![]()
![]()
![]()
![]()

2022/11/28
統計分析
※本記事は11/28開催セミナー「TIBCO Spotfire活用セミナー ~ 統計解析ツール - クラスタリング編 - ~」で紹介した内容です
このコンテンツでは、統計解析ツールのクラスタリングについて説明しています。
本コンテンツで利用したバージョンは、Spotfire Analyst 11.4です。ご利用環境によって、一部画面構成が異なる場合がありますので、ご了承ください。
Spotfireに標準搭載されている統計ツールは、誰でも簡単に統計的な手法を使ってデータに含まれるパターンや傾向を確認できます。
以下の統計手法が搭載されています。
本コンテンツでは、K平均法クラスタリングおよび階層的クラスタリングについて説明します。
クラスタリングとは機械学習の一種でデータ間の類似度に基づき、データをグループ分けする手法です。アルゴリズムには大きく2種類あります。
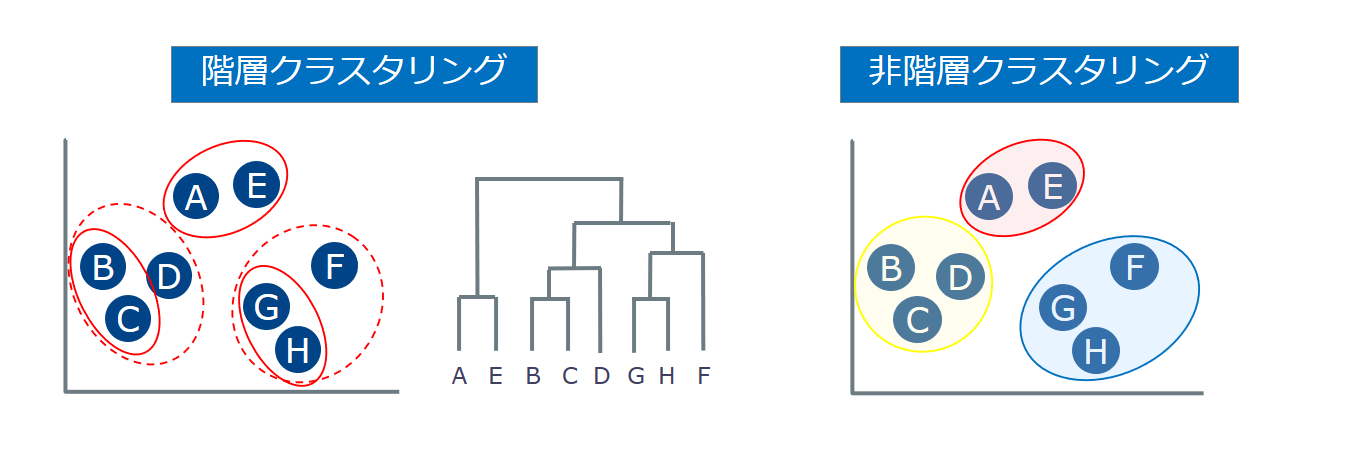
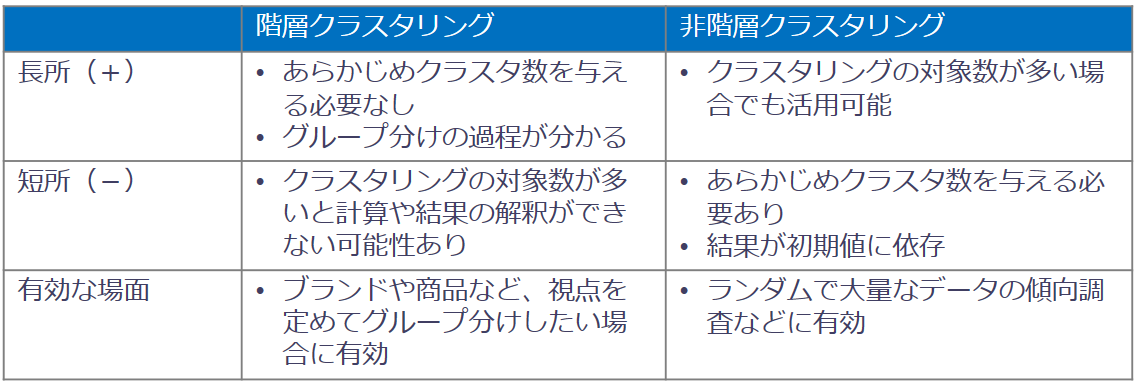
それぞれ以下の表のような特徴があります。
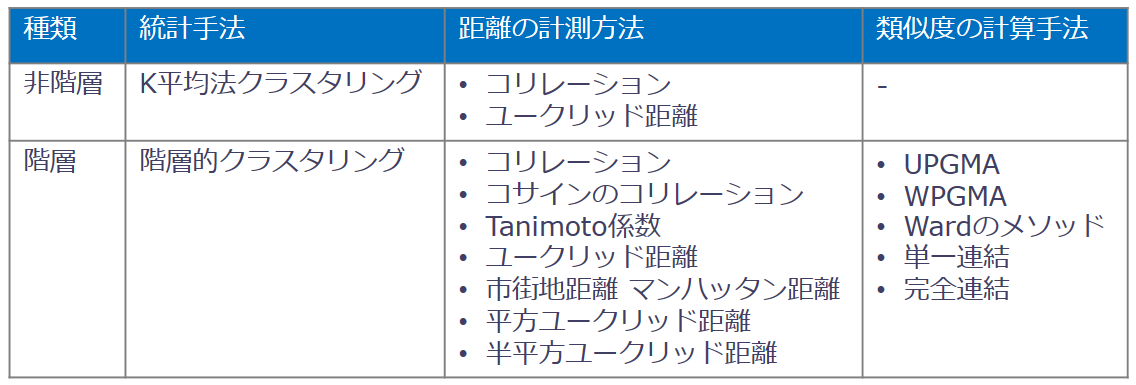
Spotfireに搭載されているクラスタリングの手法は2種類あります。
非階層クラスタリングの手法の1つで、設定した「距離の計測方法」を元に、事前に決めたK個のグループにデータを分割します。
以下の手順でクラスタリングが行われます。
※Spotfireでは、距離の計測方法は「ユークリッド距離」「コリレーション」のいずれかを設定できます。
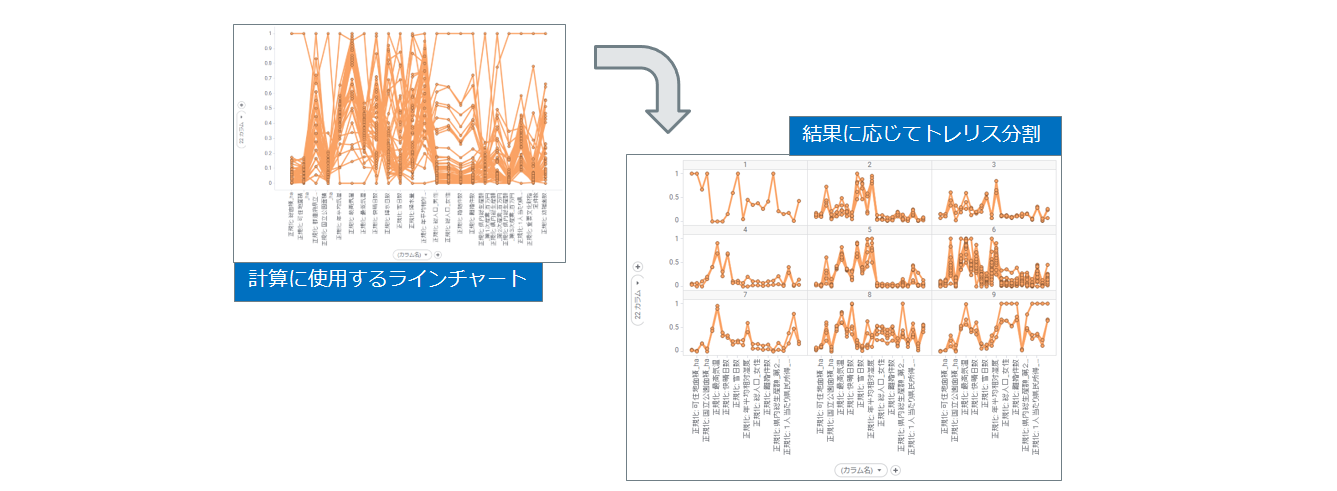
Spotfireではラインチャートを使って波形をグルーピングします。
分類には2つのパターンがあります。
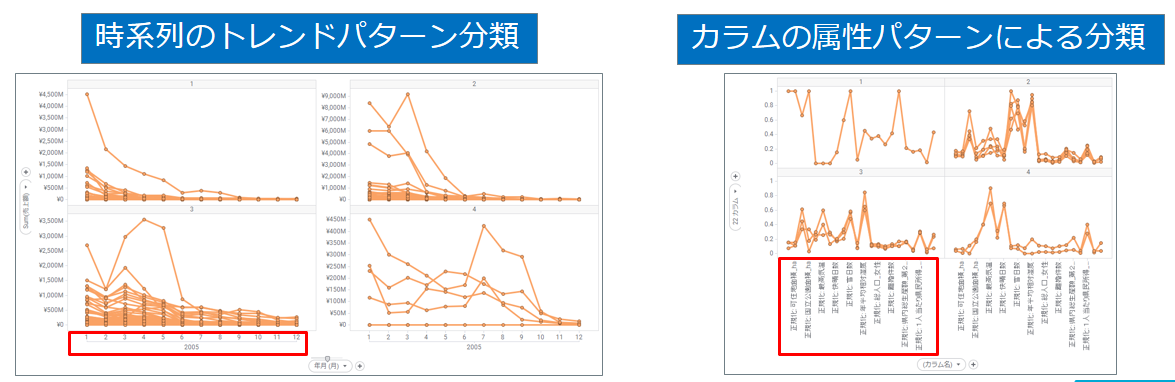
グルーピングを示す「カラム」が追加されると共に、ラインチャートが結果に応じてトレリス分けされます。
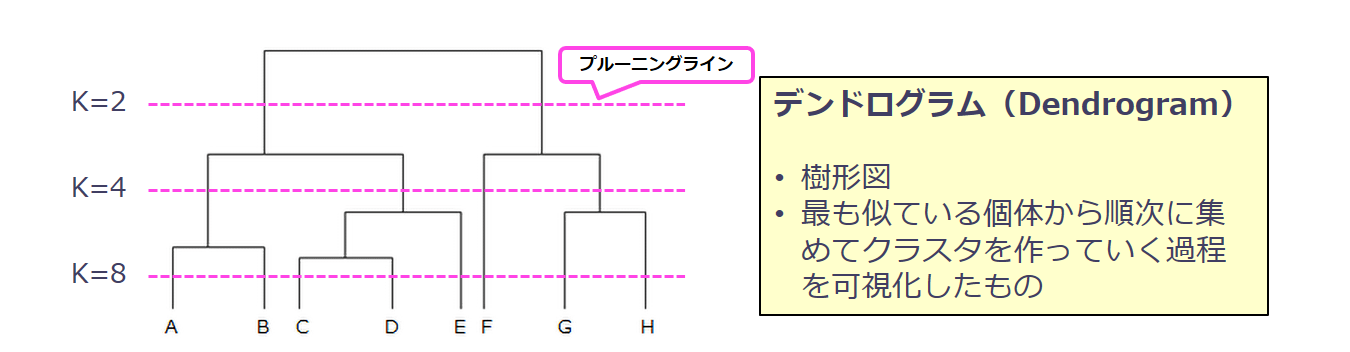
設定した計算方法に基づいてデータを階層化する方法です。計算結果は、階層のツリー構造(デンドログラム)として表示されます。
デンドログラムに表示されるプルーニングライン(類似度に対応した線)を移動させることで、データをグループ分けできます。
階層的クラスタリングの「階層化処理」は以下の手順で行われます。
階層的クラスタリングを実行すると、結果が「ヒートマップ+デンドログラム」として表示されます。
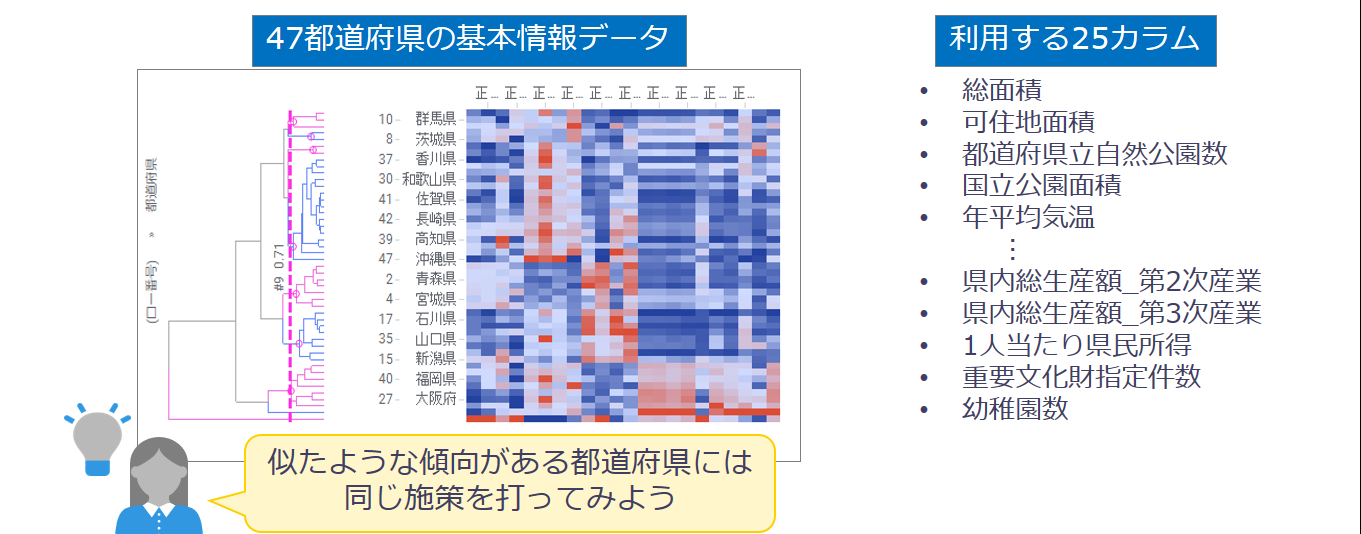
本コンテンツでは2種類のクラスタリングのうち、階層的クラスタリングを行います。
47都道府県の基本情報データを用いて、都道府県を複数の属性カラムによってグループ分けします。
※K平均法クラスタリングの実行方法についてはこちらをご覧ください。
本コンテンツで使用するデータはこちらからダウンロードしてください。
1行1都道府県のデータになります。
都道府県データ.csvを選択し、「インポートの設定」ダイアログで「OK」を選択します。
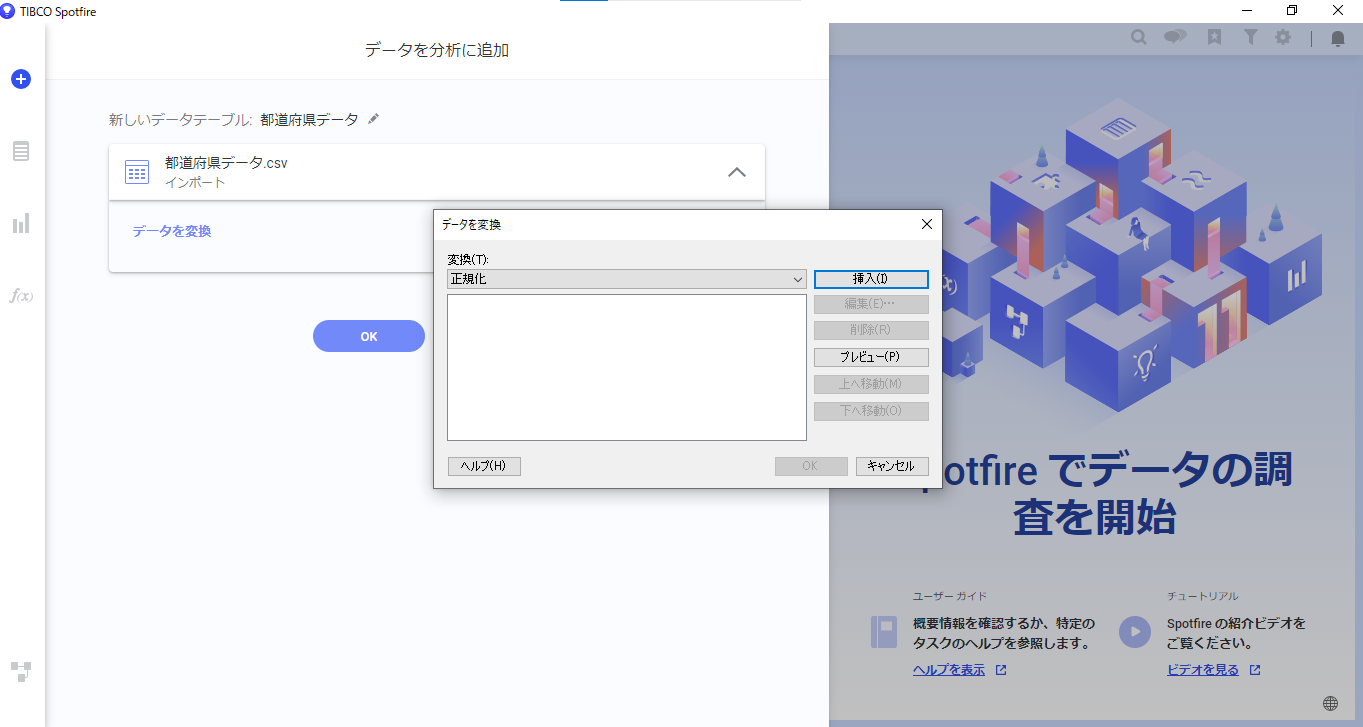
「データを分析に追加」画面でデータを変換をクリックし、正規化を選択します。「挿入」をクリックすると、「正規化」ダイアログが表示されます。
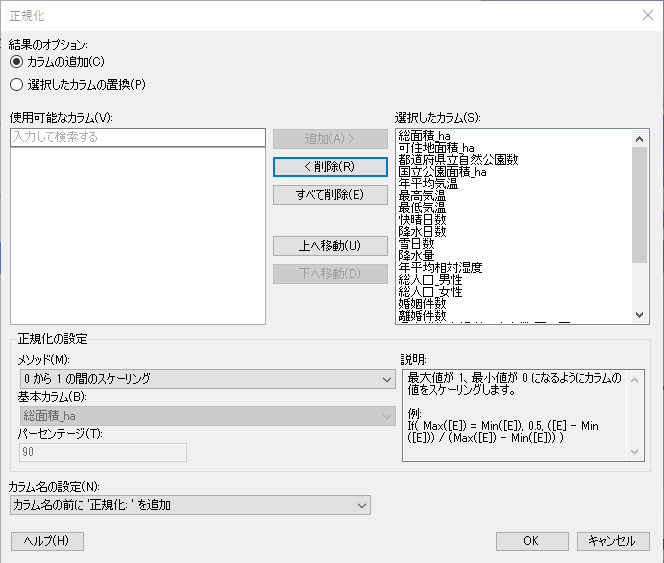
「正規化」ダイアログで、以下を設定します。設定ができたら「OK」を選択してデータを取り込みます。
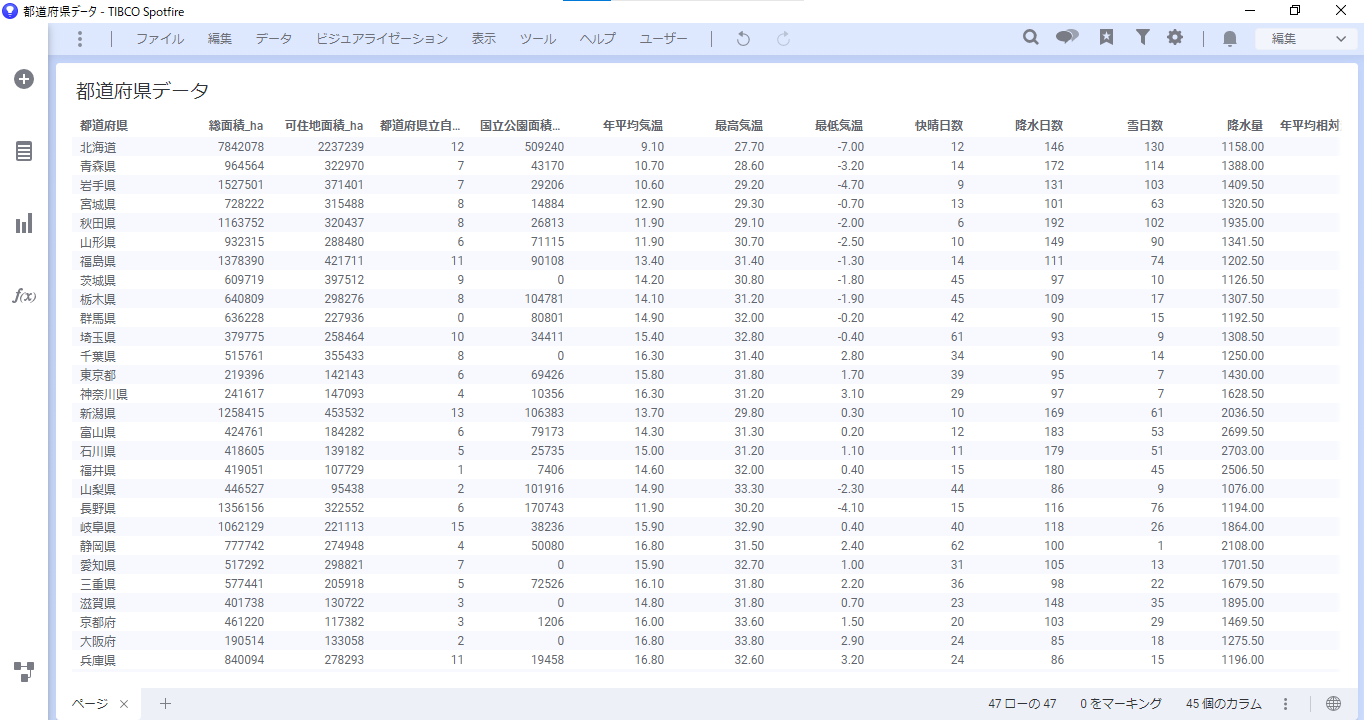
テーブルを表示してデータを確認します。元のテーブルに正規化されたカラムが追加されていることが分かります。
階層的クラスタリングを実行します。
新規ページを追加して、メニューバー「ツール」>「階層的クラスタリング」を選択します。
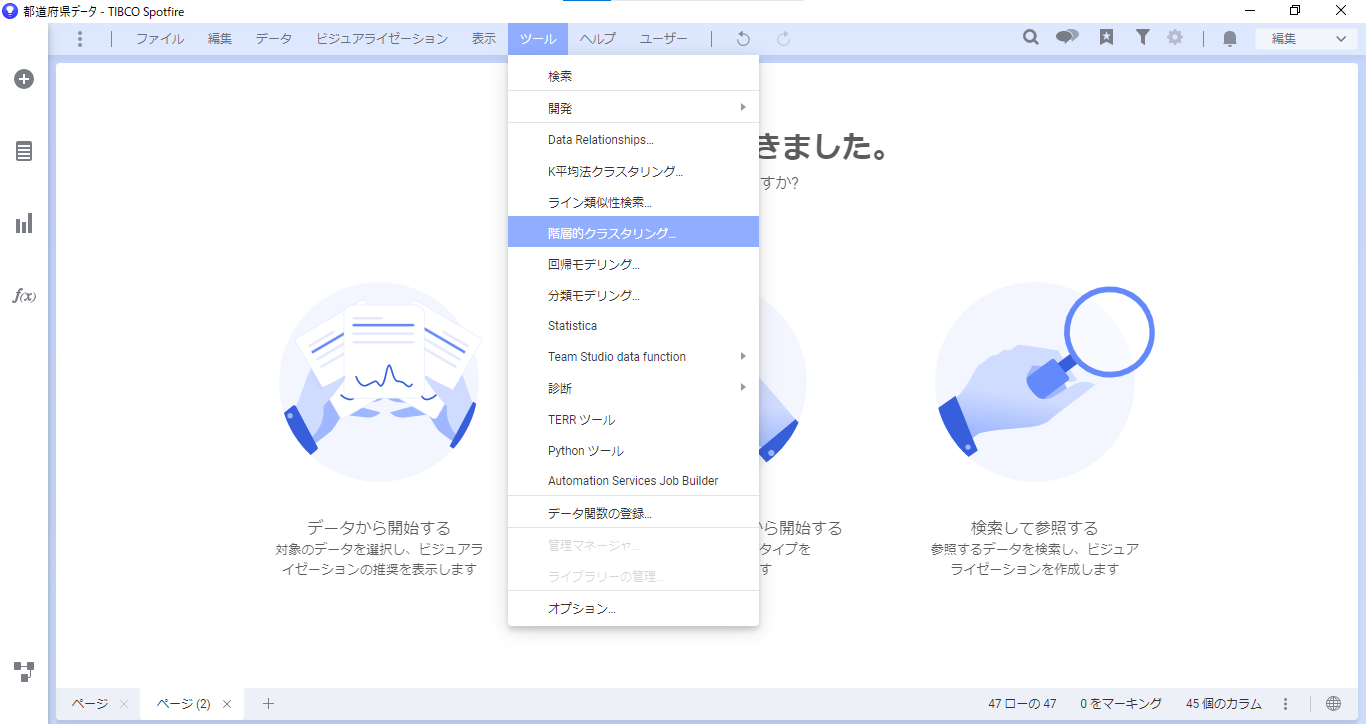
「階層的クラスタリング」の設定画面では、カラムの選択やクラスタリング設定の編集ができます。
まずカラムの設定を行います。「カラムの選択」をクリックします。
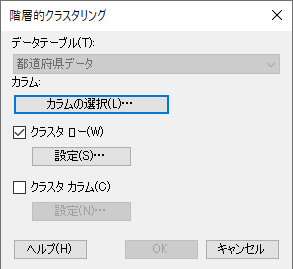
カラムは以下を設定します。設定できたら「OK」を押します。
すると「階層的クラスタリング」の設定画面に戻ります。
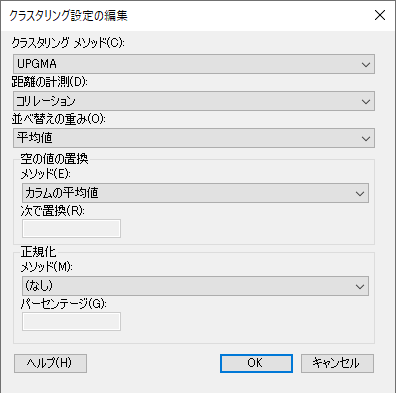
次にクラスタローの「設定」をクリックします。「クラスタリング設定の編集」画面が表示されます。
「クラスタリング設定の編集」画面で以下を設定します。設定ができたら「OK」を押します。「階層的クラスタリング」設定画面に戻るため、再度「OK」を押して設定を完了します。
設定が完了すると、デンドログラムとヒートマップが表示されます。
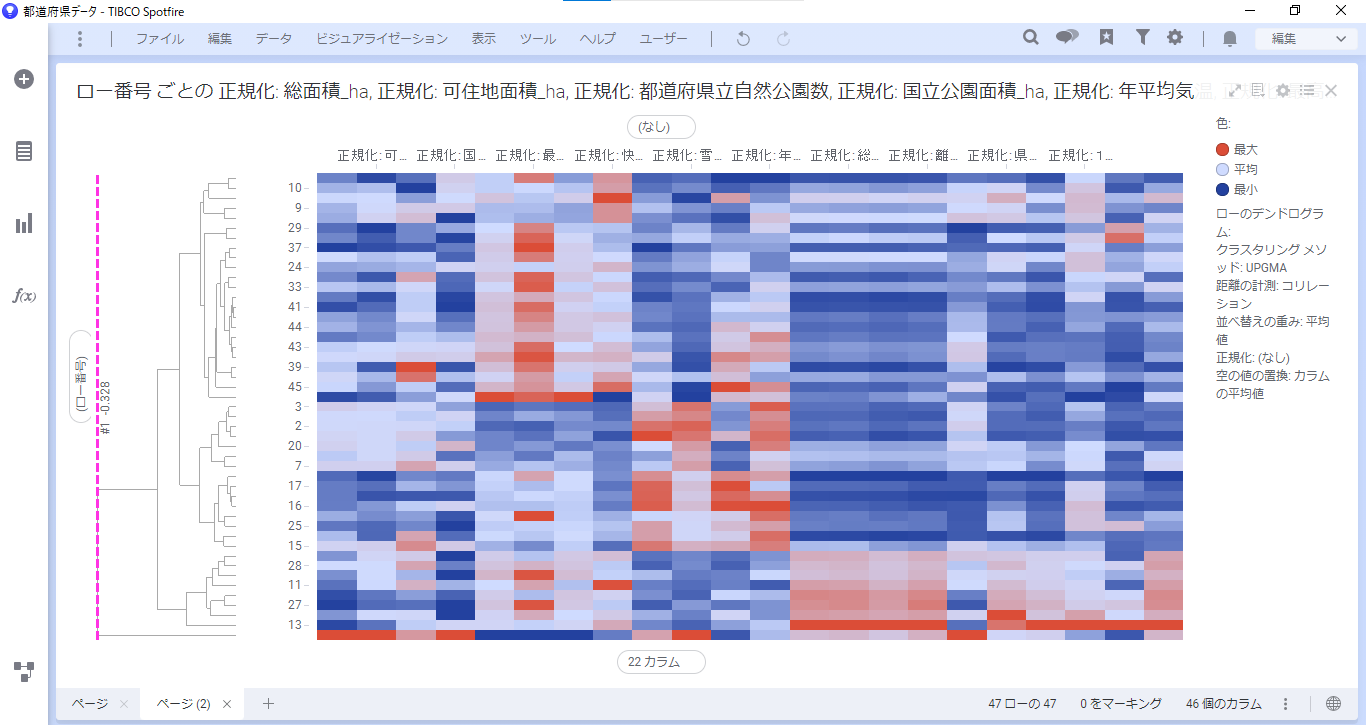
また、階層的クラスタリングを実行すると、「ローのクラスタID」というカラムが新たに追加されます。
テーブルで「ローのクラスタID」カラムが追加されていることを確認できます。
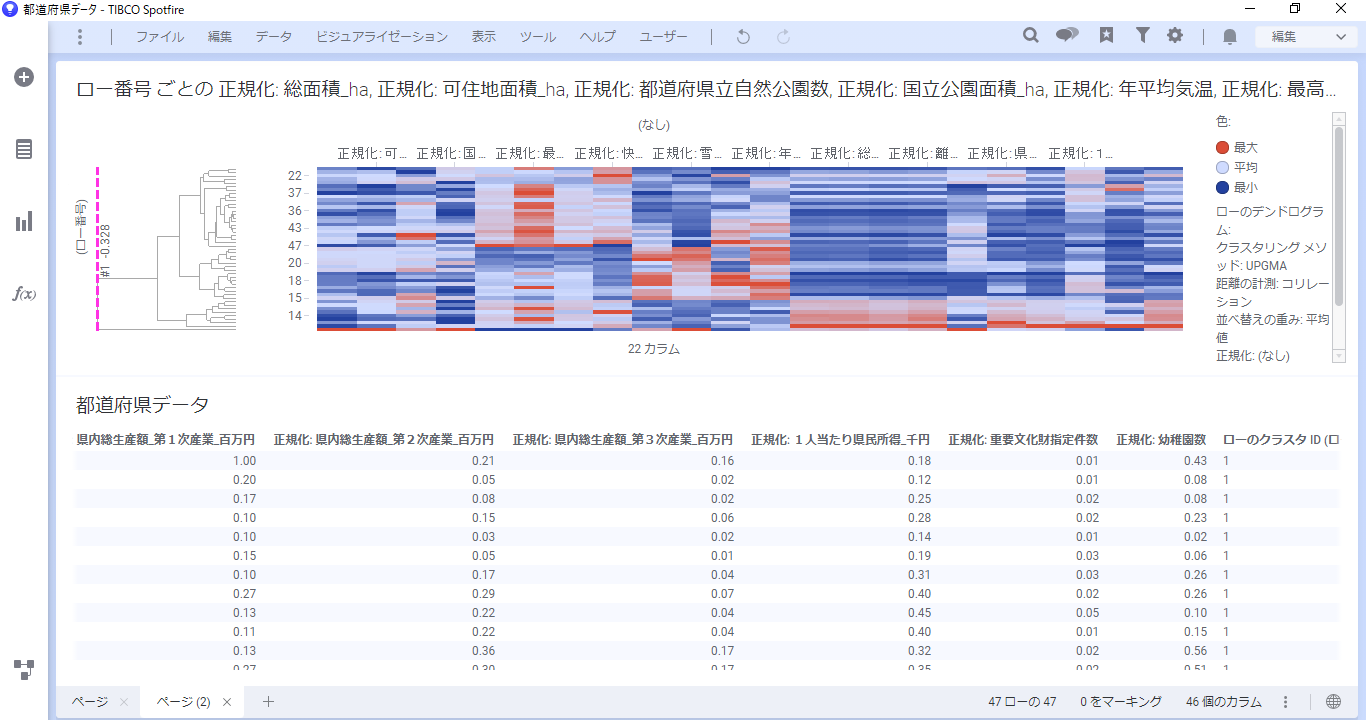
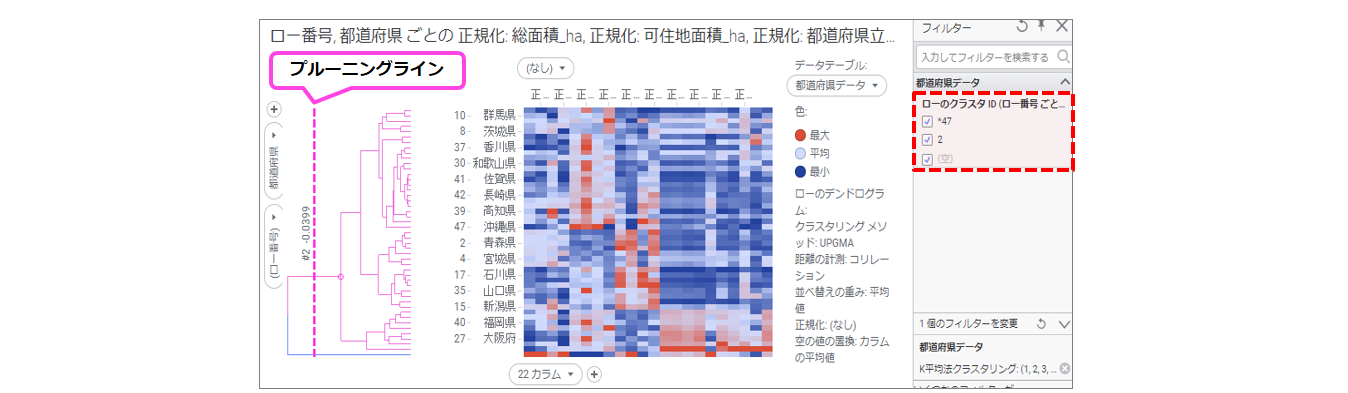
カラムの追加を確認後、テーブルを削除し、デンドログラム上の「プルーニングライン」を変更します。
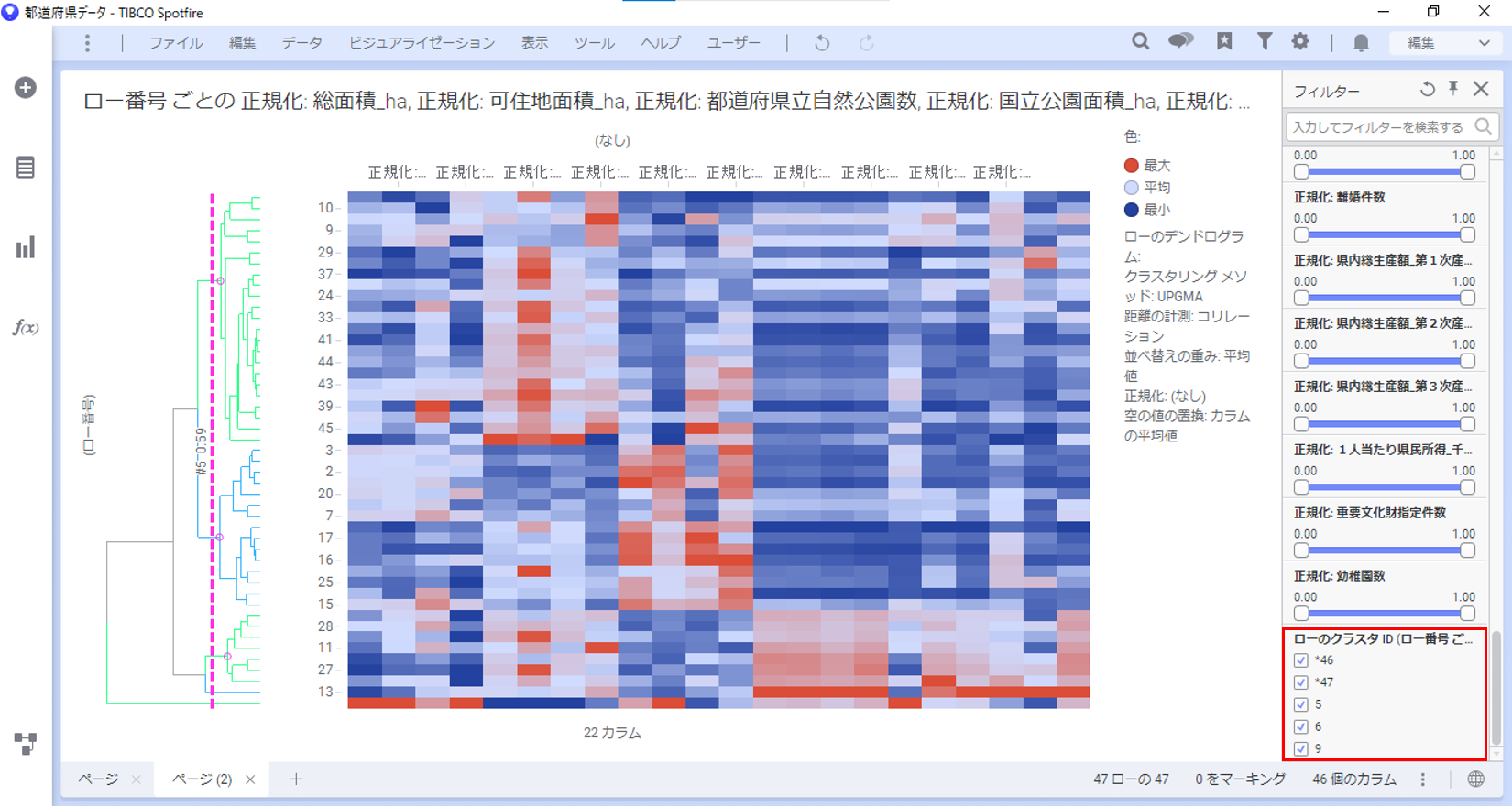
「プルーニングライン」はドラッグ&ドロップで操作できます。右に移動させると、クラスタ数の変化に応じて「ローのクラスタID」カラムの固有値が増加します(下図ではフィルターパネルにて確認)。
※下図はプルーニングラインが#5になっているため、都道府県を5つにグルーピングしています。
ビジュアライゼーションを見やすくするため、調整します。
まず、ヒートマップのY軸に「ロー番号」の表示しかないため、都道府県名を表示させます。
Y軸に「都道府県」を追加します。追加すると、デンドログラムが表示されなくなります。
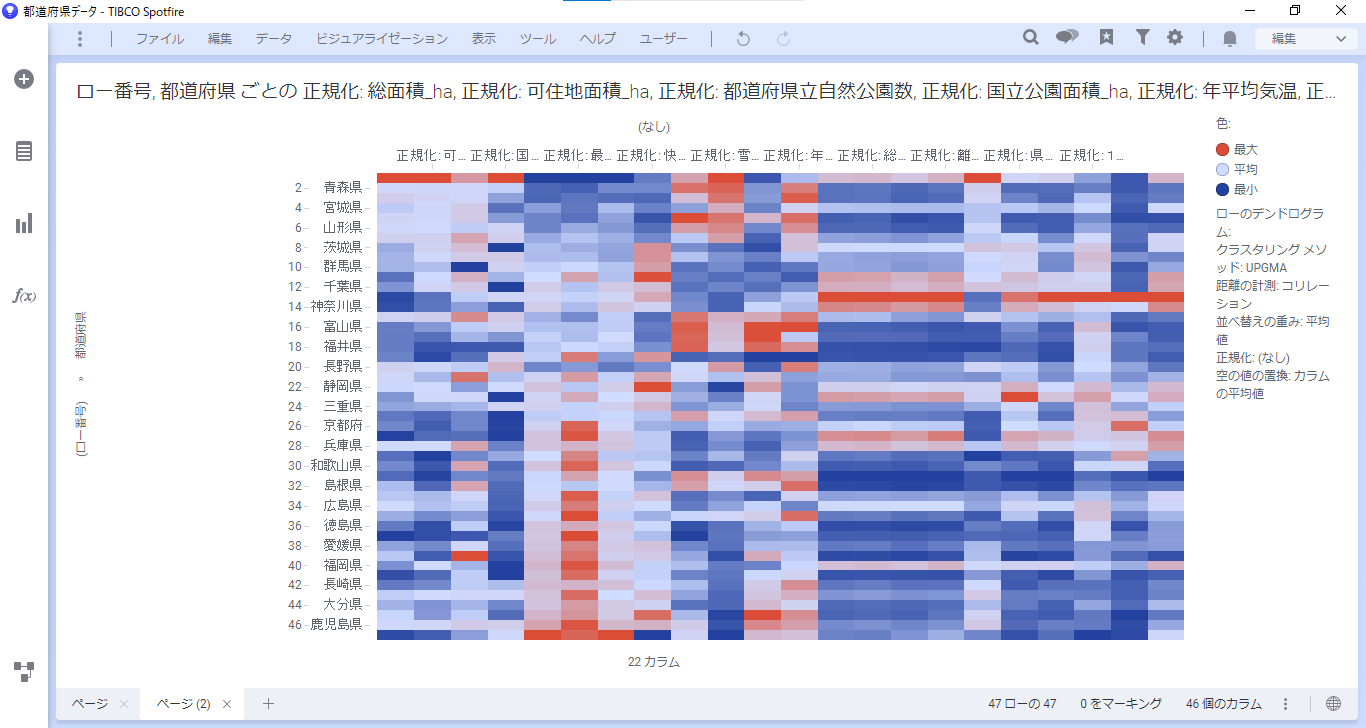
デンドログラムを再表示させるため、プロパティ>デンドログラムで「設定」の「更新」をクリックします。
するとデンドログラムが再表示されました。これで調整は完了です。
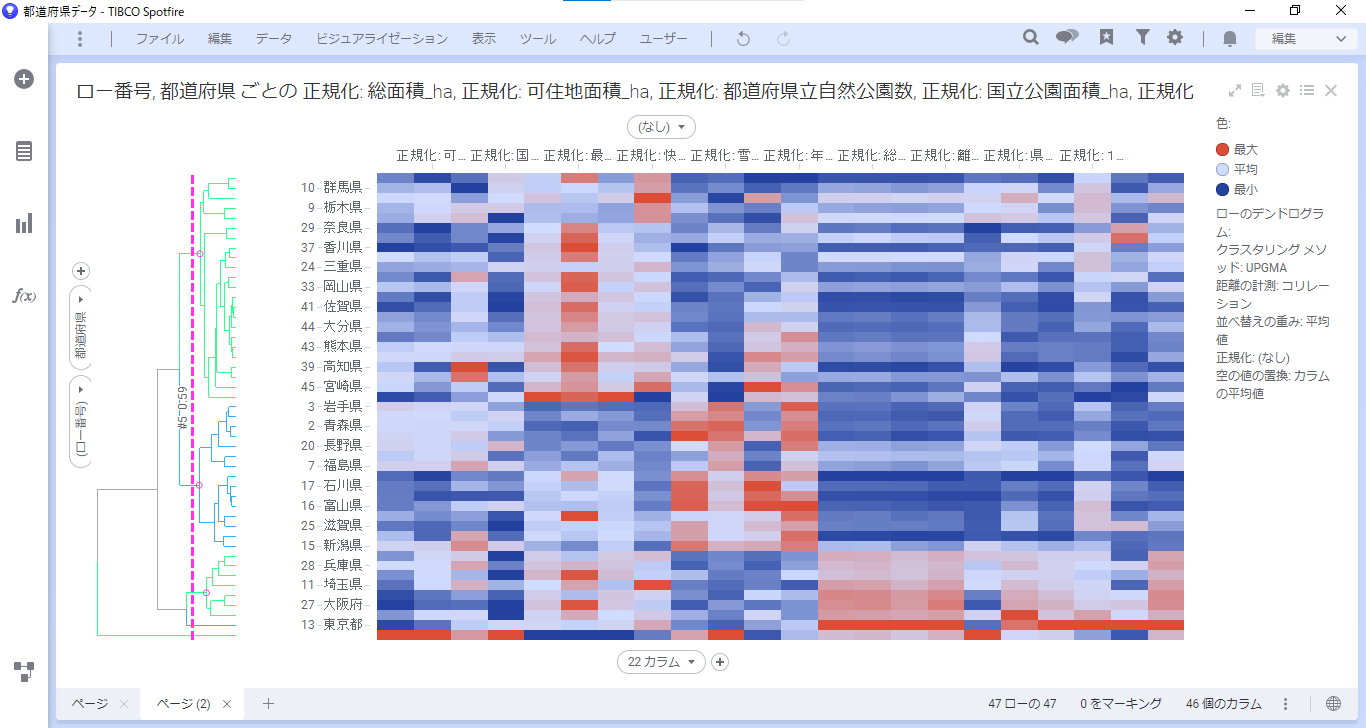
以上のように、クラスタリング機能を用いることで簡単にデータをグルーピングできます。
Spotfire活用セミナー
アーカイブ動画を配信中
次の記事
回帰モデリングの使い方【統計分析】最新の記事

