![]()
![]()
![]()
![]()

2021/04/27
Python連携
このコンテンツでは、選択したデータを縦変換する方法について説明していきます。
なお、本コンテンツで利用したSpotfireのバージョンは10.10/11.4です。ご利用環境によって、一部画面構成が異なる可能性がありますので、ご了承ください。
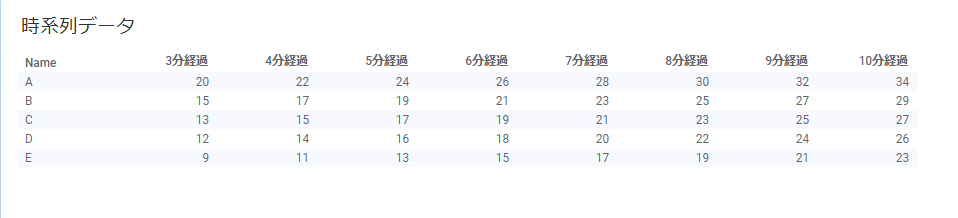
次のテーブルのように、時系列項目がカラムとしてまとめられているデータはよくあります。
人が読むにはわかりやすいですが、コンピュータに制御させる場合は色々問題が生じる場合があります。BIにおいても、期待する可視化を実現できない場合があります。
そのような場合、次のテーブルのように、データを縦変換することにより、解決する場合があります。
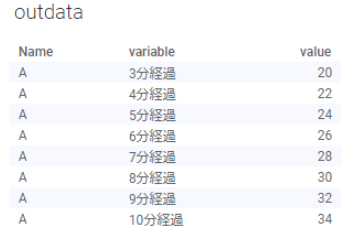
別ページで紹介しているピボットの解除(データの縦変換)は、データテーブルを一括で縦変換するものです。
大量データを扱う場合、必要なデータだけ縦変換する方がピボットの解除よりも時間とリソースがかかりません。
(選択データのみ縦変換)ではTERRを使った方法をご紹介していますが、今回はPythonを使って必要なデータだけ縦変換する方法をご紹介していきます。
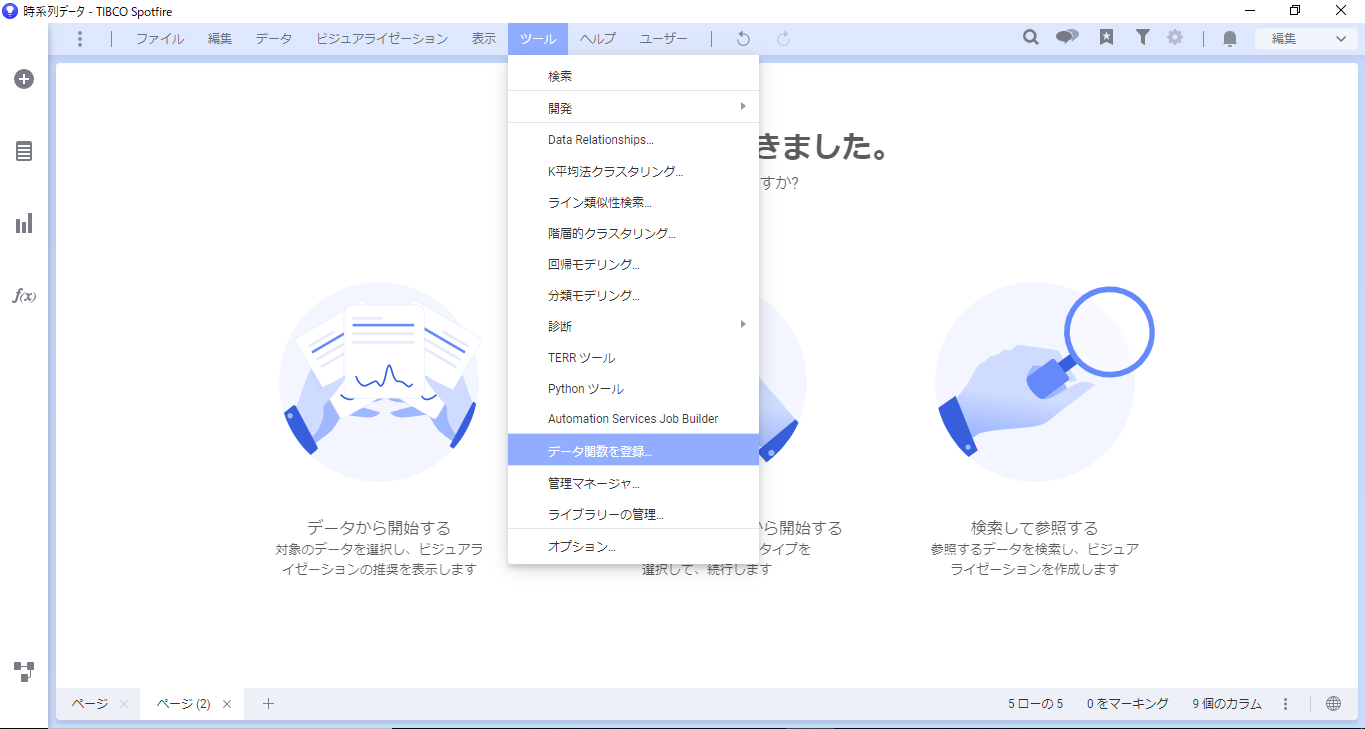
メニュー内の「ツール」から「データ関数を登録」を選択します。
「データ関数の登録」ダイアログでは以下を設定してください。
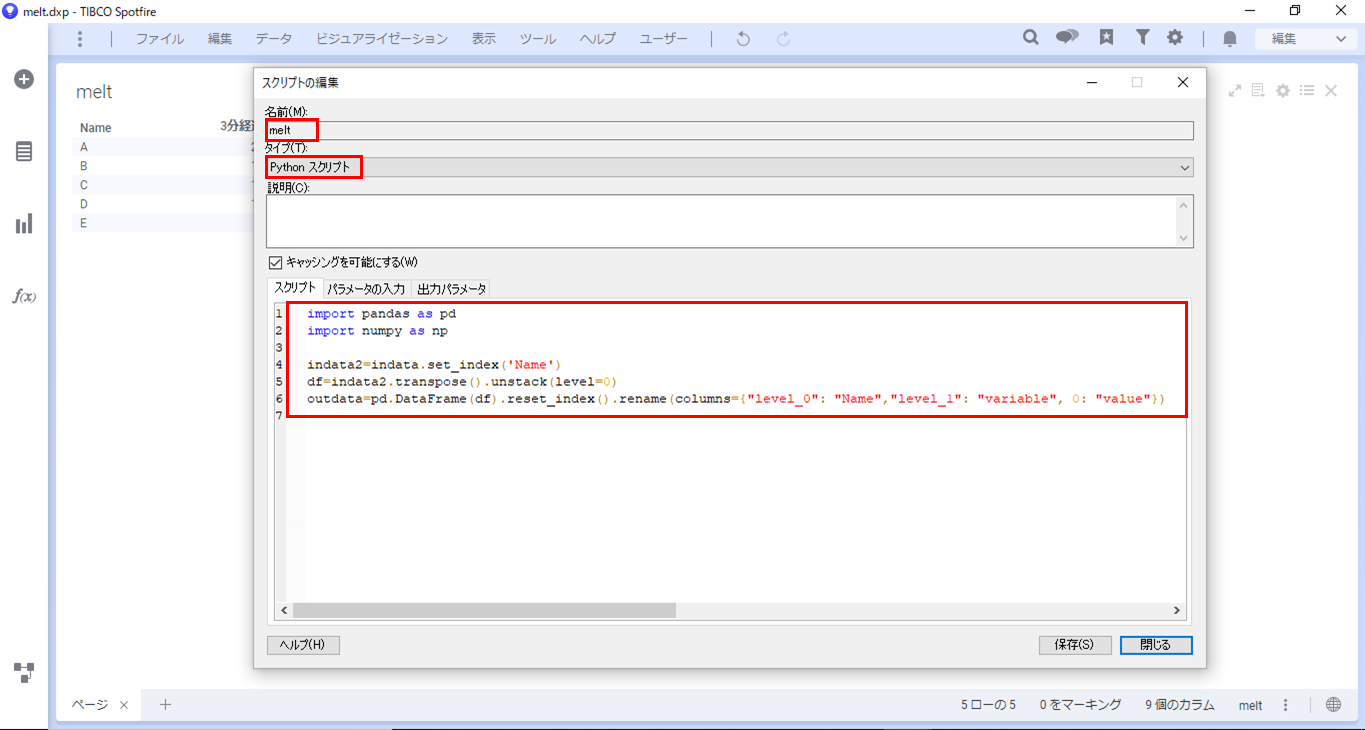
indataを入力とし、縦変換したデータをoutdataとして受け取るというスクリプトができました。
入力パラメーターとしてindataを定義します。「パラメータの入力」タブに移動し、「追加」をクリックします。
「入力パラメータ」ダイアログでは、以下を設定し「OK」をクリックします。
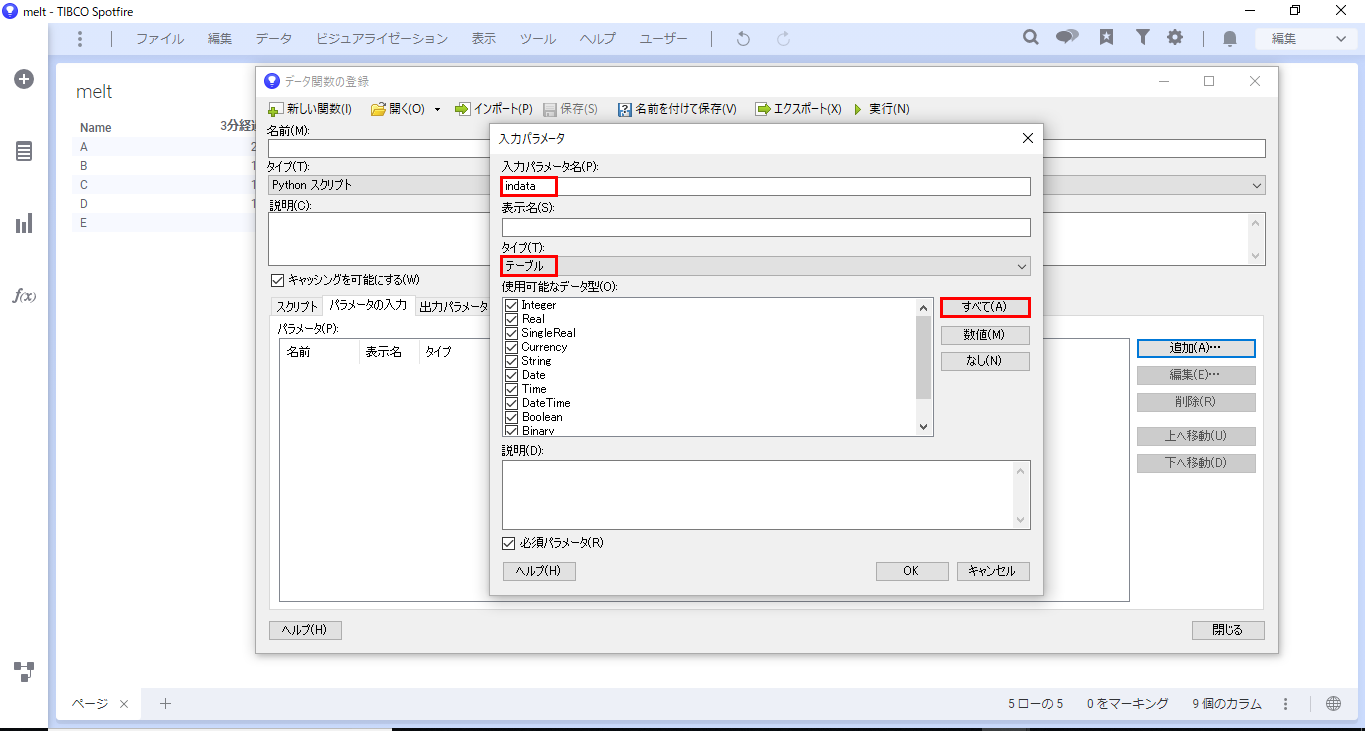
出力用にoutdataを定義します。「出力パラメータ」タブに移動し、「追加」をクリックします。
「出力パラメータ」ダイアログでは、以下を設定し「OK」をクリックします。
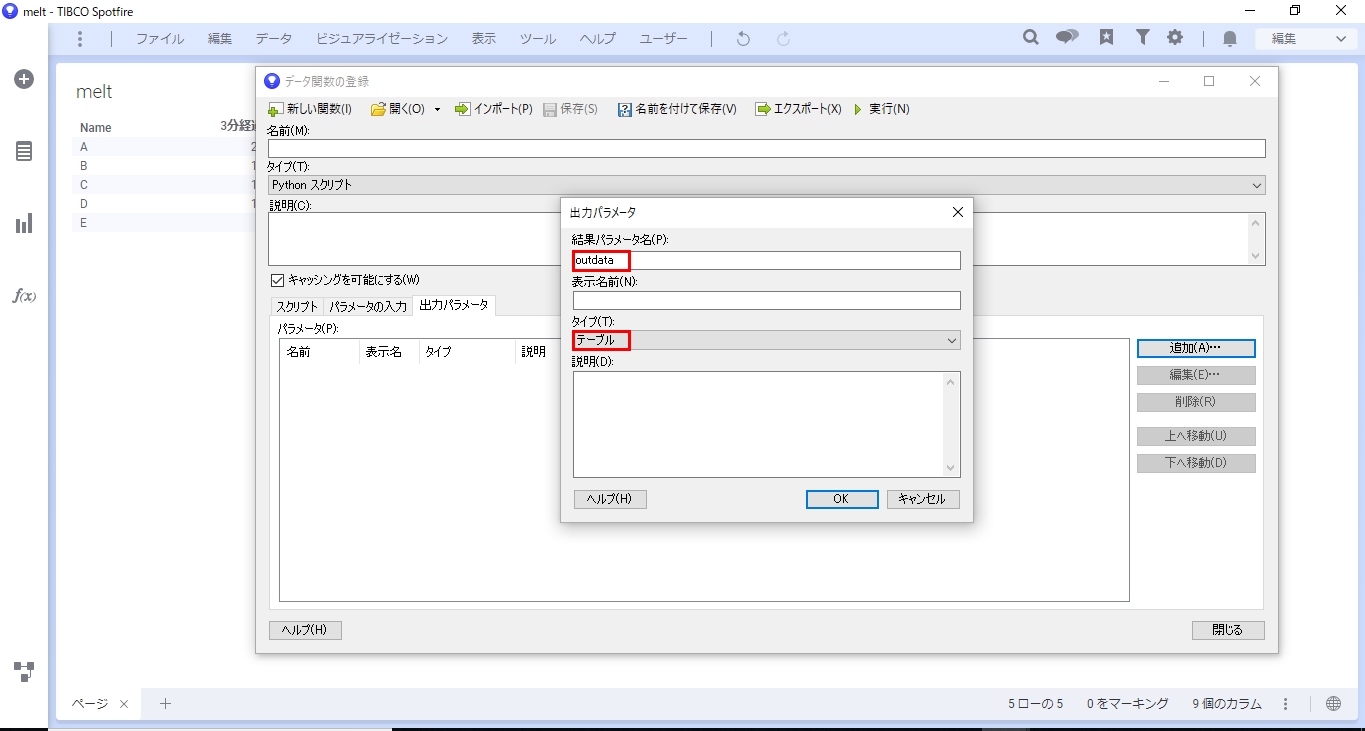
「データ関数の登録」ダイアログに戻り、右上の「実行」ボタンをクリックします。
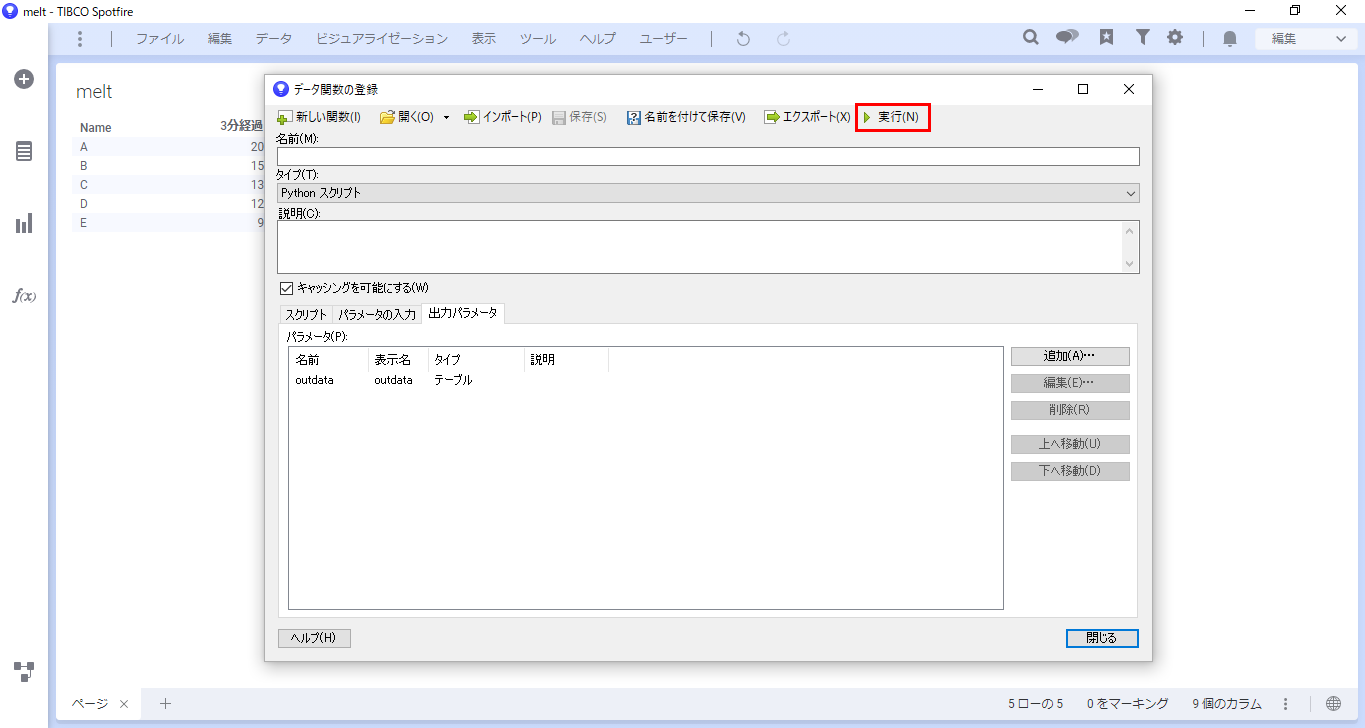
「パラメータの編集」ダイアログが開きます。
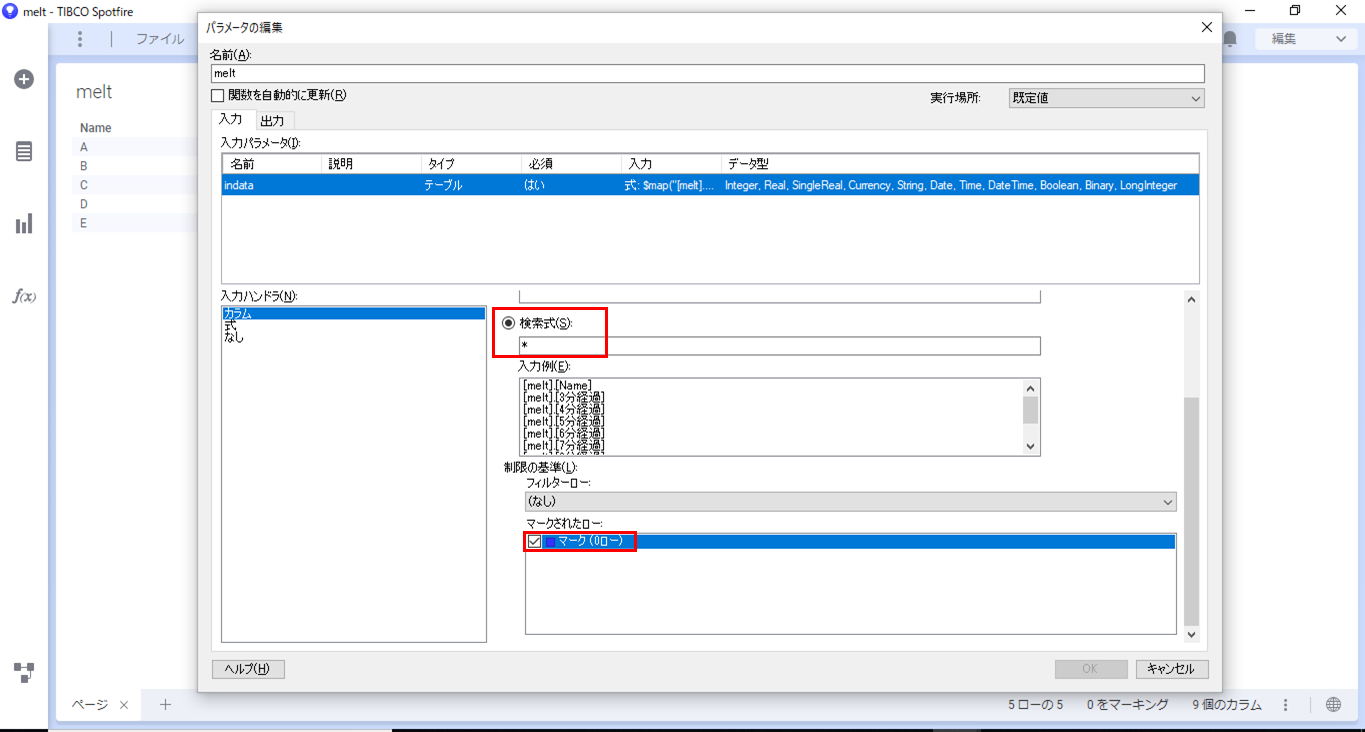
入力タブでは、実行時のパラメータとデータの割り当てを以下のように設定します。
これにより、カラムが可変になった場合でも対応でき、マークした範囲のデータを変換することができます。
出力タブでは、outdataをSpotfire側で扱う方法を以下のように設定します。
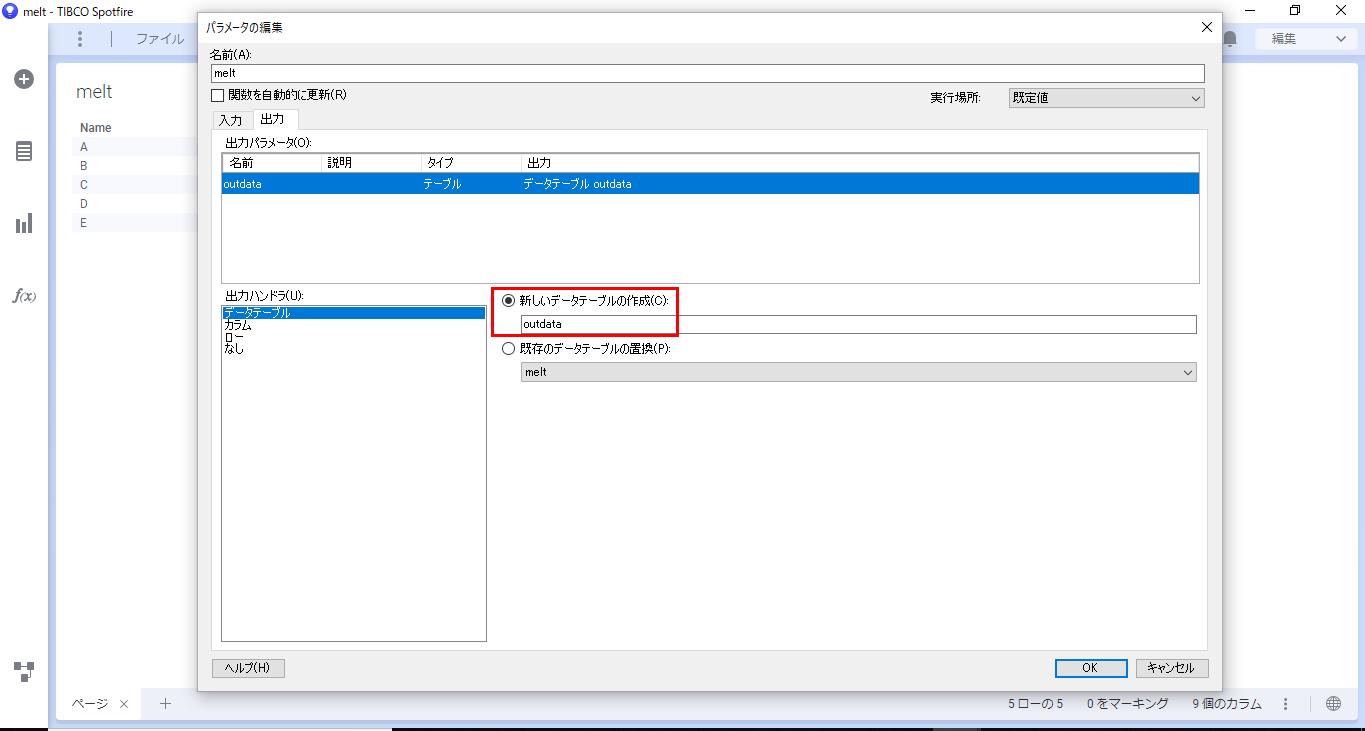
「OK」を押すと実行されます。
確認のため、indataの棒グラフとoutdataのテーブルを作成します。
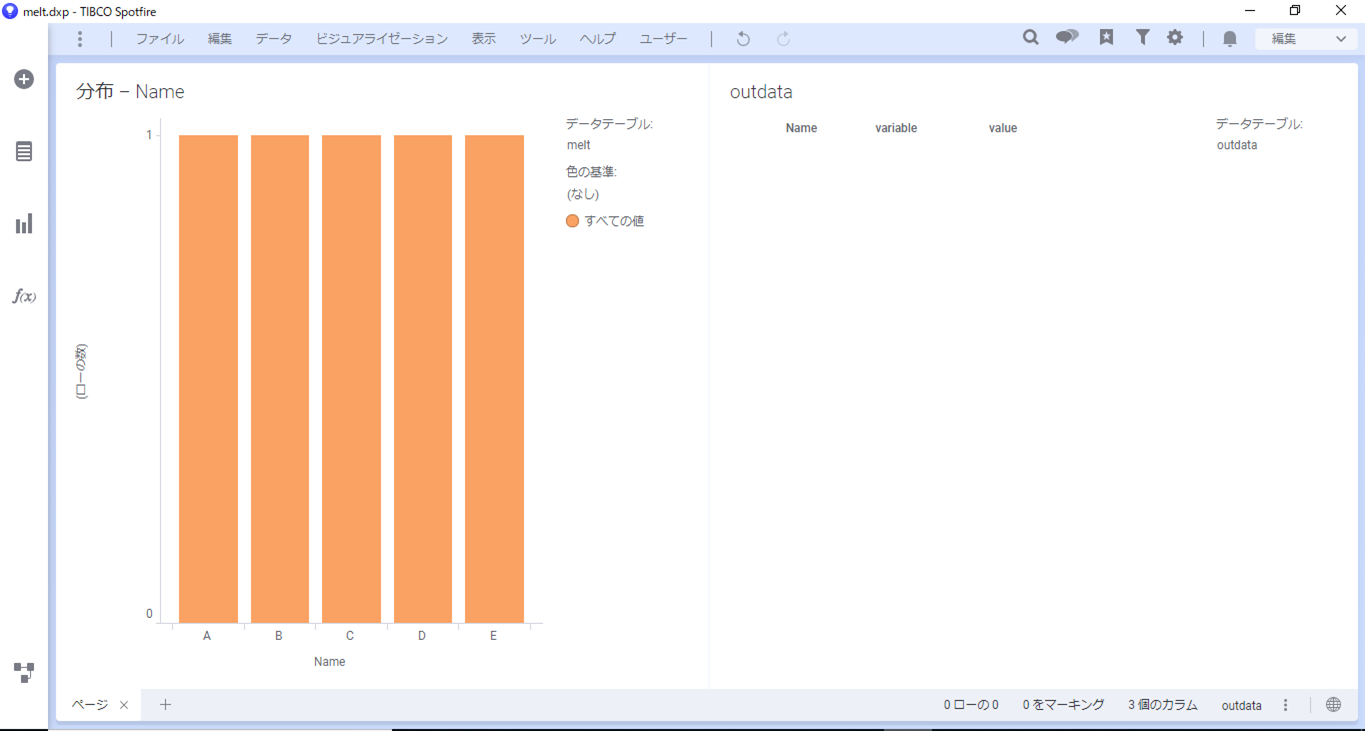
元データであるindataで作成した棒グラフのAを選択すると、outdataにはAを縦変換した8行が作成されます。
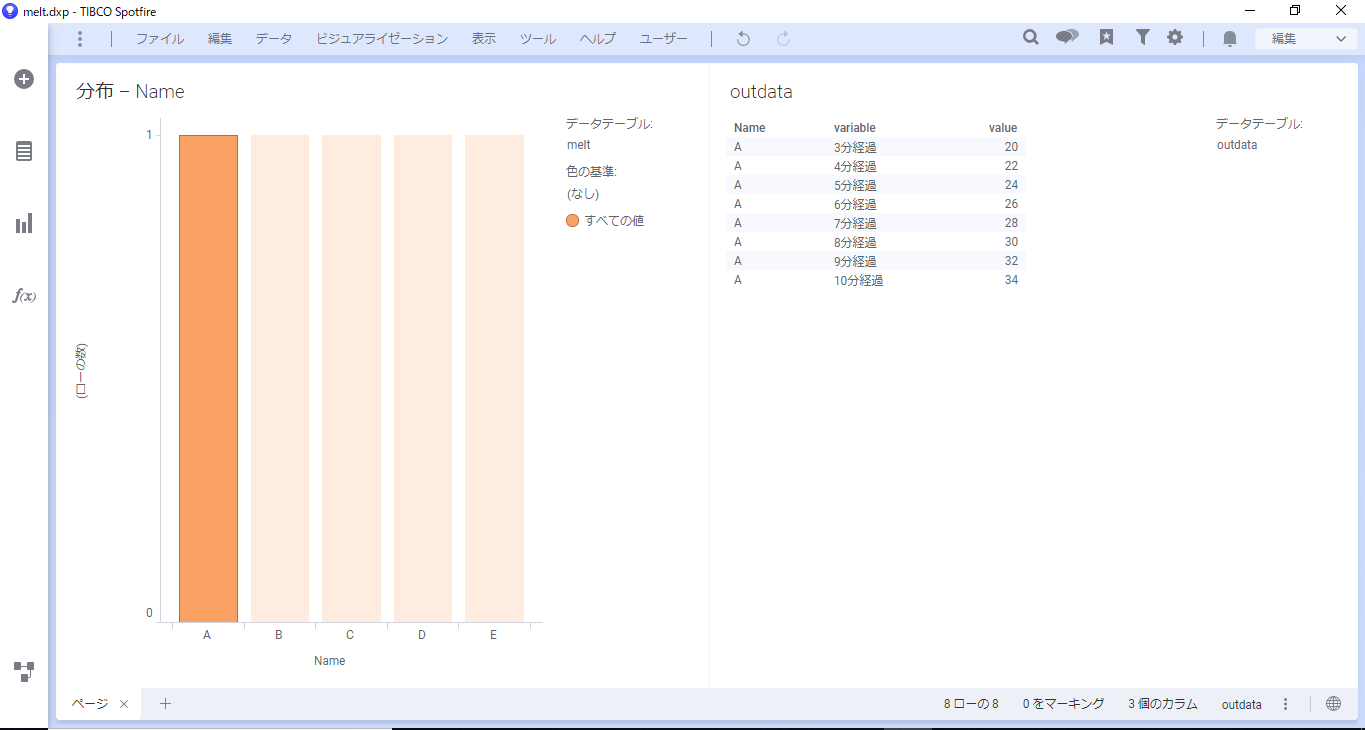
棒グラフのBを選択するとoutdataが更新されます。
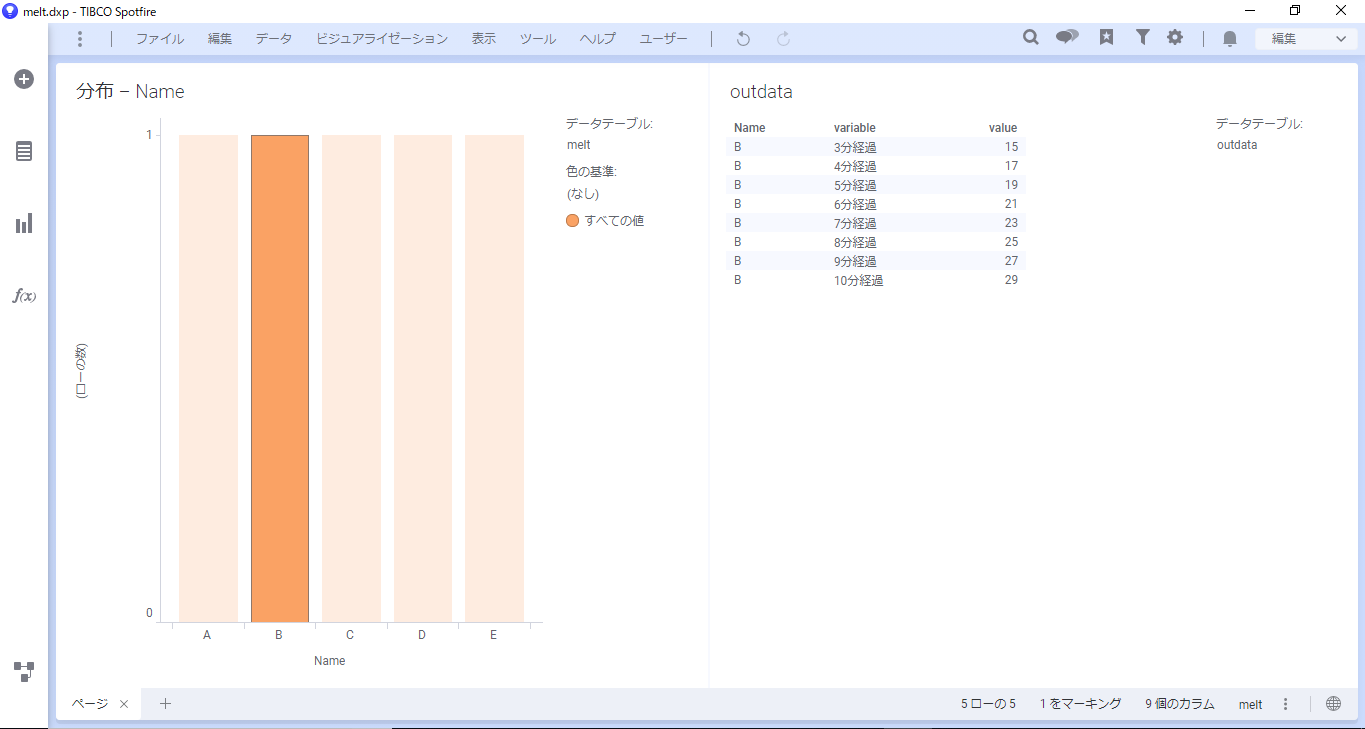
また、棒グラフの複数セグメントを選択した場合でも、適時outdataが更新されます。
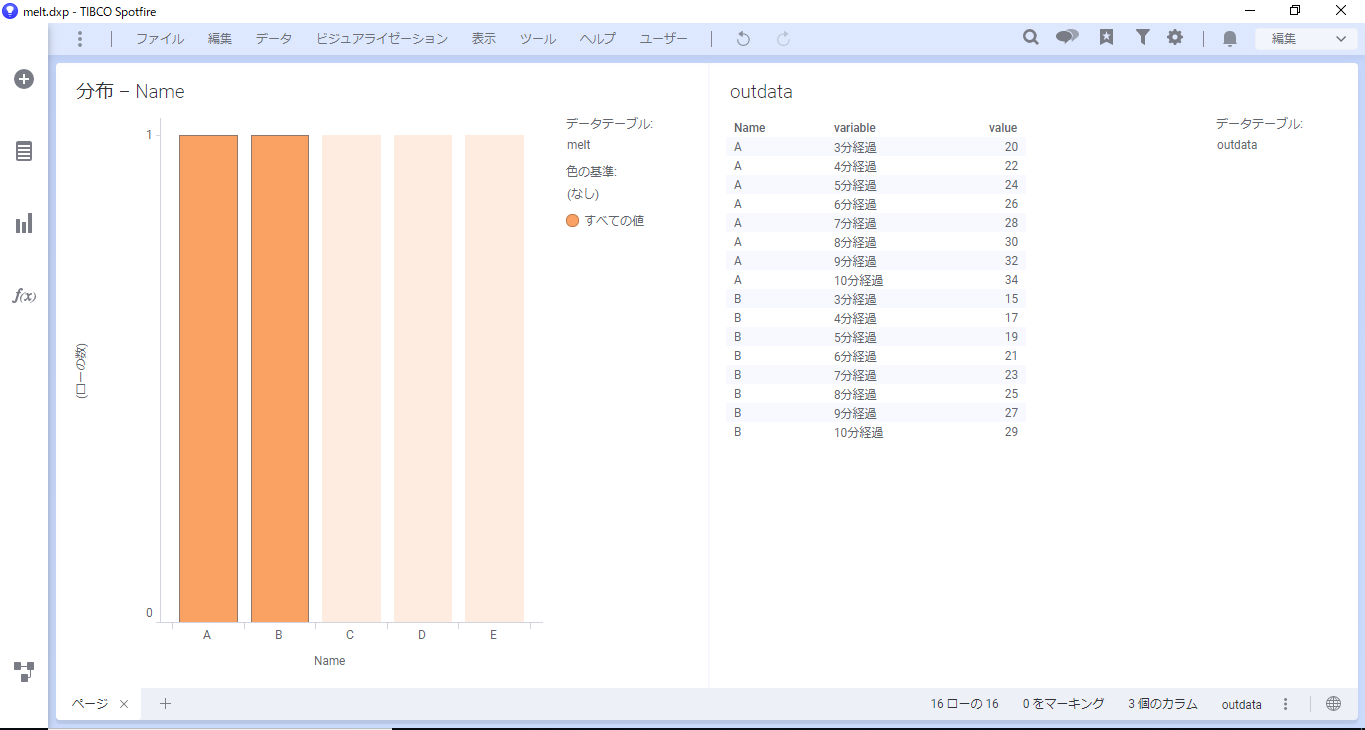
このように、必要な箇所だけ縦変換できると大量データを扱う際に便利です。
Spotfire活用セミナー
アーカイブ動画を配信中
前の記事
16進数から10進数へ変換次の記事
複数の計算カラムを一括作成【Python連携】最新の記事


import pandas as pd
import numpy as np
indata2 = indata.set_index('Name')
df = indata2.transpose().unstack(level=0)
outdata = pd.DataFrame(df).reset_index().rename(columns = {"level_0": "Name","level_1": "variable", 0: "value"})