![]()
![]()
![]()
![]()

2023/01/31
統計分析
※本記事は1/31開催セミナー「TIBCO Spotfire活用セミナー ~ 統計解析ツール - 回帰モデリング編 - ~」で紹介した内容です。
このコンテンツでは、統計解析ツールの回帰モデリングについて説明しています。
本コンテンツで利用したバージョンは、Spotfire Analyst 11.4です。ご利用環境によって、一部画面構成が異なる場合がありますので、ご了承ください。
Spotfireに標準搭載されている統計ツールは、誰でも簡単に統計的な手法を使ってデータに含まれるパターンや傾向を確認できます。
以下の統計手法が搭載されています。
本コンテンツでは、回帰モデリングについて説明します。
回帰モデリングは結果(連続値)に影響する要因の特定や予測ができる回帰モデルを作成する機能です。
Spotfireで利用できる回帰モデルは2つあります。
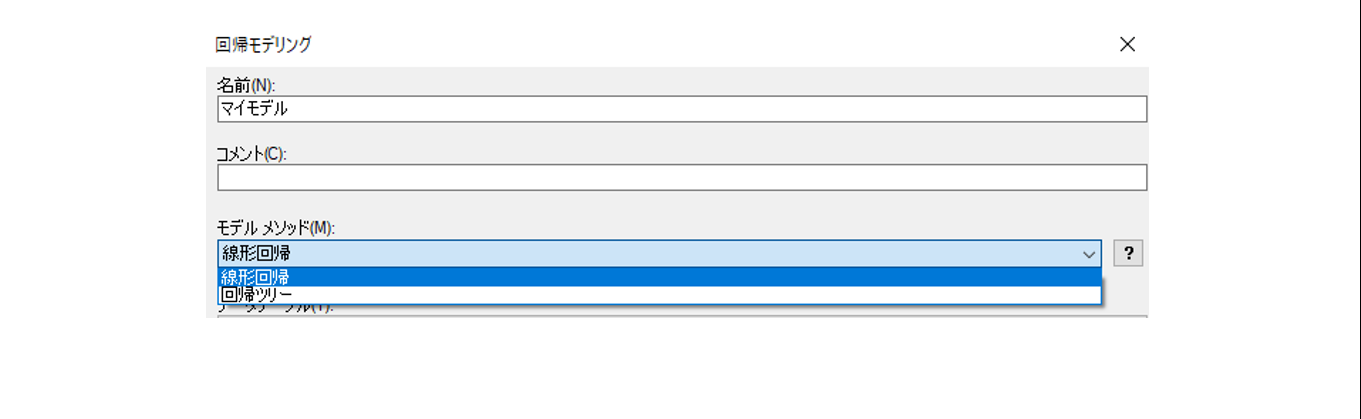
線形回帰は、説明変数Xを利用して、目的変数Yを予測する関係式(回帰式)を作成します。

単回帰だけでなく、複数の説明変数を入れること(重回帰分析)が可能です。これにより、複数の要因から影響の大きい要因を特定できます。

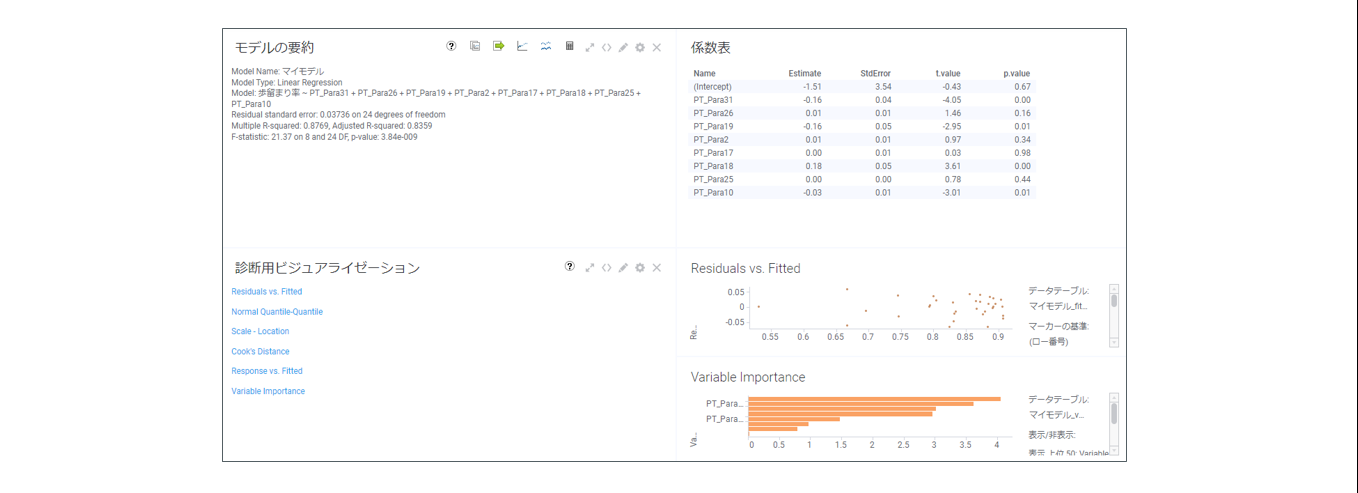
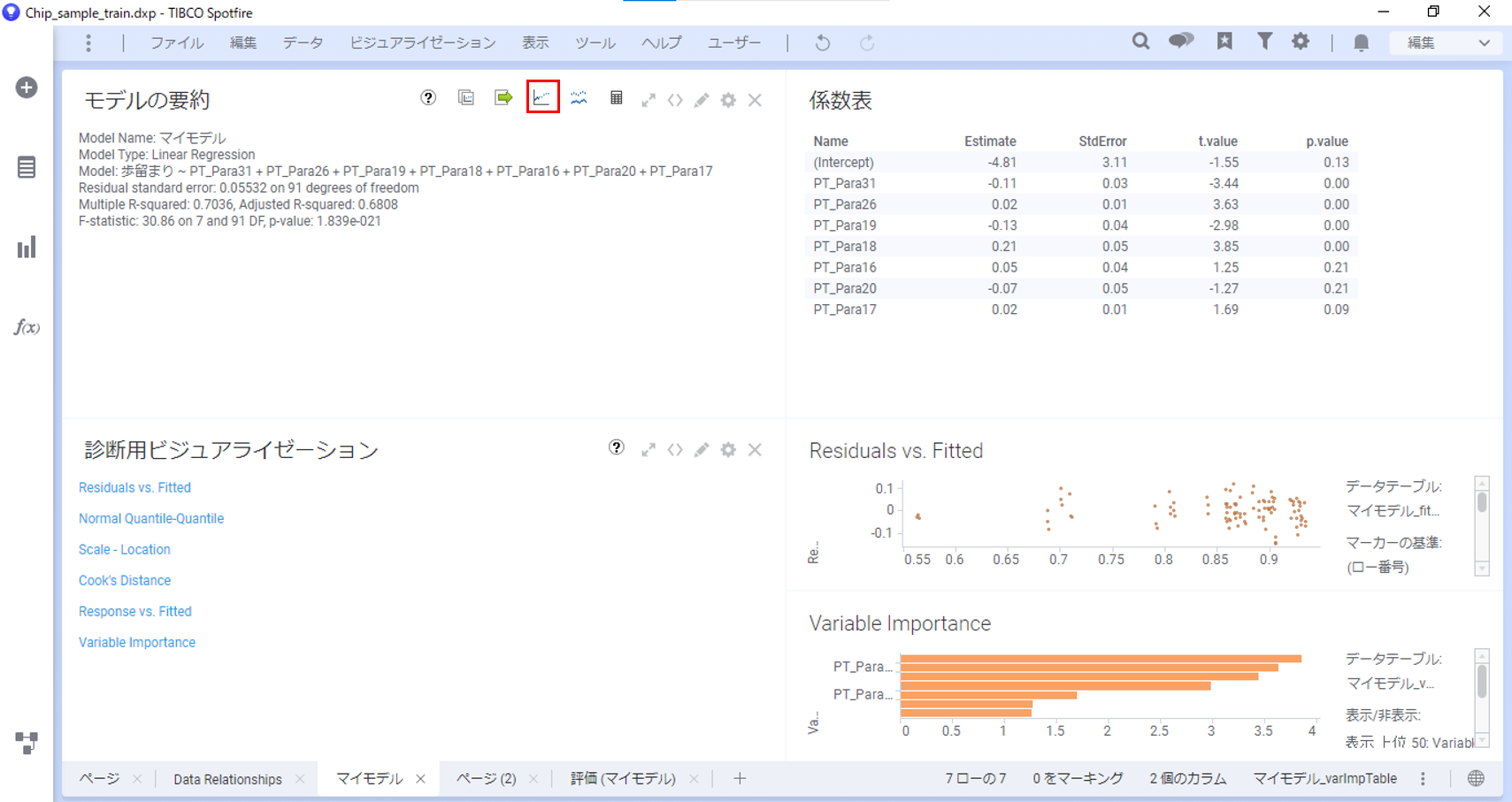
線形回帰の結果は3領域に分けて表示されます。
①モデルの要約
決定係数(Multiple R-squared)や自由度調整済み決定係数(Adjested R-squared)を確認してモデルの精度を確認できます。
②係数表
表から回帰式を読み取ることができます。
③診断用ビジュアライゼーション
以下のビジュアライゼーションからモデルの妥当性を判断できます。
詳しくはSpotfireに内蔵されている「TIBCO Spotfire ユーザーガイド」(ツールバー「ヘルプ」> 「ヘルプトピック」)をご参照ください。
回帰ツリーは、データから決定木と呼ばれるツリー構造を作成して予測を行います。
予測値はデータをいくつかの区画に区切り、区画ごとの平均値から算出します。
親ノードからの分割基準は、子ノードの平均値からのばらつきが親ノードよりも小さくなるように決定します。
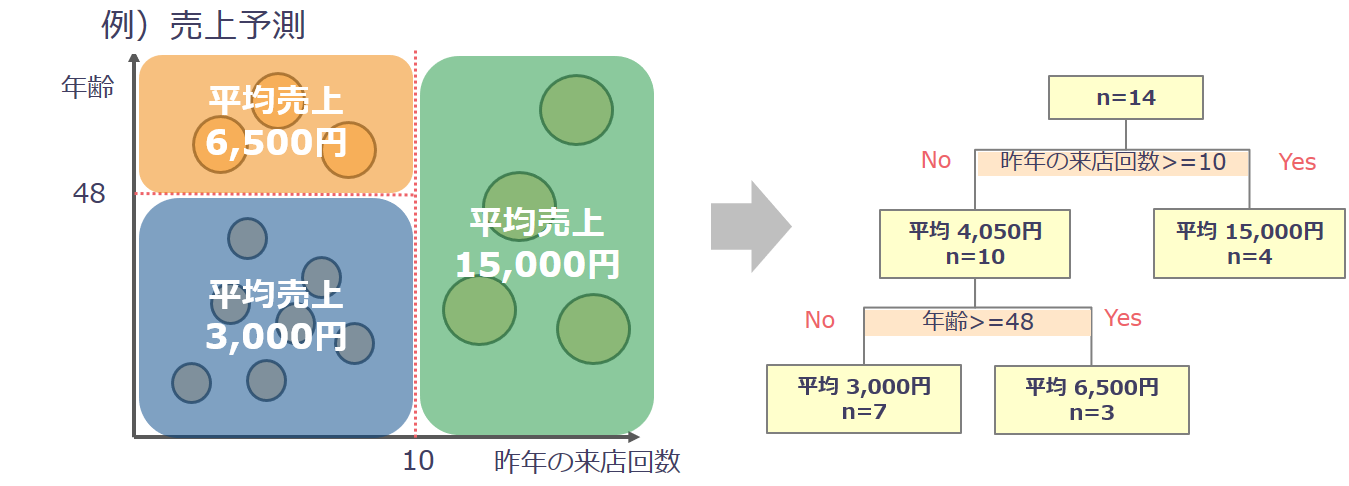
回帰ツリーの結果は2領域に分けて表示されます。
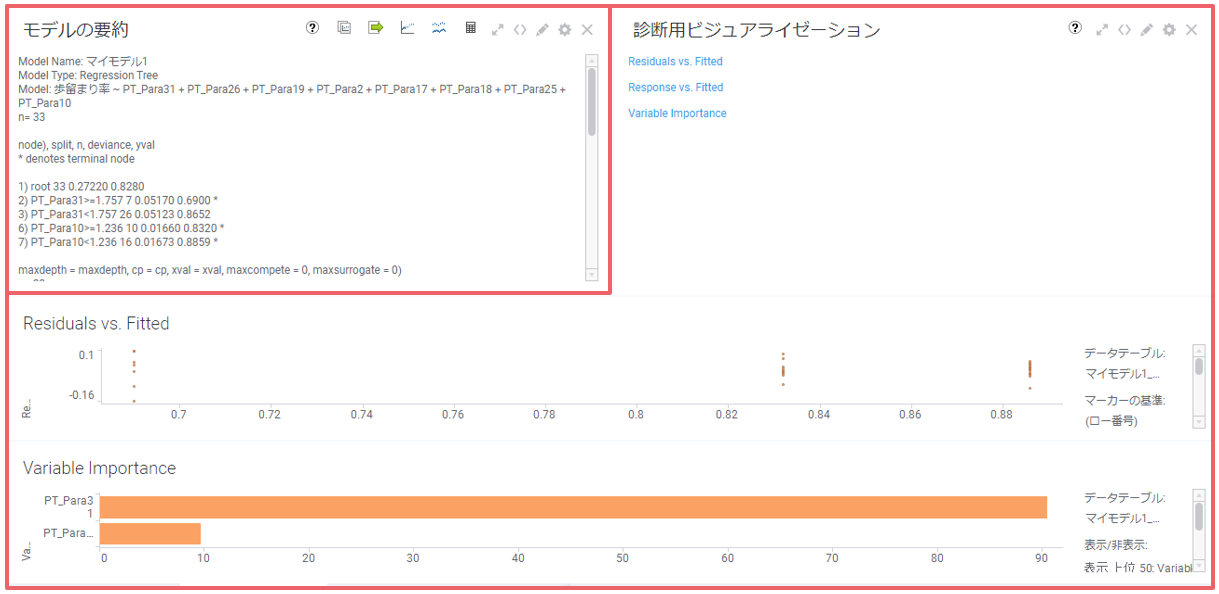
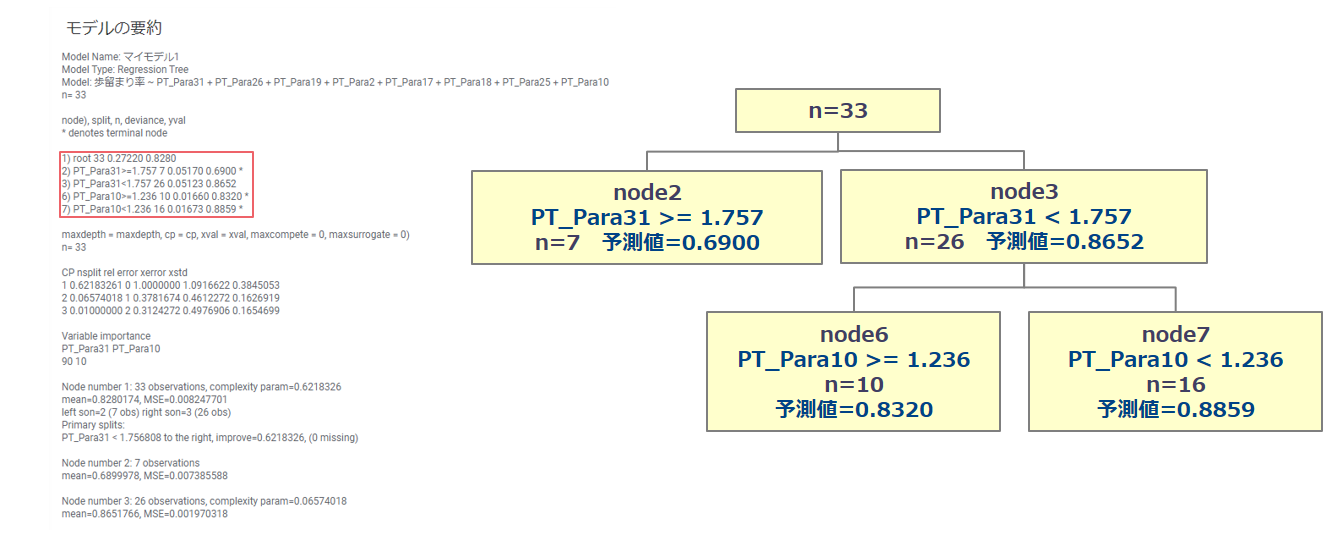
①モデルの要約
結果からツリー構造の分岐を確認できます。
②診断用ビジュアライゼーション
以下のビジュアライゼーションからモデルの妥当性を判断できます。詳しくはSpotfireに内蔵されている「TIBCO Spotfire ユーザーガイド」(ツールバー「ヘルプ」> 「ヘルプトピック」)をご参照ください。
本コンテンツでは、半導体のデータを用いて、歩留まりを予測する線形回帰を行います。
以下の流れで実施します。
①モデルの作成:歩留まりに影響する要因を特定
②モデルの評価・予測:歩留まりを予測
本コンテンツで使用するデータはこちらからダウンロードしてください。
半導体製造工程におけるサンプルデータです。
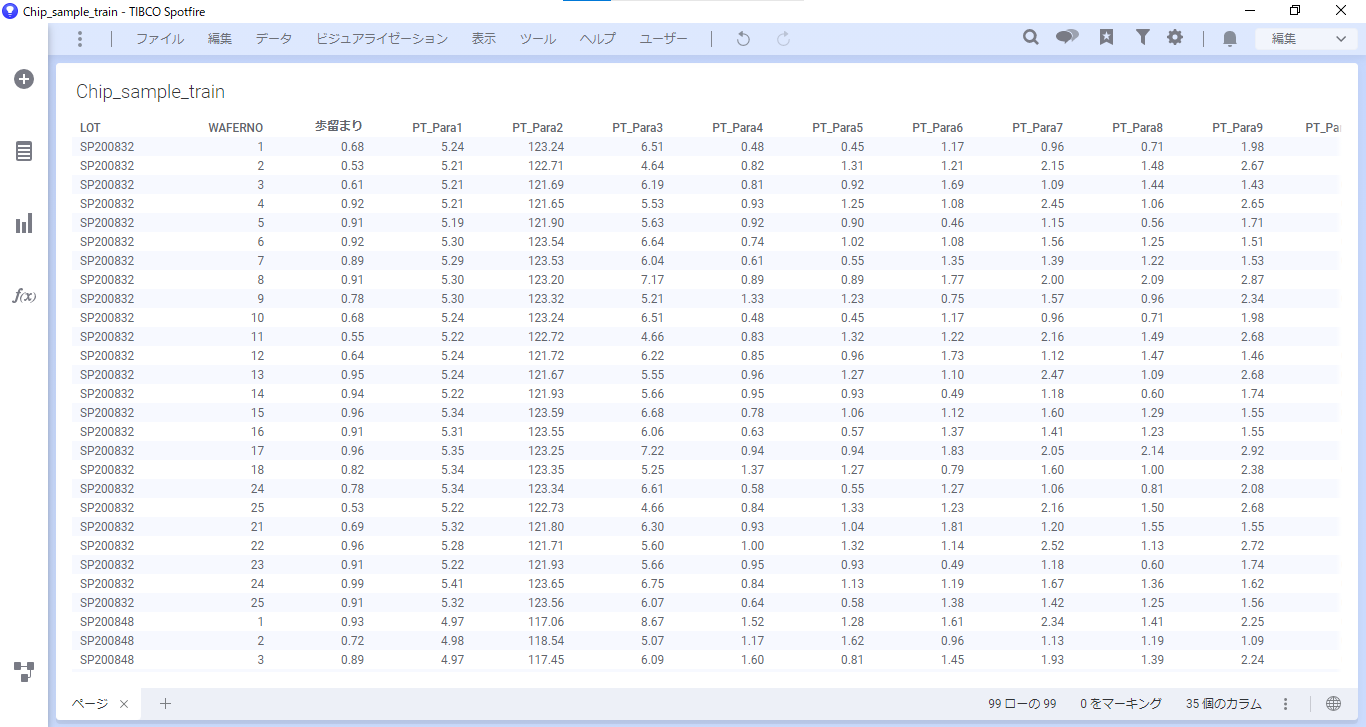
まず「Chip_sample_train.csv」を読み込みます。
テーブルを表示してデータを確認します。「ビジュアライゼーションタイプ」>「テーブル」を選択します。
1行1ウェハのデータになっています。
今回は、歩留まりを予測する線形回帰モデルを作成します。
モデルを作成する前に、目的変数「歩留まり」に影響する説明変数「PT_Para」(パラメータ)を選定するため、2変数の関連性を総当たりで確認します。
メニューバー「ツール」>「Data Relationships」を選択し、以下を設定して「OK」を押します。
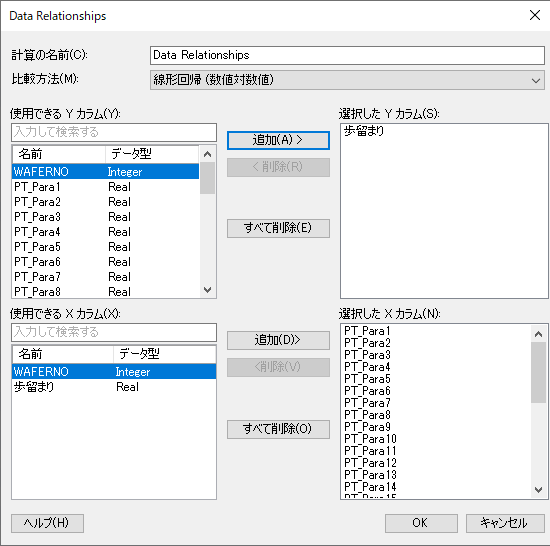
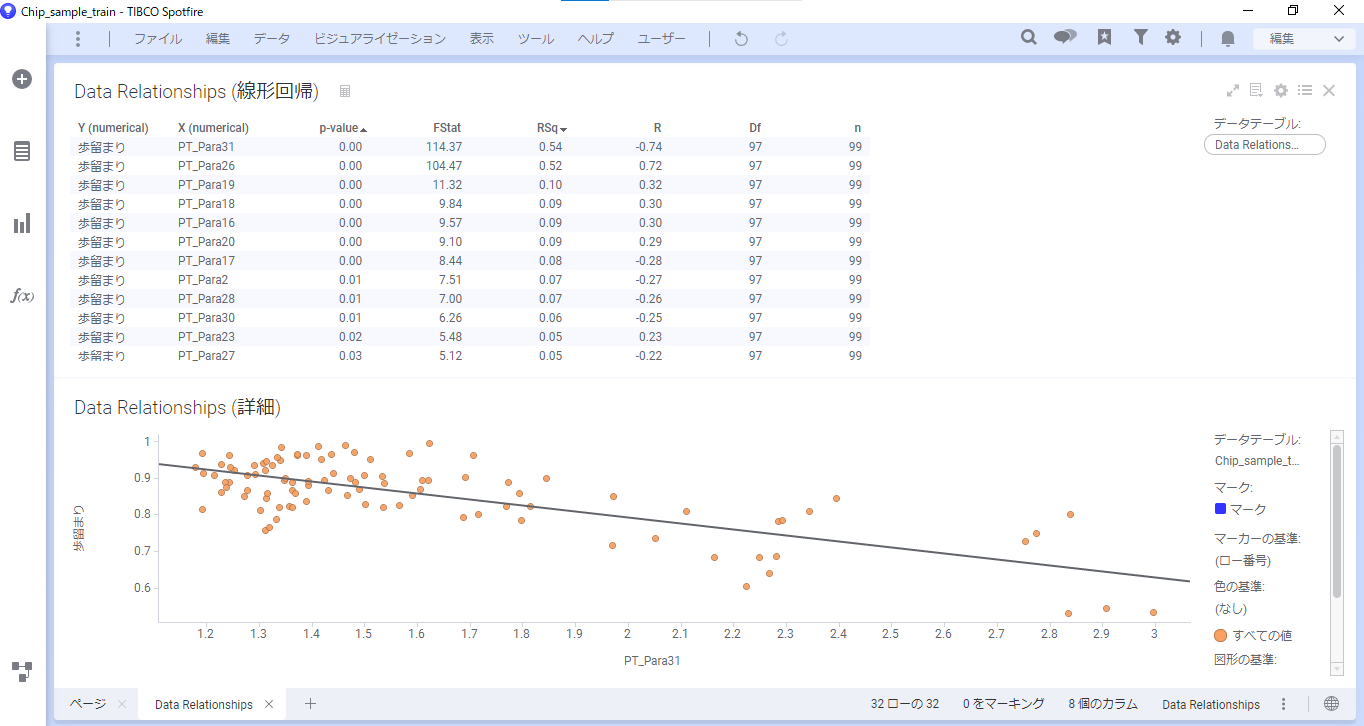
歩留まりと関連のあるパラメータが表示されます。一般的にP値が0.05より小さければ有意とみなします。確認すると、多くのパラメータで有意であることが分かります。
今回は上から順に7つのパラメータを説明変数として使用します。
※下図はP値を指数表記から小数に直しています。方法はこちらをご参照ください。
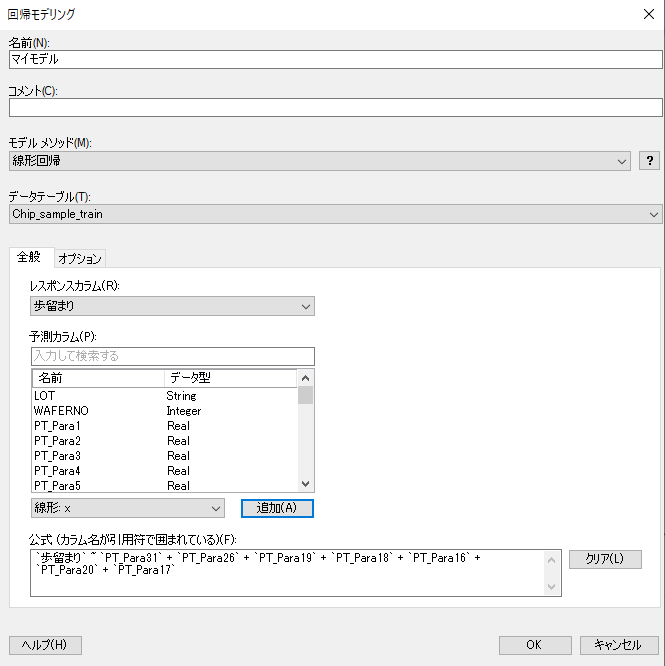
上記で選んだ7つのパラメータを説明変数に入れてモデルを作成します。
メニューバー「ツール」>「回帰モデリング」を選択し、以下を設定して「OK」を押します。
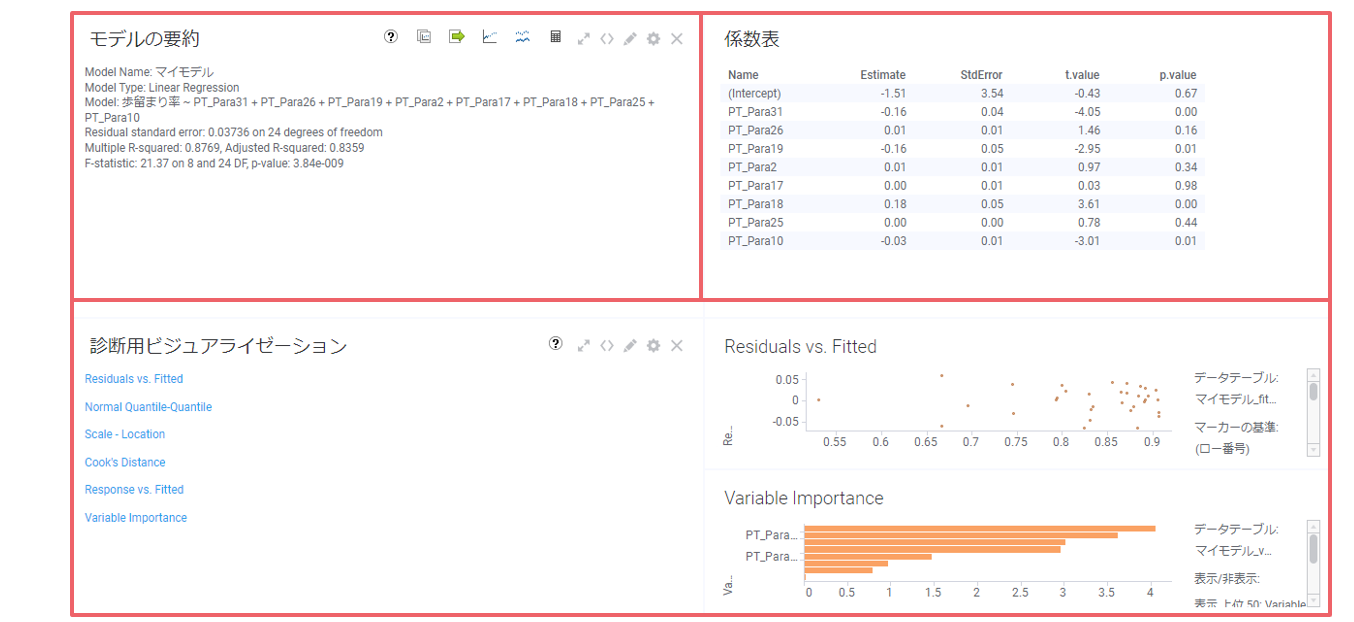
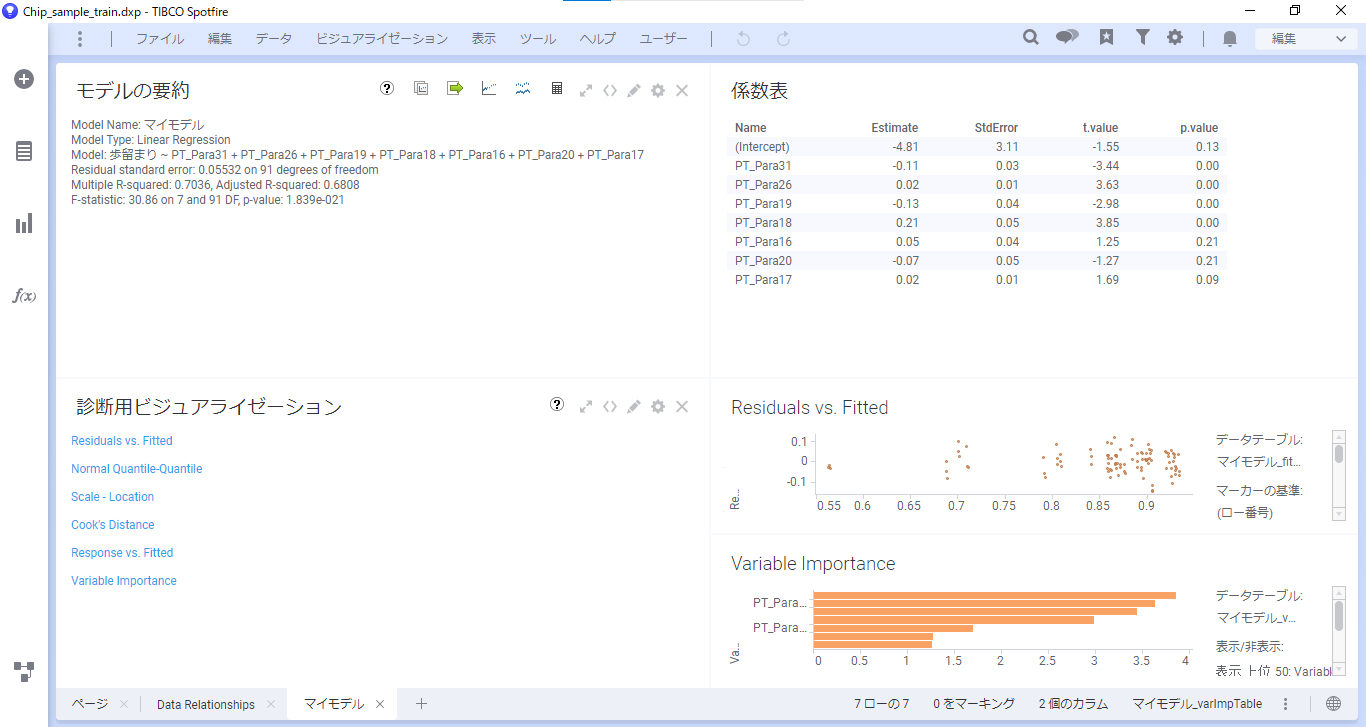
すると、結果の画面が出てきます。
決定係数を確認すると、0.70と比較的高い数値が出ており、モデルの当てはまりが良いことが分かります。
※決定係数の値はいくつ以上であれば良いなどの明確な基準はありません。値の閾値についてはケースバイケースになります。
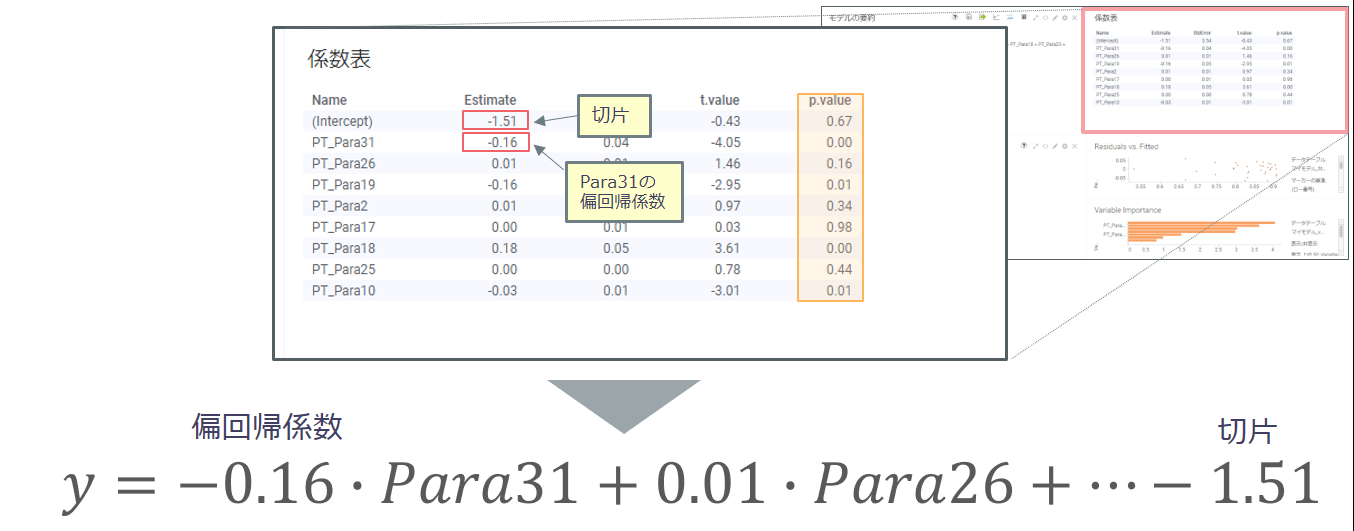
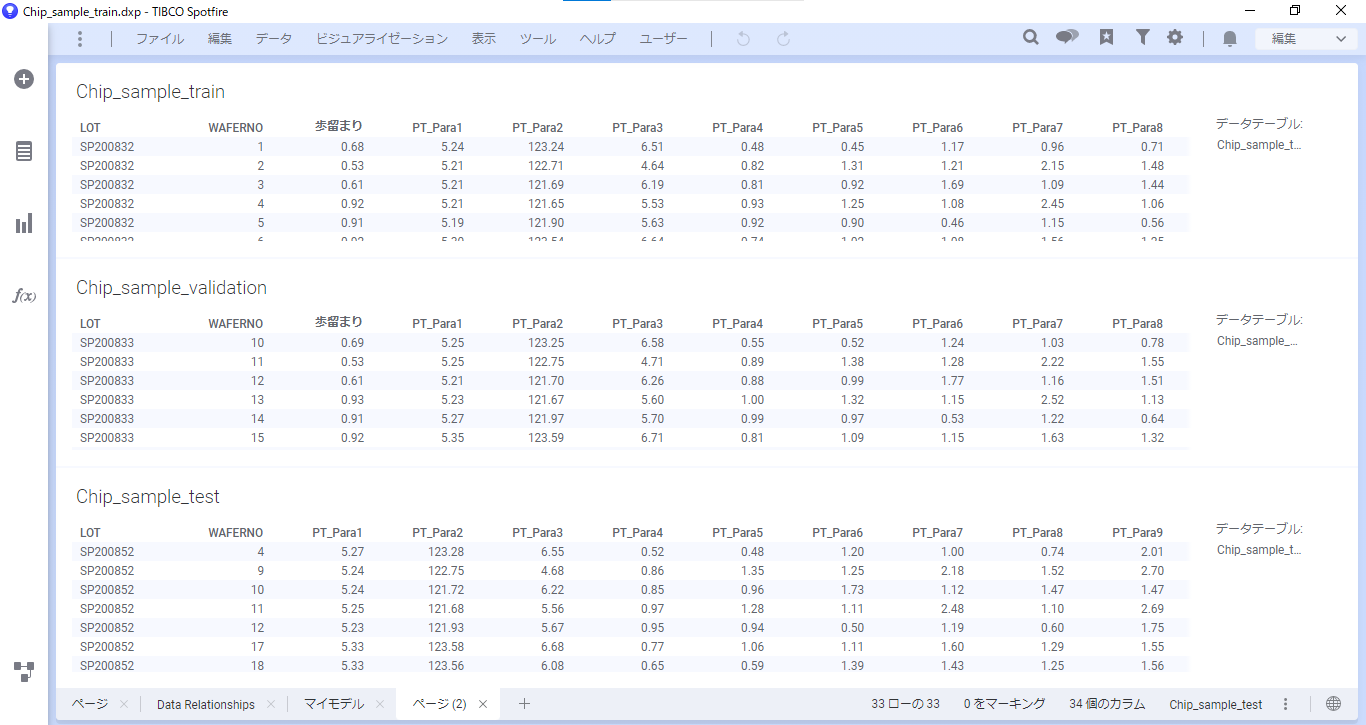
変数重要度を見ると、歩留まりにはPT_Para18が一番影響を与えていることが分かります。
PT_Para18のP値から統計的に有意な結果であり、偏回帰係数が0.21であると分かります。このことから、PT_Para18の値が1大きくなると歩留まりが0.21上がり、逆に値が小さくなると歩留まりも下がることが分かります。
この結果から、PT_Para18は注視すべきパラメータであり、関連しているプロセスや装置を見直すといったアクションを起こすことができます。
先ほど作成した線形回帰モデルを評価し、新しいデータに対して歩留まりを予測していきます。
新たにデータを追加します。「Chip_sample_validation.csv」「Chip_sample_test.csv」をそれぞれ新しいデータテーブルとして取り込みます。
各データについての説明は以下の通りです。
モデルから歩留まり率を予測するために使用するデータ。目的変数「歩留まり」は含まれません。
先ほど作成したモデルに対して、同じ目的変数(歩留まり)と説明変数(PT_Para)がある別のデータを入れることで、モデルの精度を評価します。
先ほど作成した線形回帰モデルの結果ページの「モデルの評価」アイコンをクリックします。
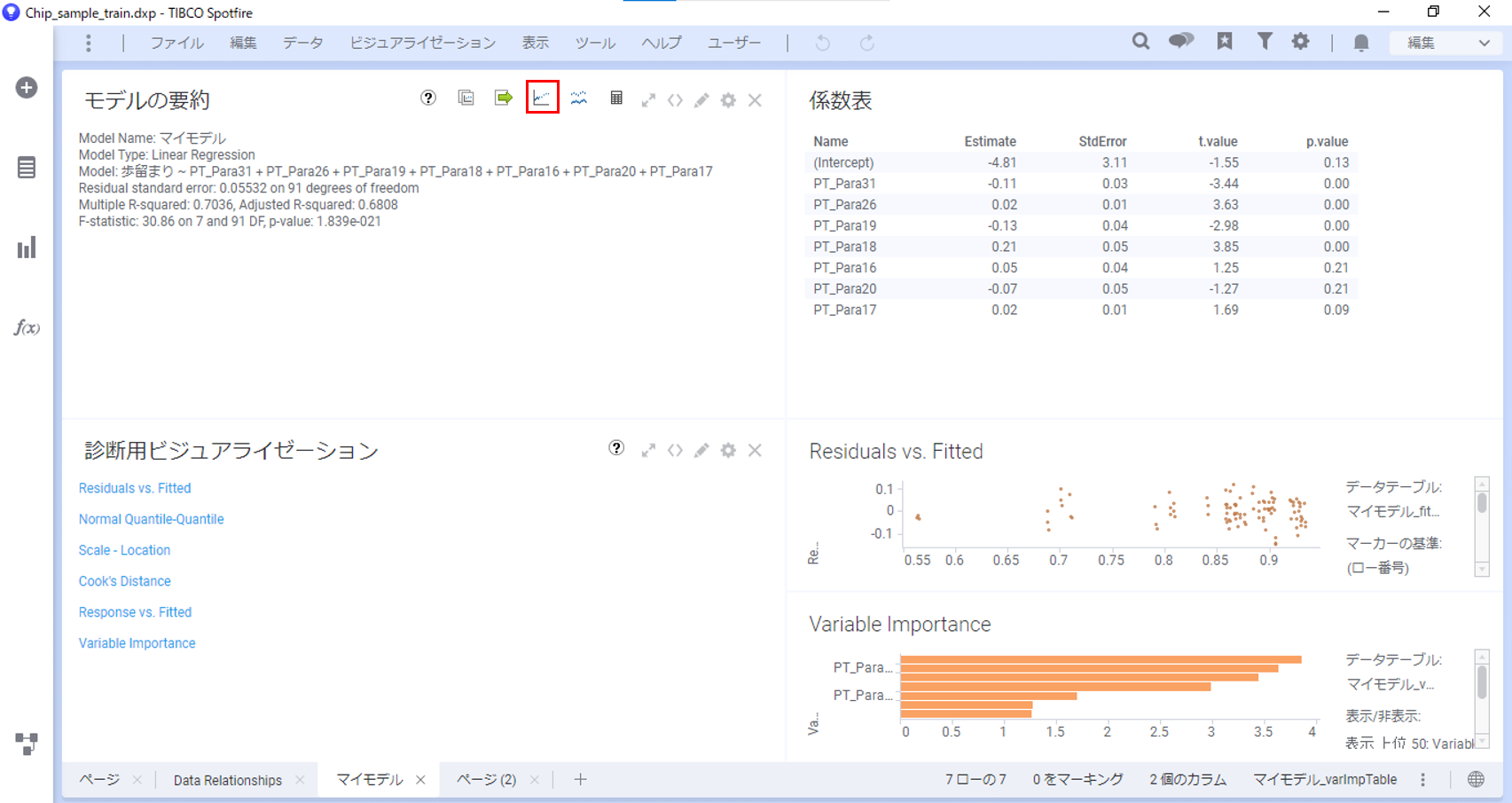
すると、「分析モデルの評価」ダイアログが表示されるので、以下の設定をします。カラムの対応付けが完了したら「OK」を押します。
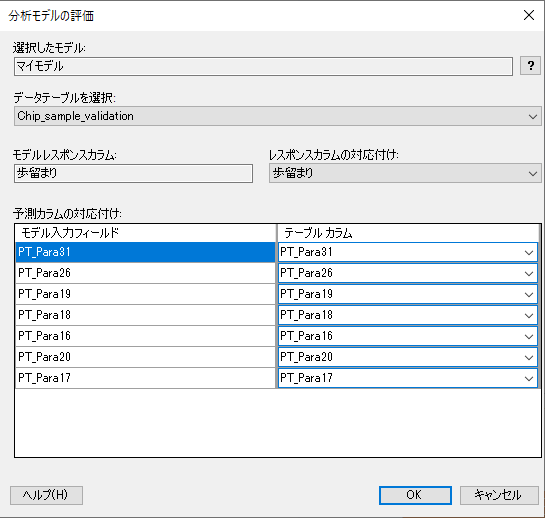
モデルの評価の結果ページが表示されます。決定係数を確認します。すると、0.79と高い数値が出ており、モデルの精度が良いことが分かります。
今回はモデルの精度が良い結果になりましたが、モデルの精度が良くない場合、再度モデル作成に戻り、変数の調整などを行います。
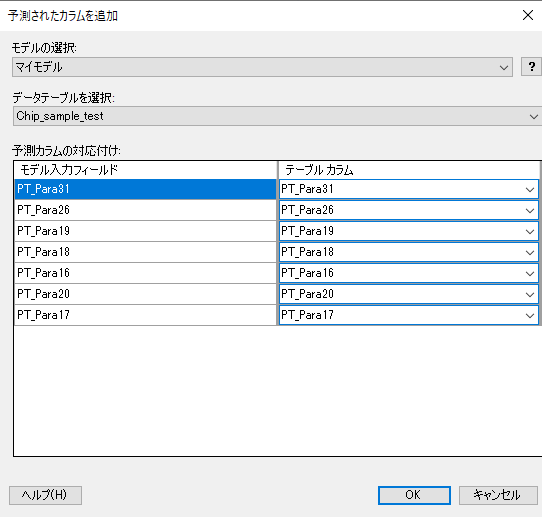
最後に作成したモデルを使用して予測を行います。モデルを作成したページ「マイモデル」に戻り、「モデルから予測」アイコンをクリックします。
すると、「予測されたカラムを追加」ダイアログが表示されるため、以下の設定をします。設定ができたら「OK」をクリックします。
画面に変化はありませんが、予測ができていることを確認します。
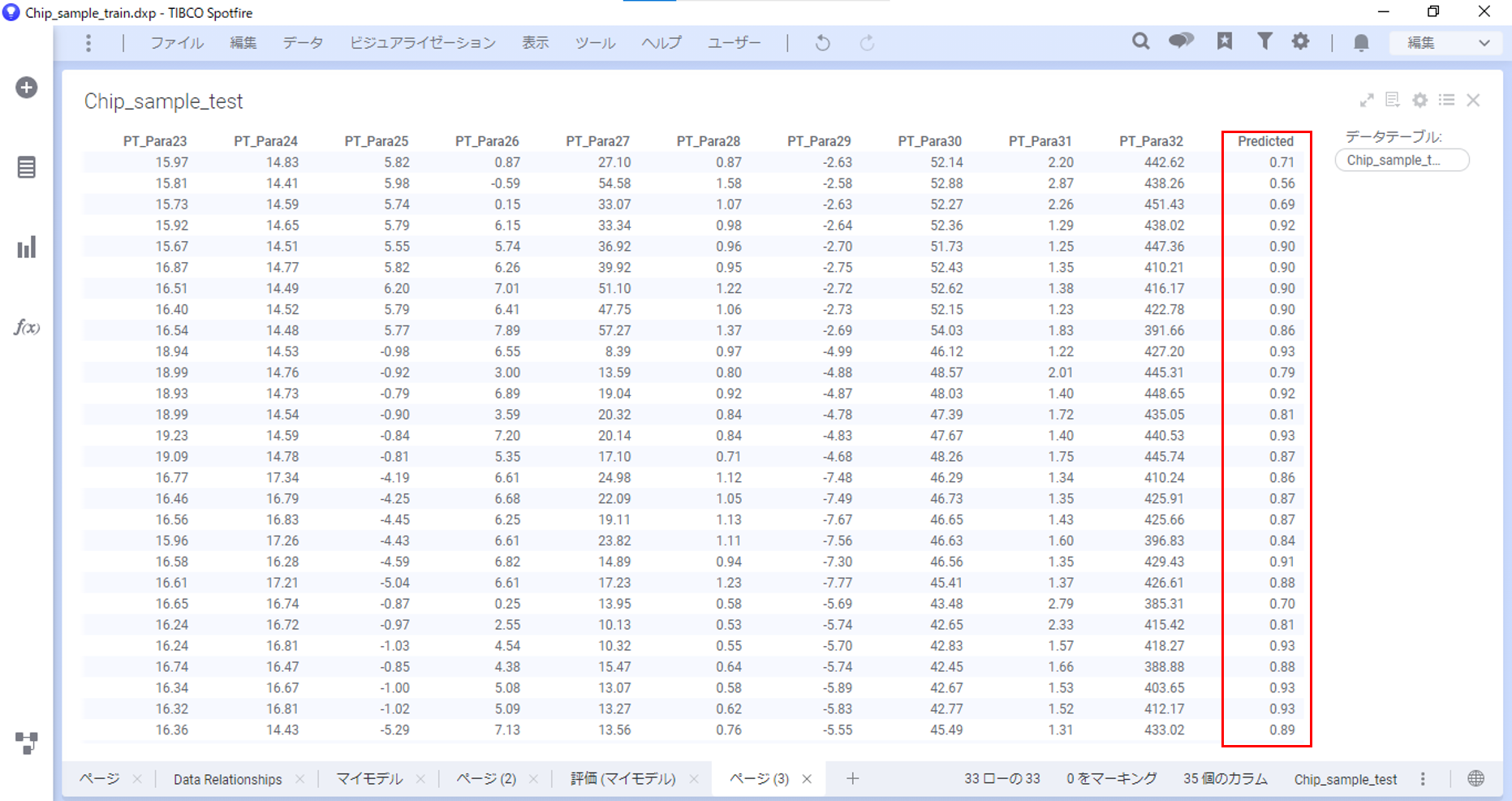
新たにページを追加して、テーブル「Chip_sample_test」を表示します。
横にスクロールして右端のカラムを確認すると、「Predicted」というカラムが新たに追加されています。「Predicted」には歩留まりの予測値が算出されています。
メニューバー「表示」>「分析モデル」を選択することで、作成したモデルの編集や評価・予測が可能です。複数モデルを作成した場合や、モデルの結果ページを消してしまった場合に便利です。

以上のように、回帰モデリングを活用することで、目的変数に影響を与えている要因の特定や、将来予測を簡単に行えます。
Spotfire活用セミナー
アーカイブ動画を配信中
前の記事
クラスタリングの使い方次の記事
分類モデリングの使い方【統計分析】最新の記事

