![]()
![]()
![]()
![]()

2023/02/28
統計分析
※本記事は2/28開催セミナー「TIBCO Spotfire活用セミナー〜 統計解析ツール - 分類モデリング編 - ~」で紹介した内容です。
このコンテンツでは、分類モデリングについて説明しています。
本コンテンツで利用したバージョンは、Spotfire Analyst 11.4です。ご利用環境によって、一部画面構成が異なる場合がありますので、ご了承ください。
Spotfireに標準搭載されている統計解析ツールは、誰でも簡単に統計的な手法を使ってデータの関係性を確認できます。
以下の統計解析機能が搭載されています。
本コンテンツでは、分類モデリングについて説明します。
分類モデリングは、結果(離散値)に影響する要因の特定や予測ができる分類モデルを作成する機能です。
Spotfireで利用できる分類モデルは2つあります。
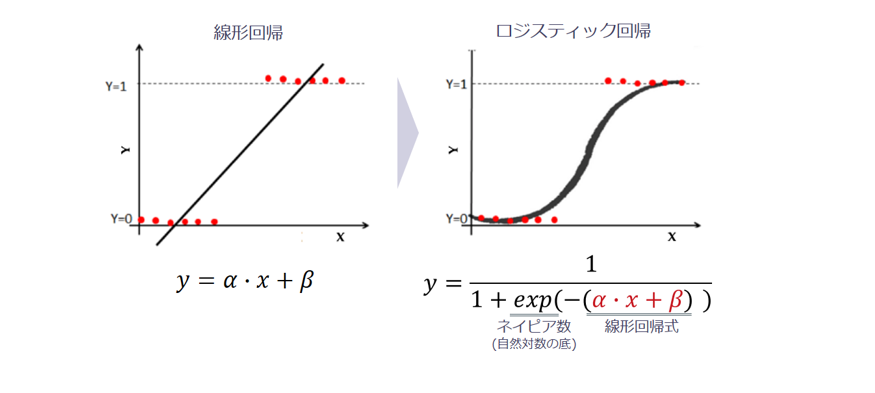
ロジスティック回帰は、いくつかの要因(説明変数)から2値の結果(目的変数)が起こる確率を説明・予測できます。一般的に目的変数が2値の場合に用いられます。
目的変数の例として以下があります。
目的変数が0/1からなる2値データを予測する場合、予測値(確率)が0〜1の間の値として収まります。
ロジスティック回帰の結果は3領域に分けて表示されます。
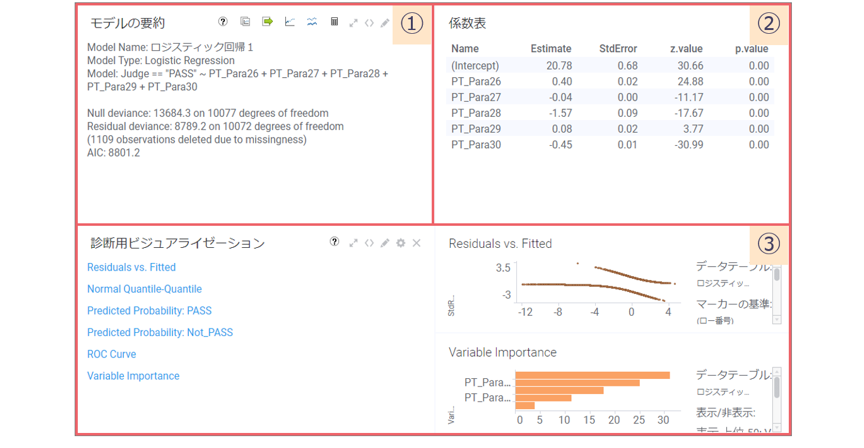
①モデルの要約
AIC(赤池情報量規準)を確認することで、モデルの精度を測ります。
②係数表
表から回帰式を読み取ることができます。

③診断用ビジュアライゼーション
以下のビジュアライゼーションからモデルの妥当性を判断できます。
※詳しくはSpotfireに内蔵されている「TIBCO Spotfire ユーザーガイド」(ツールバー「ヘルプ」> 「ヘルプトピック」)をご参照ください。
分類ツリーは、データから決定木と呼ばれるツリー構造を作成して予測を行います。
予測値はデータをいくつかの区画に区切り、区画ごとの値から算出します。
例)アイスを購入した顧客の分析
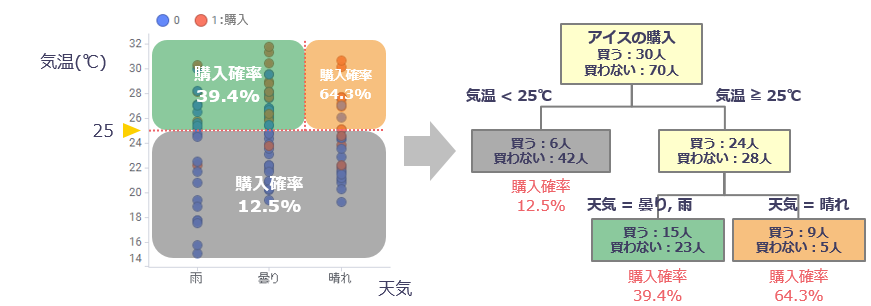
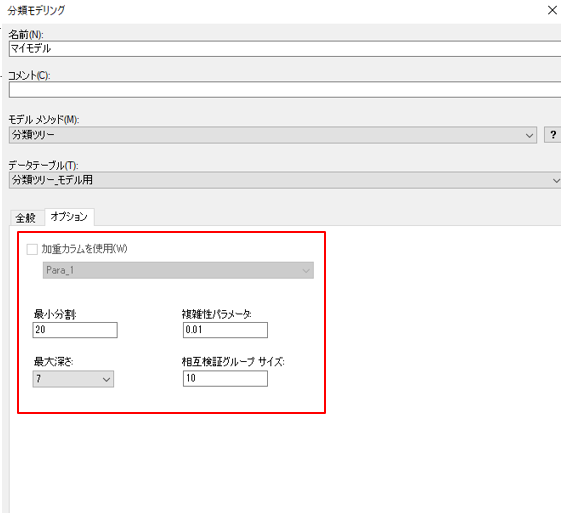
Spotfireでは、オプションで以下のパラメータを変更できます。
※詳しくはSpotfireに内蔵されている「TIBCO Spotfire ユーザーガイド」(ツールバー「ヘルプ」> 「ヘルプトピック」)をご参照ください。
分類ツリーの結果は2領域に分けて表示されます。
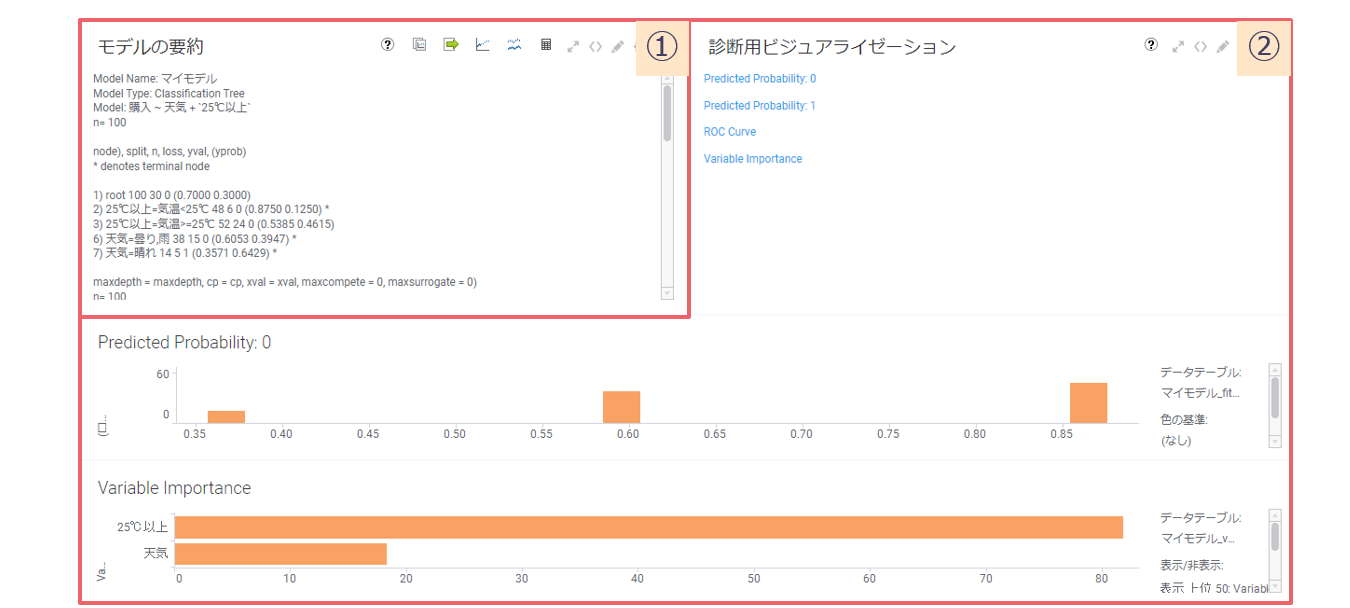
①モデルの要約
結果からツリー構造の分岐を確認できます。

②診断用ビジュアライゼーション
以下のビジュアライゼーションからモデルの妥当性を判断できます。
※詳しくはSpotfireに内蔵されている「TIBCO Spotfire ユーザーガイド」(ツールバー「ヘルプ」> 「ヘルプトピック」)をご参照ください。
本コンテンツでは、半導体データを用いて、不良を予測する分類ツリーを行います。
下記のような流れで実施します。
本コンテンツで使用するデータはこちらからダウンロードしてください。
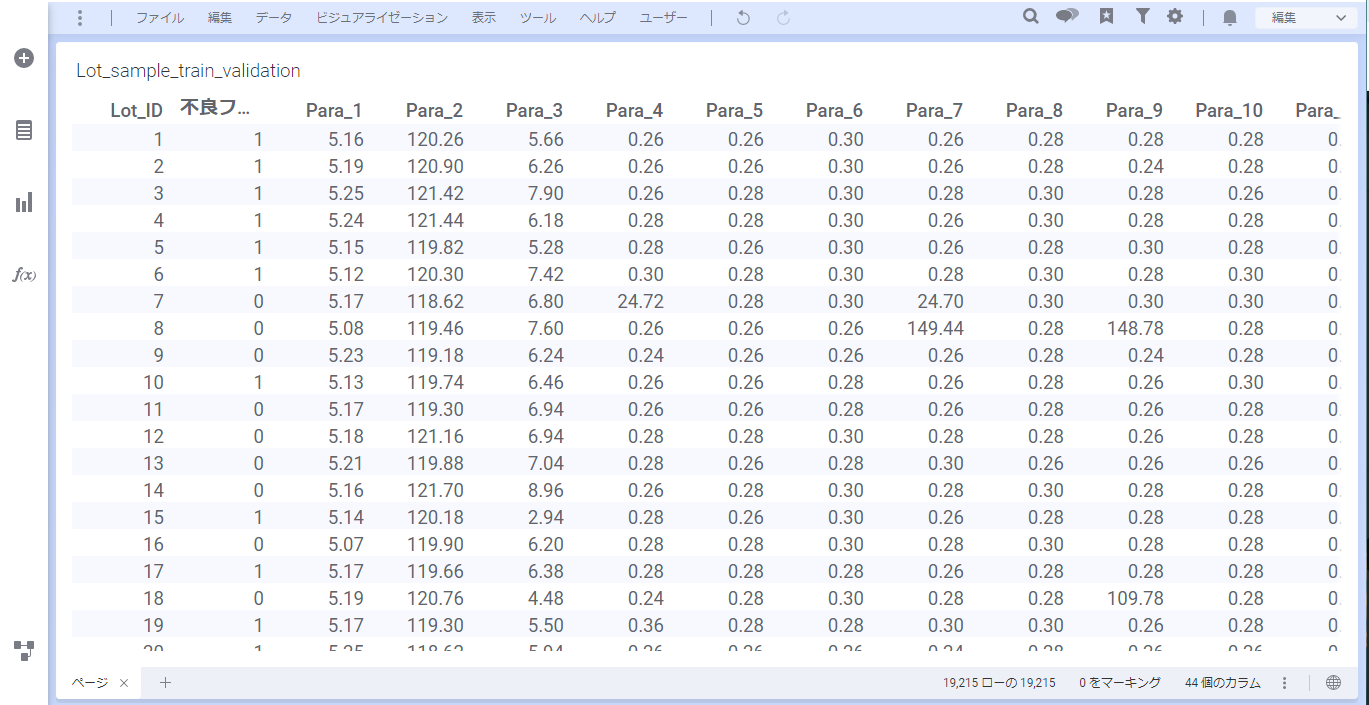
まず「Lot_sample_train_validation.csv」を読み込みます。
テーブルを表示してデータを確認します。「ビジュアライゼーションタイプ」>「テーブル」を選択します。
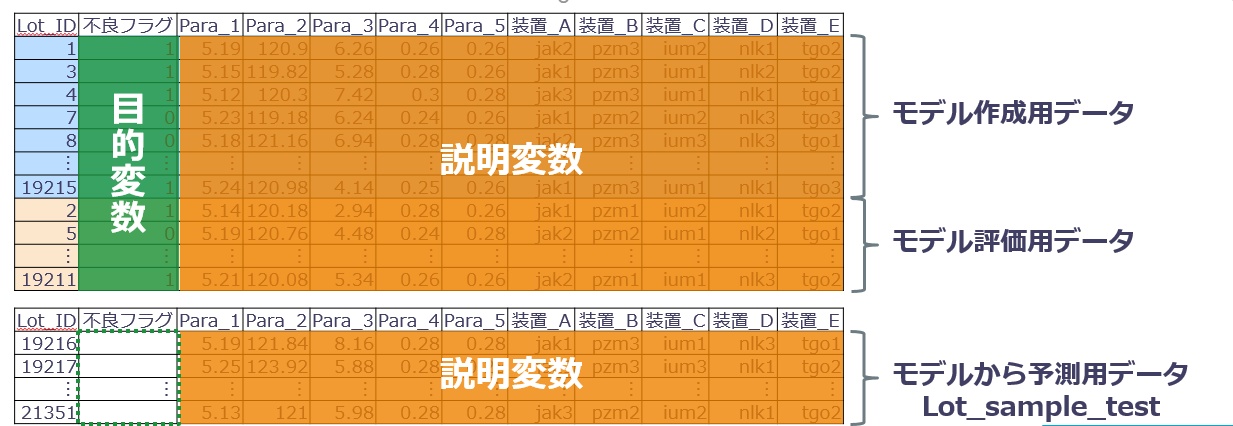
1行が1Lotのデータで、カラムとして下記を持ちます。
モデル作成とモデル評価をするために、ランダムにデータを下記の割合で2分割していきます。
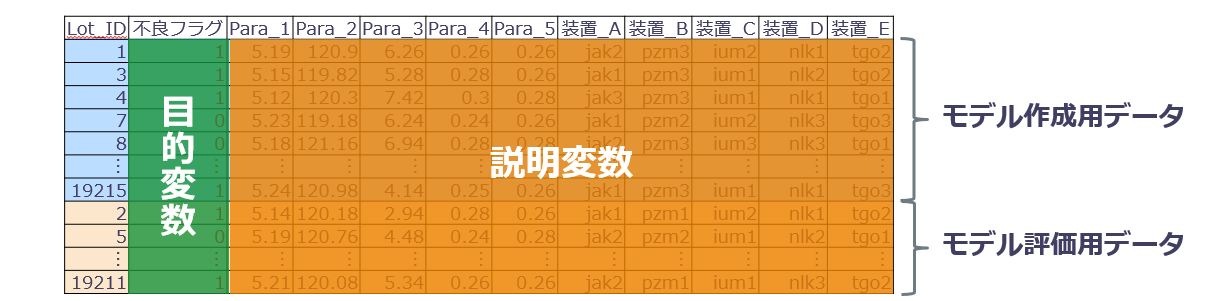
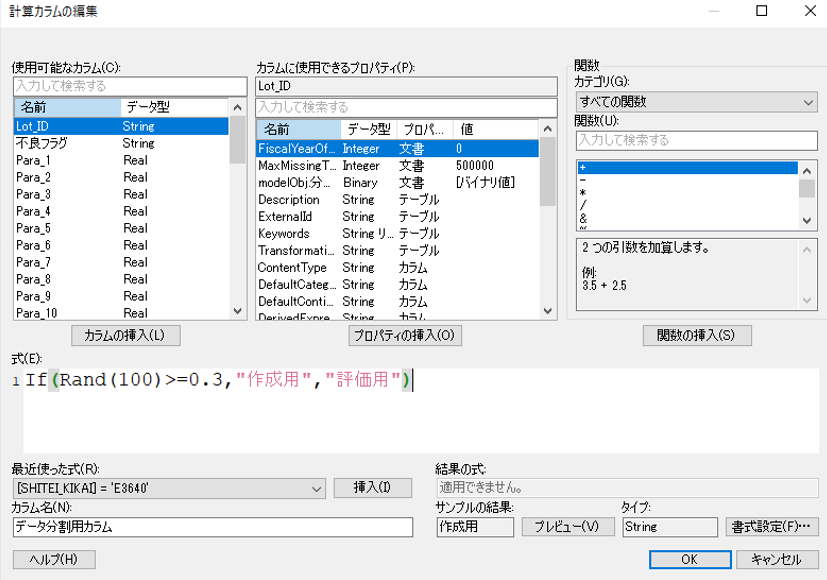
フィルターでの絞り込みでデータの2分割ができるように、計算カラムを使いフラグを立てます。
メニューバー「データ」>「計算カラムを追加…」を選択し、「式」および「カラム名」に以下を記入して「OK」を押します。
モデル作成用のデータを使ってモデルの作成を行います。
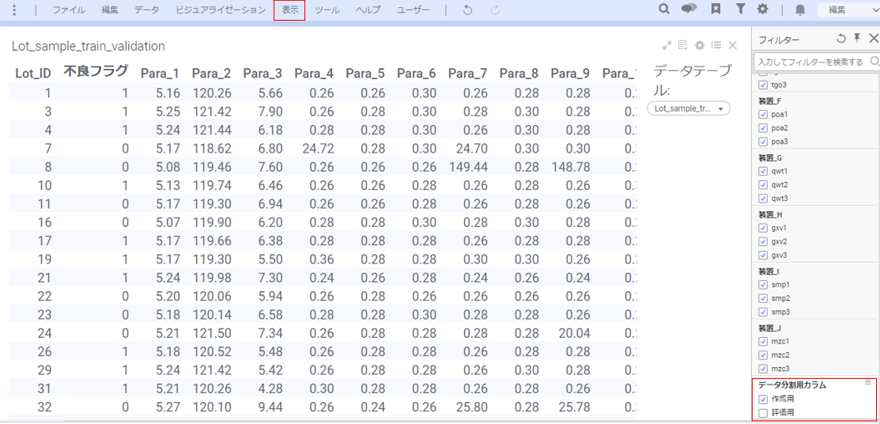
まずフィルターを使用します。メニューバー「表示」>「フィルター」を選択するとフィルターパネルが表示されます。
そこで先ほど作成したカラム「データ分割用カラム」の「作成用」のみにチェックを入れます。これにより、作成用データのみを使ってモデルを作ることができます。
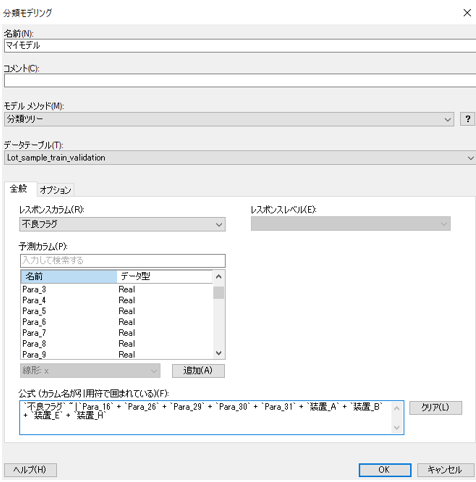
フィルターで絞り込んだ後、モデルを作成するためにメニューバー「ツール」>「分類モデリング」を選択し、以下を設定して「OK」を押します。
※説明変数である予測カラムが多すぎると結果に対しての解釈が複雑になってしまうことから、あらかじめ説明変数を絞り込んでいます。また絞り込み方法の一例はセミナー内では実演しましたが、本記事では省略しております。
すると、結果の画面が出てきます。
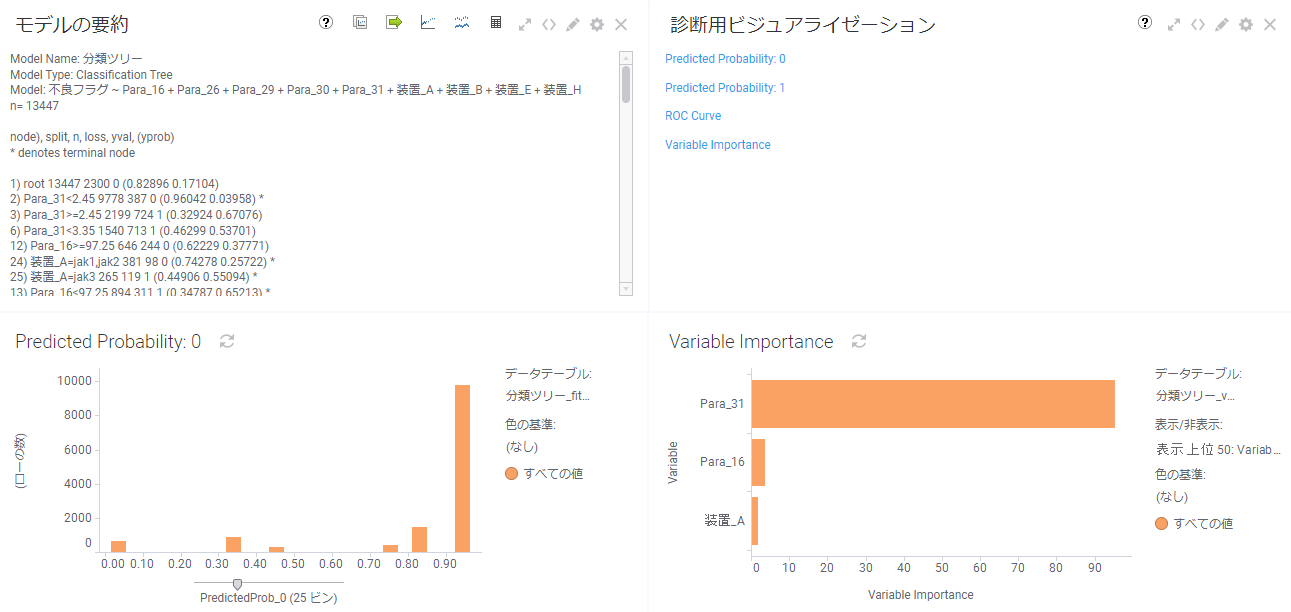
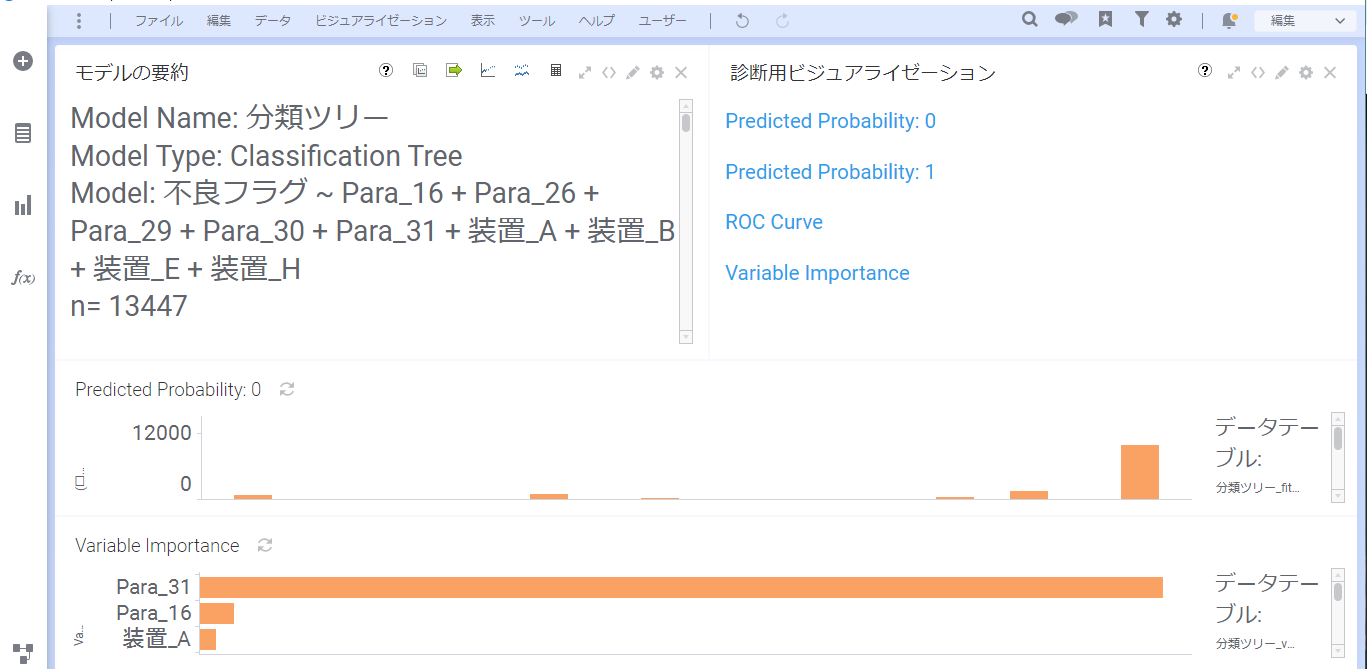
左上の「モデルの要約」を確認すると、分類ツリーの結果が「1)」から「7)」まで、ツリーの分岐順に表されています。
また、結果画面のVariable Importance(変数重要度)では、不良確率に高い影響を及ぼしている要素が下記の3つであることが分かります。
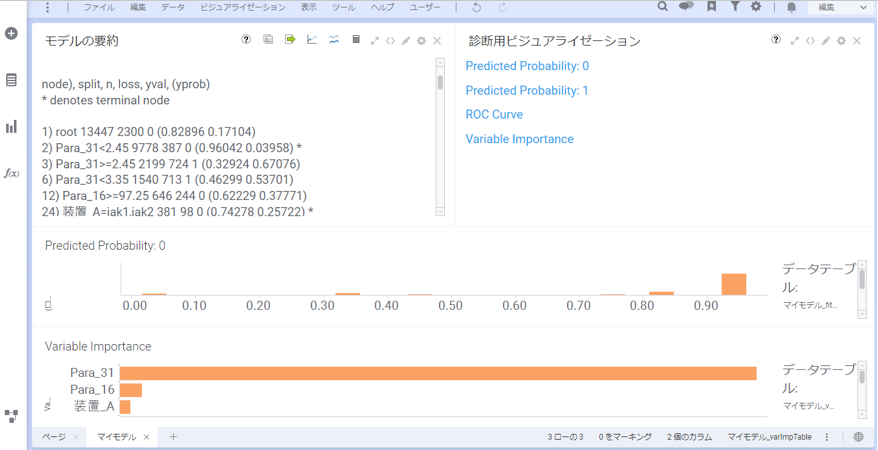
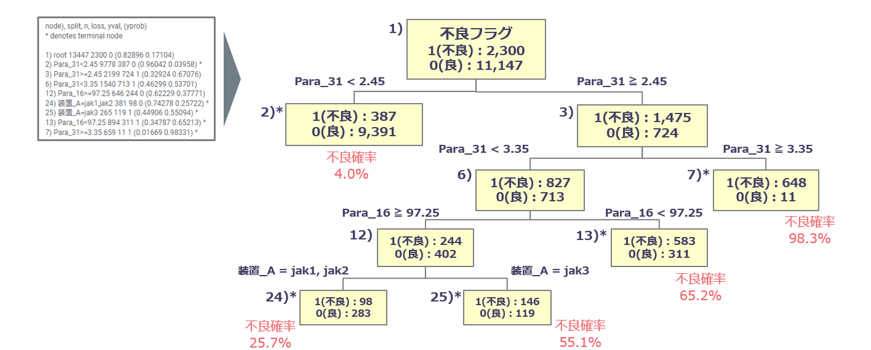
分かりやすくするため、下図のようにツリー上に可視化しました。
不良確率が高い順に3つを記載すると下記になります。
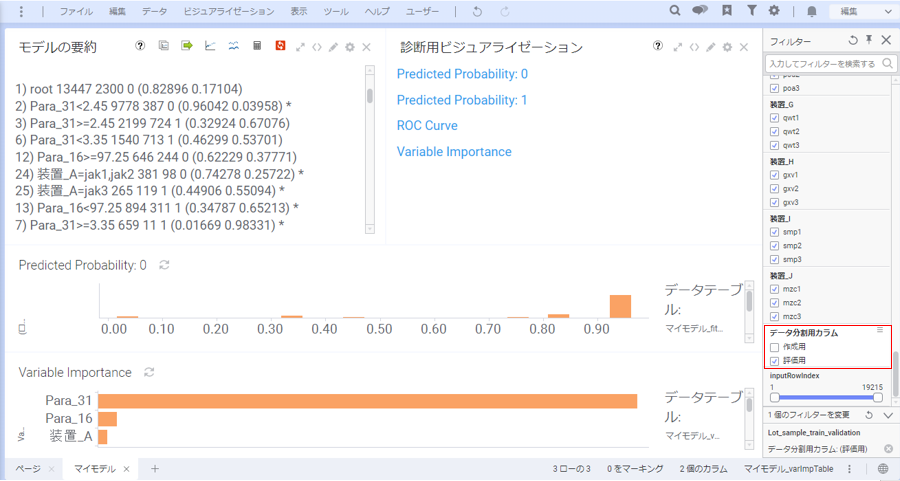
作成した分類ツリーモデルの評価を行い、作成用データに依存しすぎたモデルになっていないかを確認するため、モデルの評価を行います。
モデルの評価には、モデル評価用データ(7:3に分割したデータの3割の方)を使用します。
先ほどと同様に、フィルターパネルから、「データ分割用カラム」の「作成用」のチェックを外し、「評価用」にチェックを入れます。
先ほど作成した分類ツリーモデルの結果ページの「モデルの評価」アイコンをクリックします。
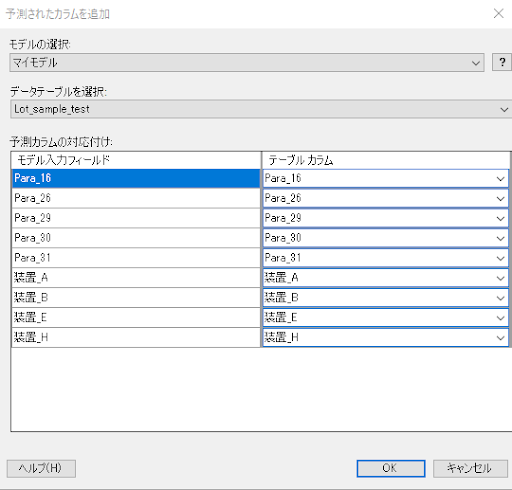
すると、「分析モデルの評価」ダイアログが表示されるので、以下を設定します。同じカラム名であれば自動的に対応付けされます。カラムの対応付けを確認できたら「OK」を押します。
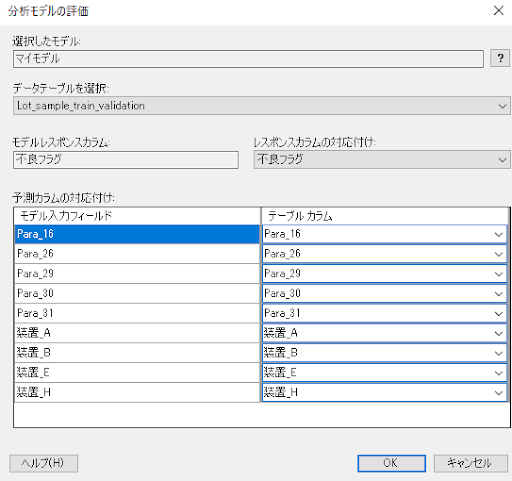
モデルの評価の結果ページが表示されます。
左上の「評価の要約」内で「Accuracy: 0.90135」と確認できます。これは投入した説明変数のデータがあれば、理論上約90%の確率で不良を正しく判定できることを意味しています。
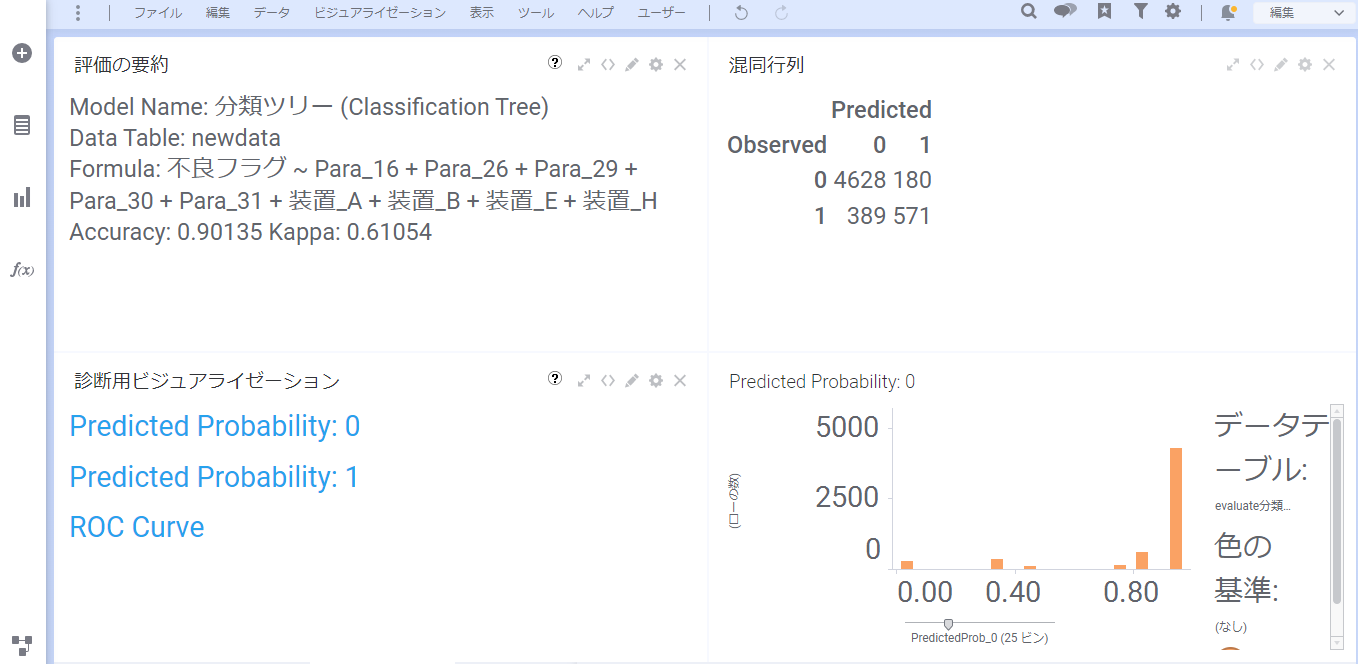
最後に、作成したモデルに対して、まだ不良かどうかわからない未知のデータを投入し、予測を行います。
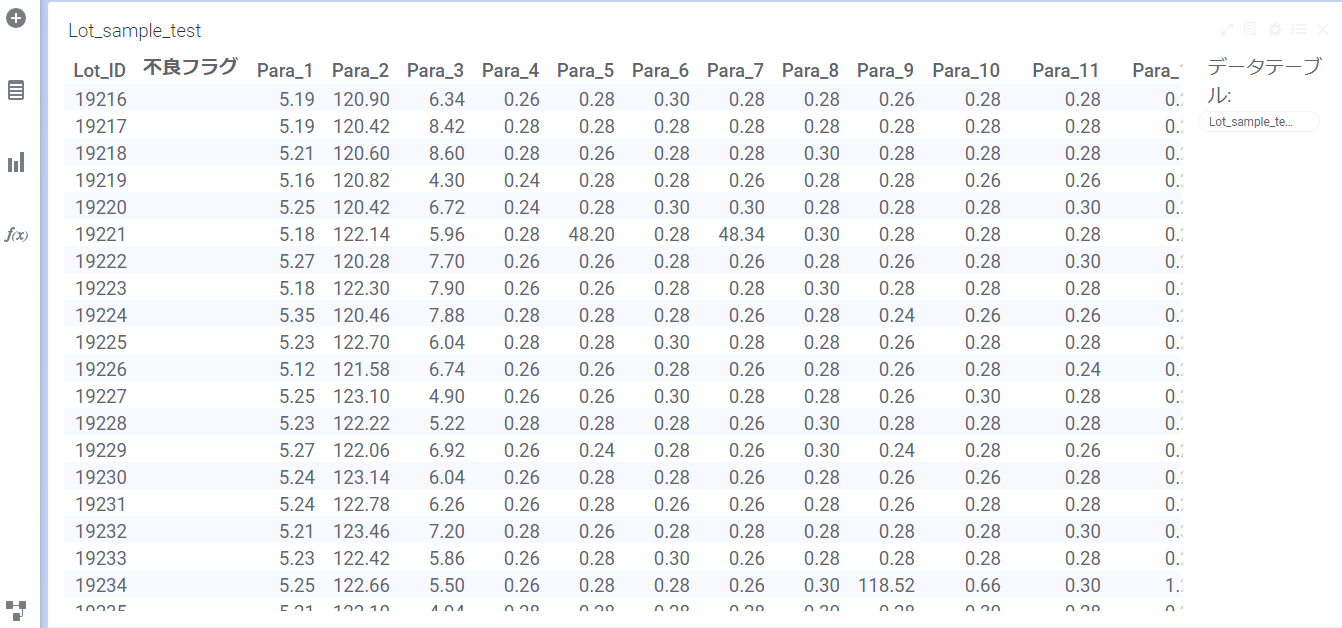
分類ツリーモデルの予測には、新たに追加するデータを使用します。「Lot_sample_test」を新しいテーブルとして取り込みます。
モデルを作成したページ「マイモデル」に戻り、「モデルから予測」アイコンをクリックします。
すると、「予測されたカラムを追加」ダイアログが表示されるため、以下の設定をします。設定ができたら「OK」をクリックします。
画面上の変化はありませんが、予測ができたことを確認します。
新たにページを追加して、テーブル「Lot_sample_test」を表示します。
横にスクロールして右端のカラムを確認すると、下記の予測カラムが新たに追加されています。
※見当たらない場合は、テーブルの「プロパティ」>「カラム」から下記のカラムを追加してください。
以上のように、分類モデリングを活用することで、目的変数に影響を与えている要因の特定や、将来予測を簡単に行えます。
メニューバー「表示」>「分析モデル」を選択することで、作成したモデルの編集や評価・予測が可能です。複数モデルを作成した場合や、モデルの結果ページを消してしまった場合に便利です。

Spotfire活用セミナー
アーカイブ動画を配信中
前の記事
回帰モデリングの使い方次の記事
時間列が文字列で取り込まれた場合【統計分析】最新の記事

