエンスは数学をインサイトとROIに変える革新的で優れた方法です。
APIは、現代のデジタルビジネスにおけるアプリケーション間の標準的な連携手段 です。時にAPI自体がビジネスモデルになることもあります。しかし、APIは製品と同様に管理する必要があります。そこでAPI管理ツールの出番です。
「そのデータにAPIでアクセスしたいのだが?」というのは、今日データエンジニアが受ける代表的なリクエストの1つです。確かにサービスにREST APIを実装することができますが、そうすべきでしょうか?誰がコールをしているのでしょうか?何回?ビジネス部門はAPIアクセスの料金請求を行うのでしょうか?それはいくらでしょうか?
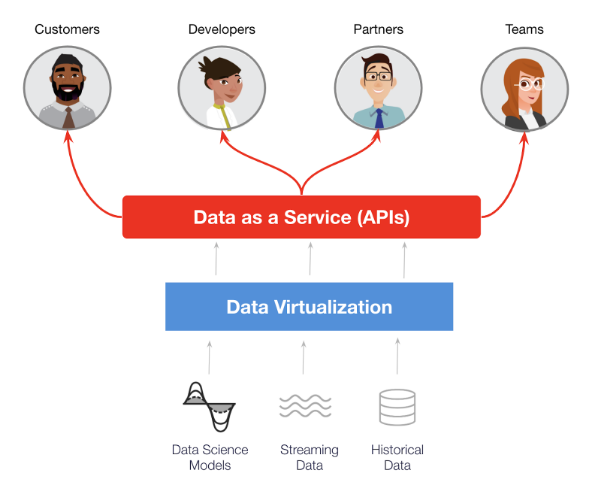
DaaSツールでは、APIとして公開したいデータビューを選択することが可能です。API管理ツールはAPIを製品として管理します。
仮想化されたデータをサービス化させることは、データ仮想化の第3のフロンティアです。
2020年3月、Panera Breadはビジネスモデルをひっくり返すことにしました。彼らは2,000軒のカフェレストランを食料品店に変えたのです。今では、顧客が自宅でPanera品質の食品を食べられるように、食材を販売しています。
このようなビジネス・トランスフォーメーションを行うためには、メタデータ、つまりデータに関するデータが必要です。Paneraは、メタデータを一カ所に集めています。メニュー、レシピ、サプライヤー、在庫データへ瞬時にアクセスできることで、彼らは10日間でビジネスモデルを変えることができました。
PaneraのNoel Nitecki氏は「私たちにとって、データそのものは後付け的なものです」と述べています。
データ仮想化はメタデータツールによるメタデータの収集を簡素化することができます。データ仮想化の第4のフロンティアはメタデータの収集を強化することです。
将来、ほとんどの労働者はナレッジワーカーになるでしょう。彼ら全員がデータを必要とし、同じデータビューを共有する必要があります。しかし、全員がデータの複雑さを理解しているわけではありません。そこで「シチズンツール」を利用することで、非エンジニアでもデータを管理できるようにします。シチズンツールはデータ仮想化の第5のフロンティアです。
例えば、Paneraの5万人の従業員は、単一のデータビューを共有しています。そのため、彼らが食材を販売することを決めたとき、全チームがワンチームとして作業できました。チームには以下のメンバーまたはリスト内容を担当するメンバーが含まれます。
そして、IT部門は各メンバーの ために設計されたツールを用意する必要があります。
以下はニーズの一例です。
ワンチームでデータを活用するために、データ仮想化はこれら全てのペルソナに対応した様々なツールにデータビューを提供する必要があります。
品質管理はデータエンジニアの仕事の一つです。データクオリティツールは、データクレンジングと検証を支援します。データエンジニアはデータクオリティに関する機能がデータ仮想化の一部として含まれていることを期待しています。データ仮想化にビルトインされたデータクオリティツール はデータ仮想化の6つ目のフロンティアです。
データクオリティツールがあれば、データ利用者はデータの整合性を信頼することができます。結果として、分析を通して得られるインサイトはより正確でビジネスインパクトを与えるものとなります。
データは今日のデジタルビジネスにおけるソーラーパワーです。石油ではありません(英語)。6つのデータ仮想化のフロンティアは未来を表しています。言うなれば、自動運転や電気自動車のようなものです。誰がデータ仮想化のTeslaになるのでしょうか。
TIBCO Data Virtualizationの詳細についてはこちらをご参照ください




