![]()
![]()
![]()
![]()

2022/09/30
統計分析
※本記事は9/30開催セミナー「TIBCO Spotfire活用セミナー ~ 統計解析ツール -Data Relationships編- ~」で紹介した内容です
このコンテンツでは、Data Relationshipsについて説明しています。
本コンテンツで利用したバージョンは、Spotfire Analyst 11.4です。ご利用環境によって、一部画面構成が異なる場合がありますので、ご了承ください。

Spotfireに標準搭載されている統計ツールは、誰でも簡単に統計的な手法を使ってデータに含まれるパターンや傾向を確認できます。
以下の統計手法が搭載されています。
「Data Relationships」は変数(カラム)間の関連性を簡単に把握できる機能です。
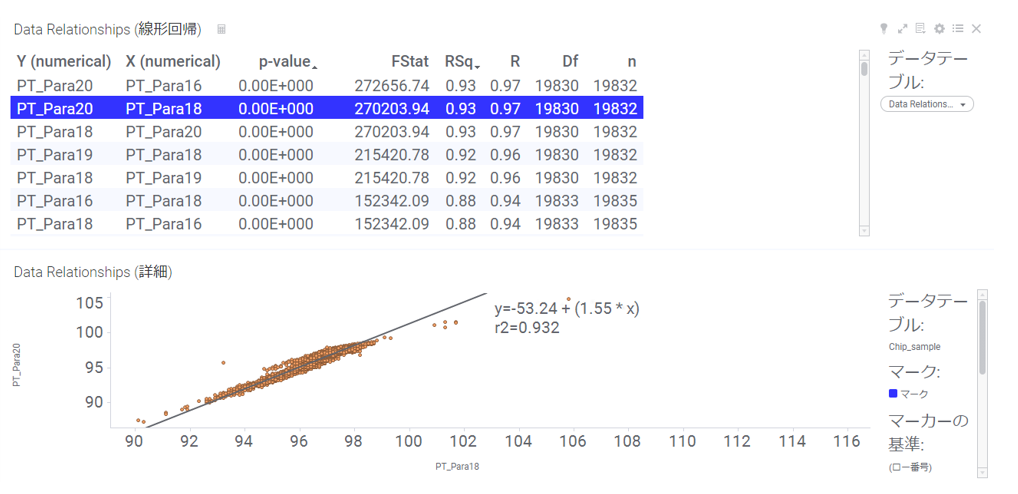
例えば、関連性を見たい変数が多い際に、Data Relationshipsを利用することでスピーディーに結果を把握できます。
Data Relationshipsのアルゴリズムは5種類あり、下表のようにカラムタイプとデータの分布によって使い分けます。

【補足】
パラメトリック/ノンパラメトリックは統計的検定の手法です。母集団のデータの分布によって使い分けます。
参考として、データの分布が正規分布に従っているか調べる方法は正規性確率プロットをご参照ください。
5種類の中でもよく使う3つのアルゴリズムについて簡単に説明します。
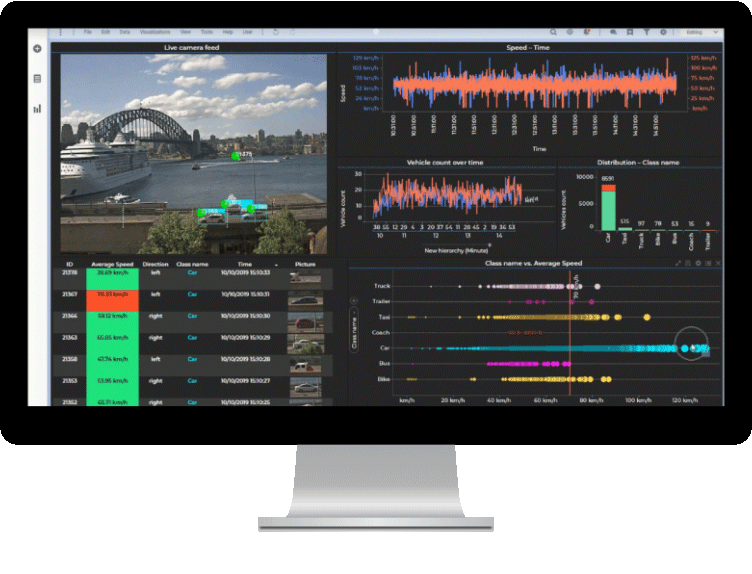
Data Relationshipsの計算結果は、計算結果データテーブルとビジュアライゼーションで自動的に表示されます。計算結果データテーブルをマークすると、マークした変数(カラム)の組み合わせでのビジュアライゼーションを確認できます。
※下図は線形回帰の例です。
計算結果データテーブルは、P値の小さい順に自動ソートされます。
一般的にはP値が0.05未満であれば、変数間には関連性があると判断します。
本コンテンツでは半導体のデータにおいて、ANOVA(分散分析)を用いてICチップの品質情報とパラメータの関係性を見ていきます。
本コンテンツで使用するデータはこちらからダウンロードしてください。
1行につき1つのICチップのデータになっています。
Chip_sample.csvを読み込みます。Spotfire画面左側の+ボタンから「ローカルファイルを参照」し、Chip_sample.csvを選択します。
データの中身を確認するため、テーブルを表示します。「ビジュアライゼーションタイプ」から「テーブル」を選択します。
1行につき、1つのICチップのデータです。
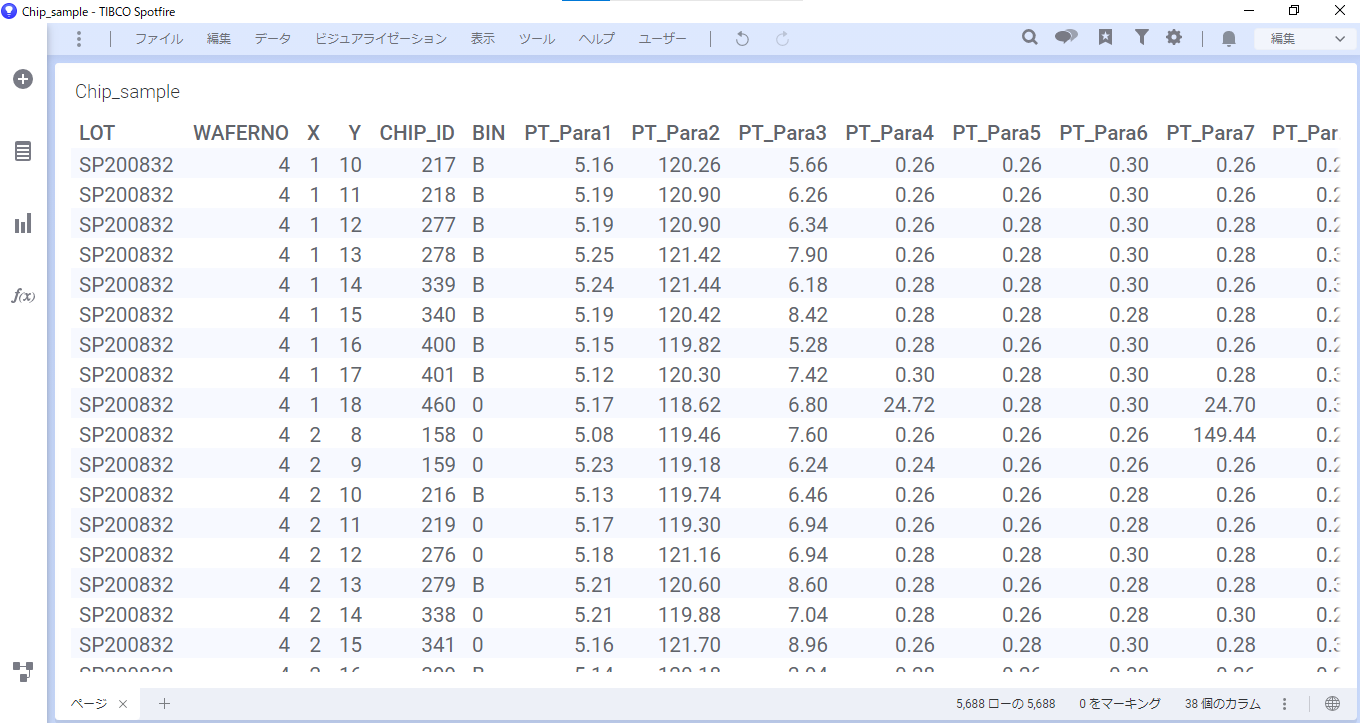
メニューバー「ツール」> 「Data Relationships」を選択します。
すると、「Data Relationships」ダイアログが表示されます。
今回はANOVAを選択して、BIN(品質情報)によって、値に差が出るパラメータを見つけ出します。
設定ができたら「OK」を押します。
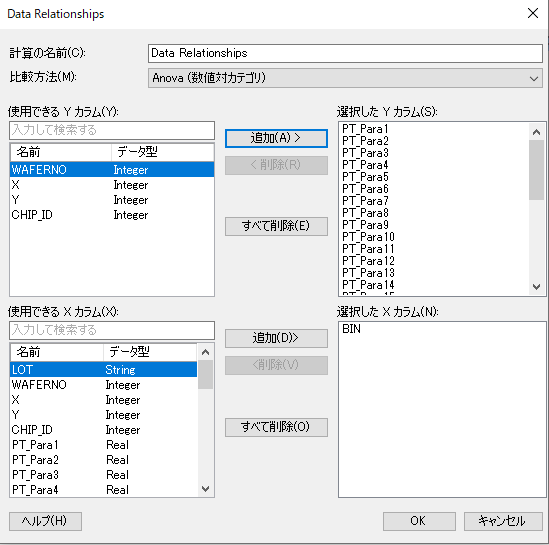
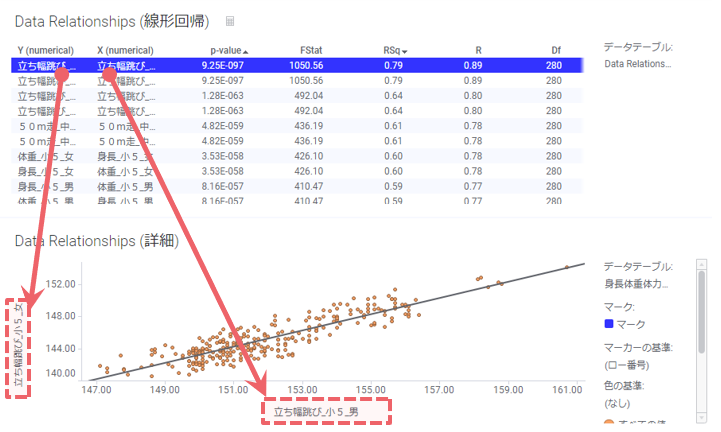
すると、計算結果データテーブルとBox Plotが表示されます。今回はP値0.05を基準に関連性を見ていきます。多くのパラメータのP値が0に近い値です。
今回は有意になったパラメータの中で、PT_Para31を確認します。Box Plotで確認をすると、不良カテゴリAは他のカテゴリに比べてパラメータの値が高いことが分かります。
このことから、知見を基にPT_Para31が関係している製造プロセスや装置を見直すといったアクションや、次の分析に繋げられます。
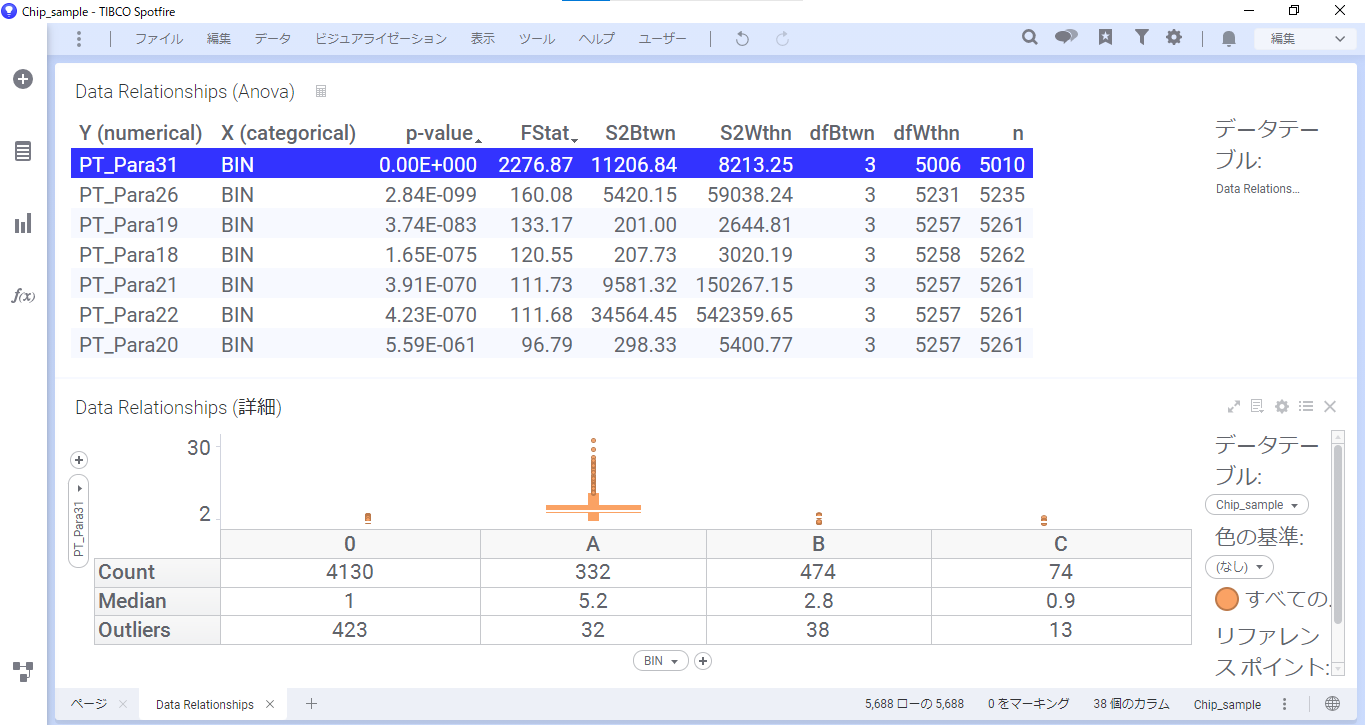
Data Relationshipsの計算は、フィルターで絞り込まれたデータを使って行われます。
試しに、WAFER番号を絞り込んでフィルターをかけます。
すると、計算結果テーブルのタイトルバーに更新アイコンが表示されます。このアイコンをクリックします。
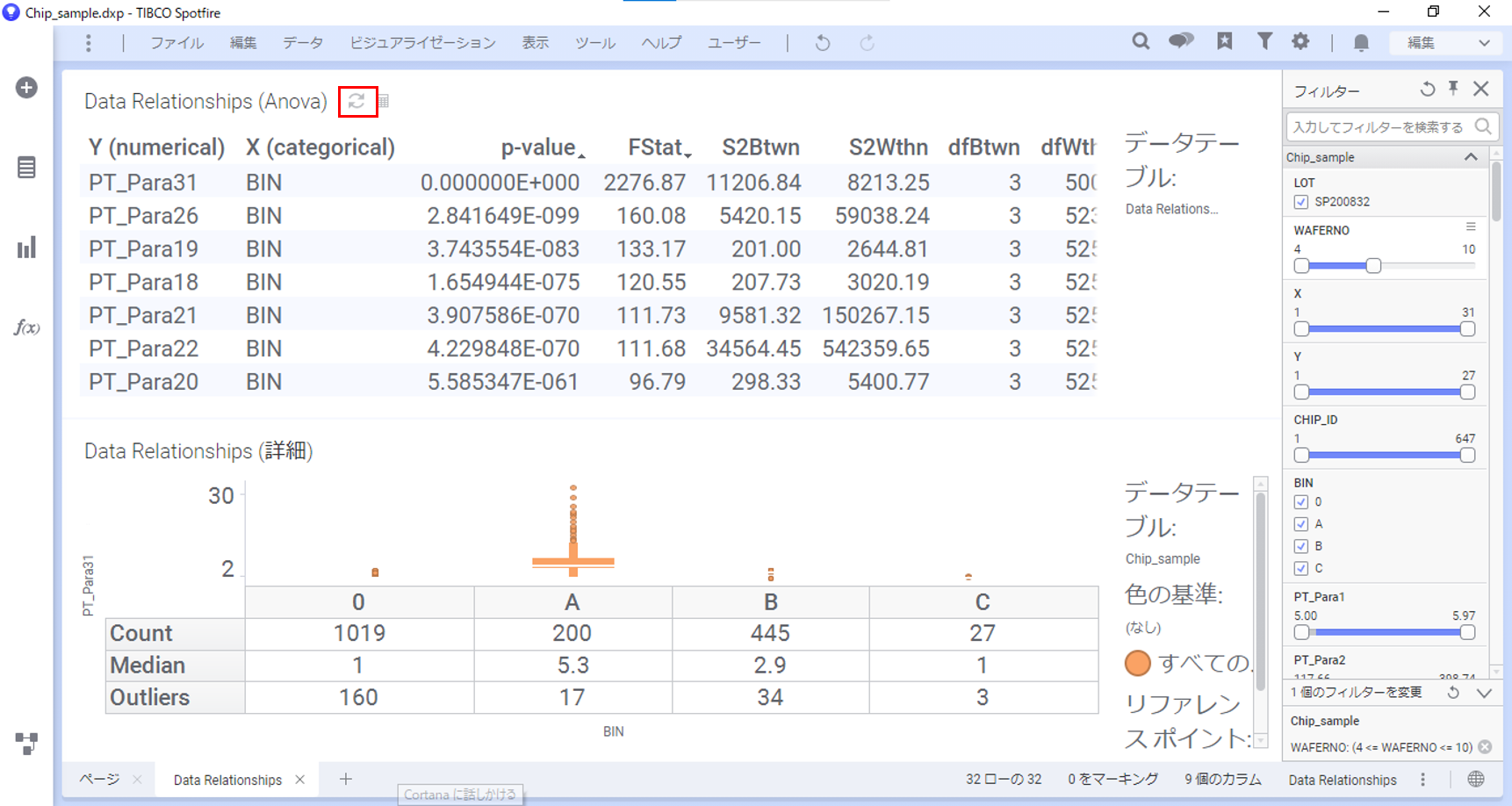
すると、現在のフィルター設定に応じて再計算されます。再計算されたことにより、結果が変わっていることが確認できます。
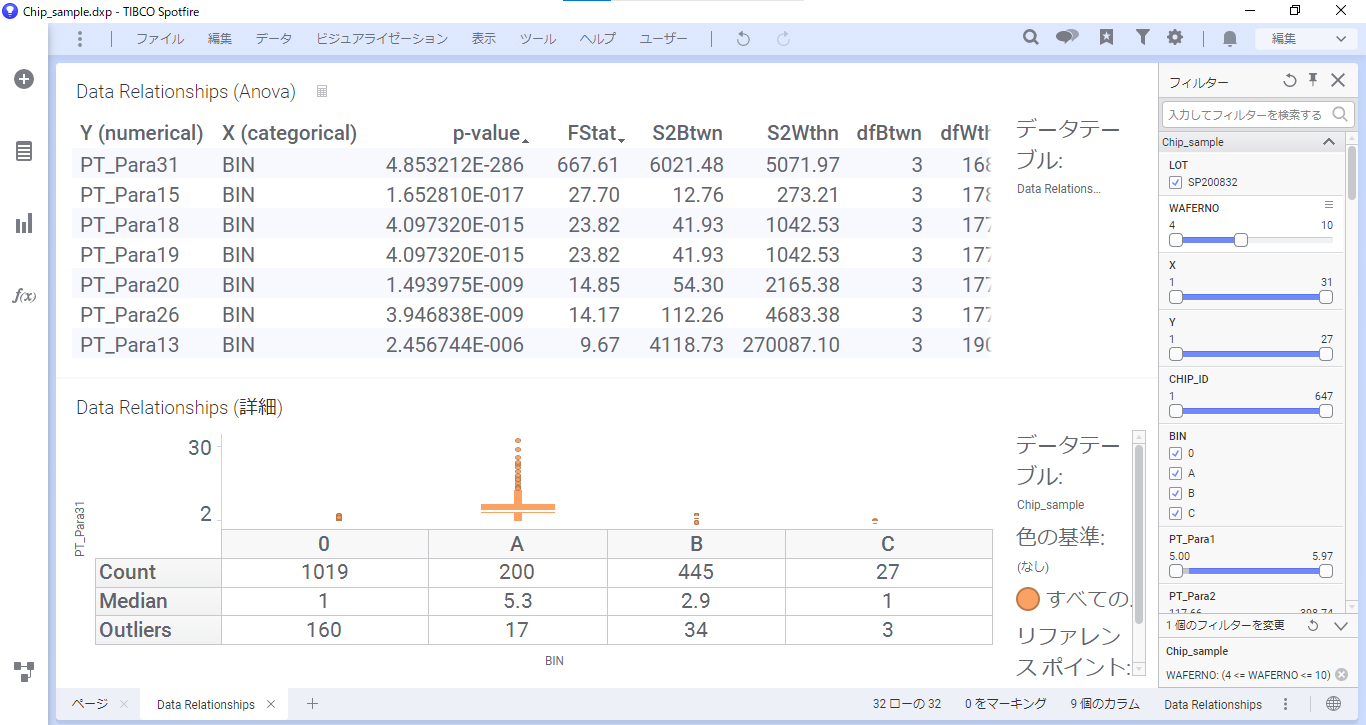
補足として、「Data Relationships」を用いた計算結果データテーブルのP値はデフォルトでは指数表記になっています。指数表記を小数に直したい場合、「分析内のデータ」フライアウトで設定をします。
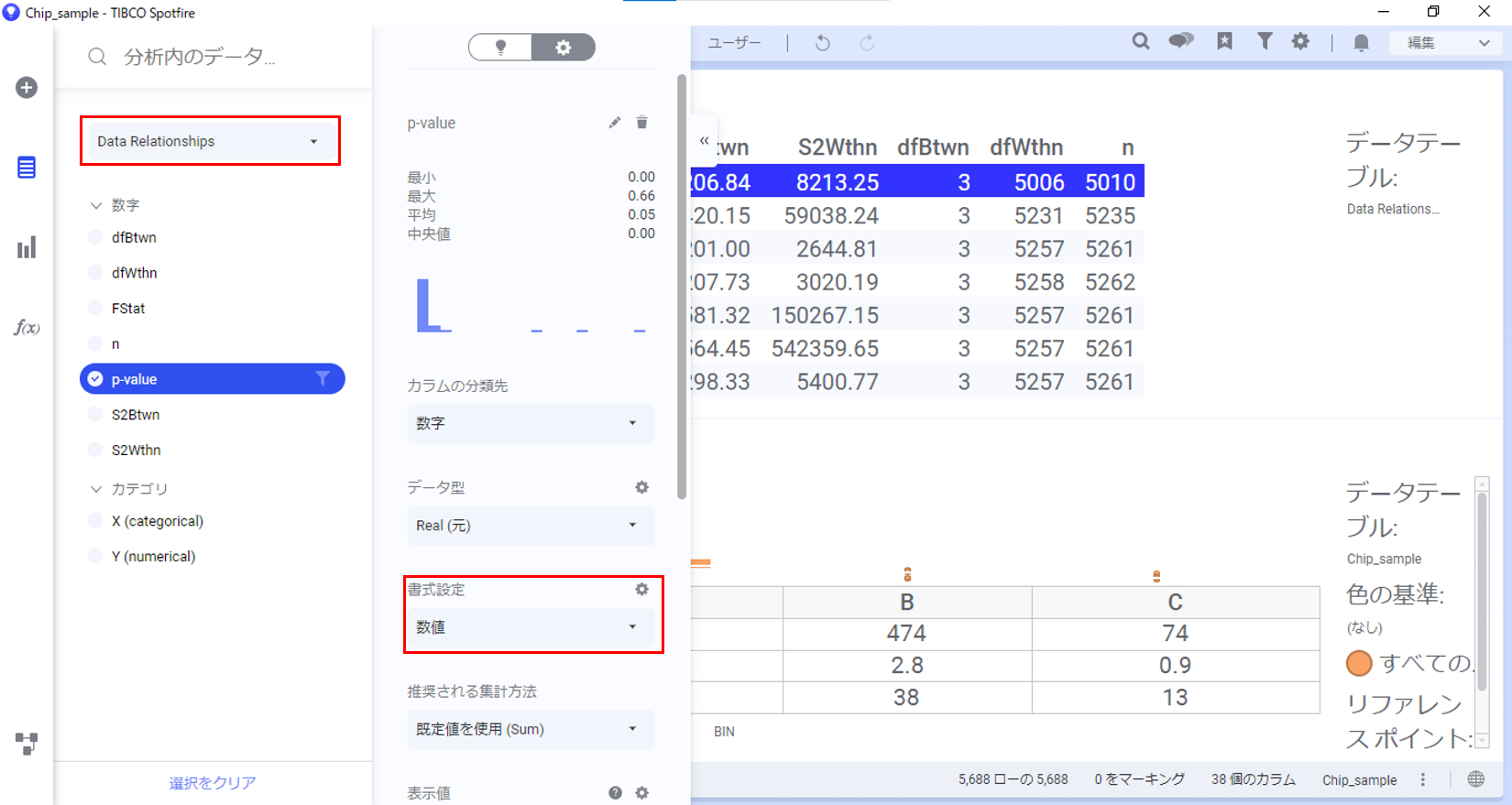
すると、P値が小数表記になり、大きさが分かりやすくなりました。
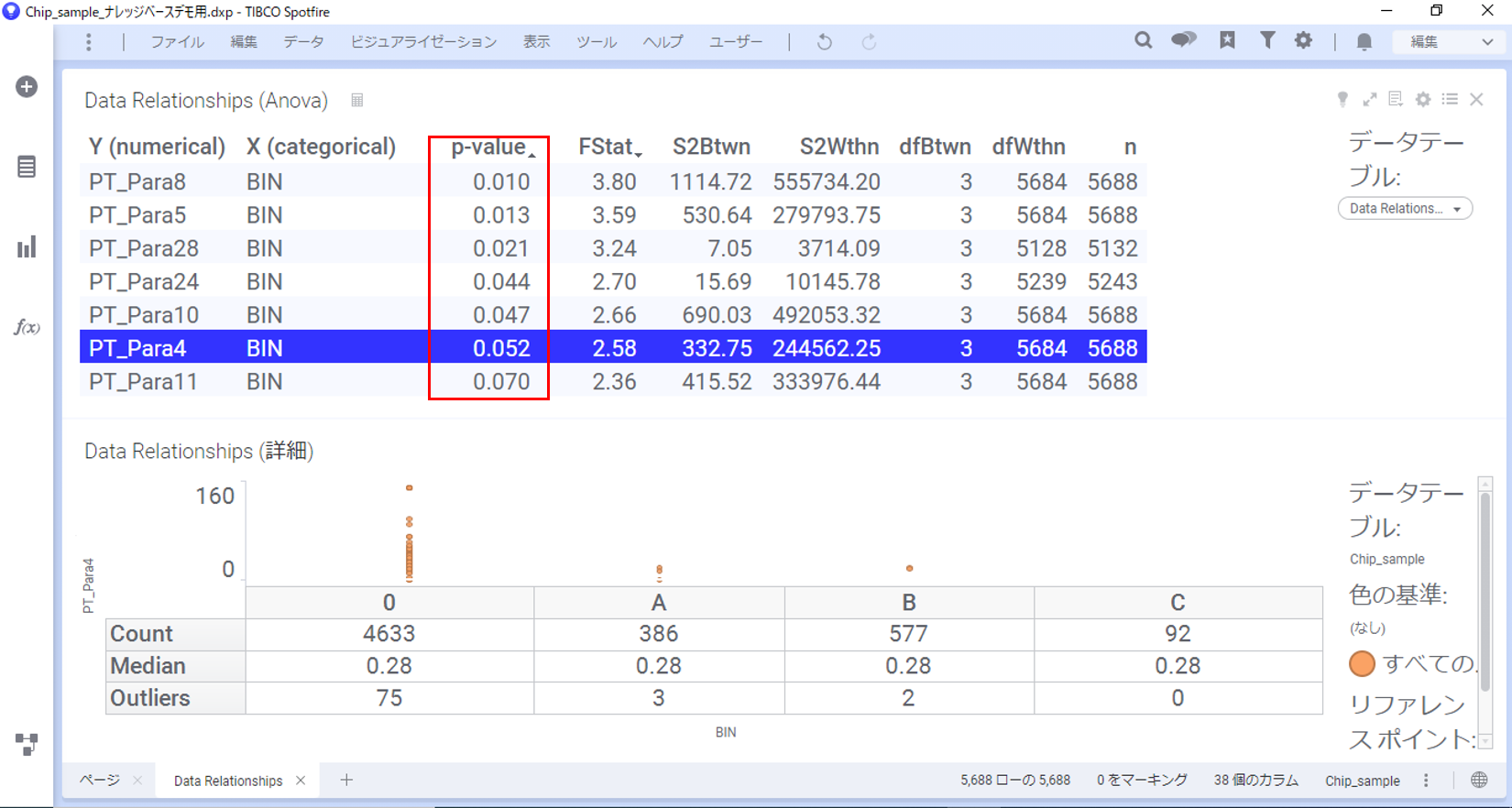
以上のように、Data Relationshipsを用いることで変数間の関連性を一覧で簡単に把握できます。
前の記事
データを類似度でグループ化次の記事
クラスタリングの使い方【統計分析】最新の記事


