![]()
Spotfire
Data Virtualization
「欲しいデータ」を今すぐ利活用
組織横断のデータ活用基盤ができる
※旧TIBCO Data Virtualization
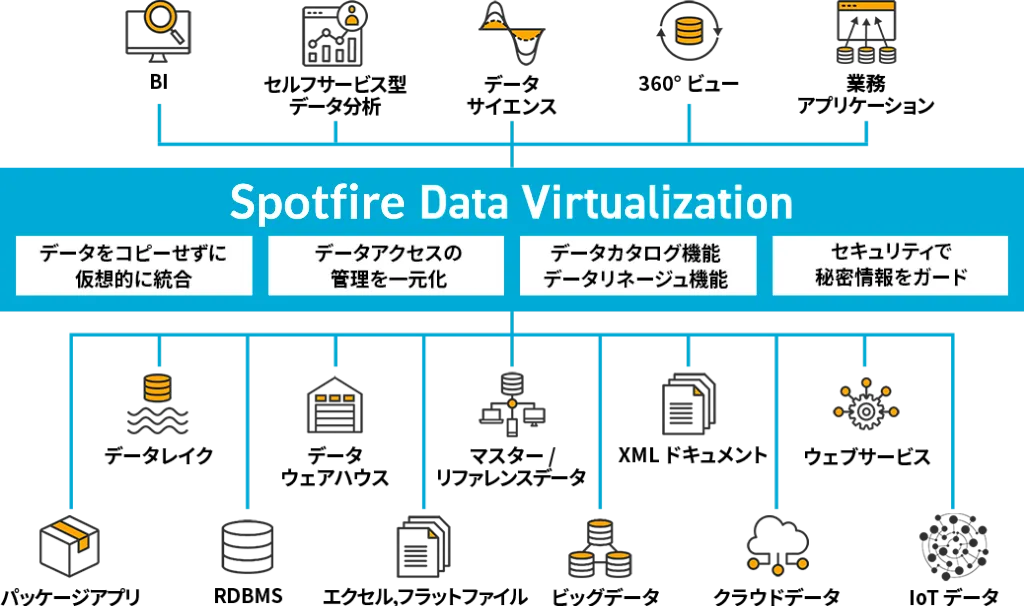
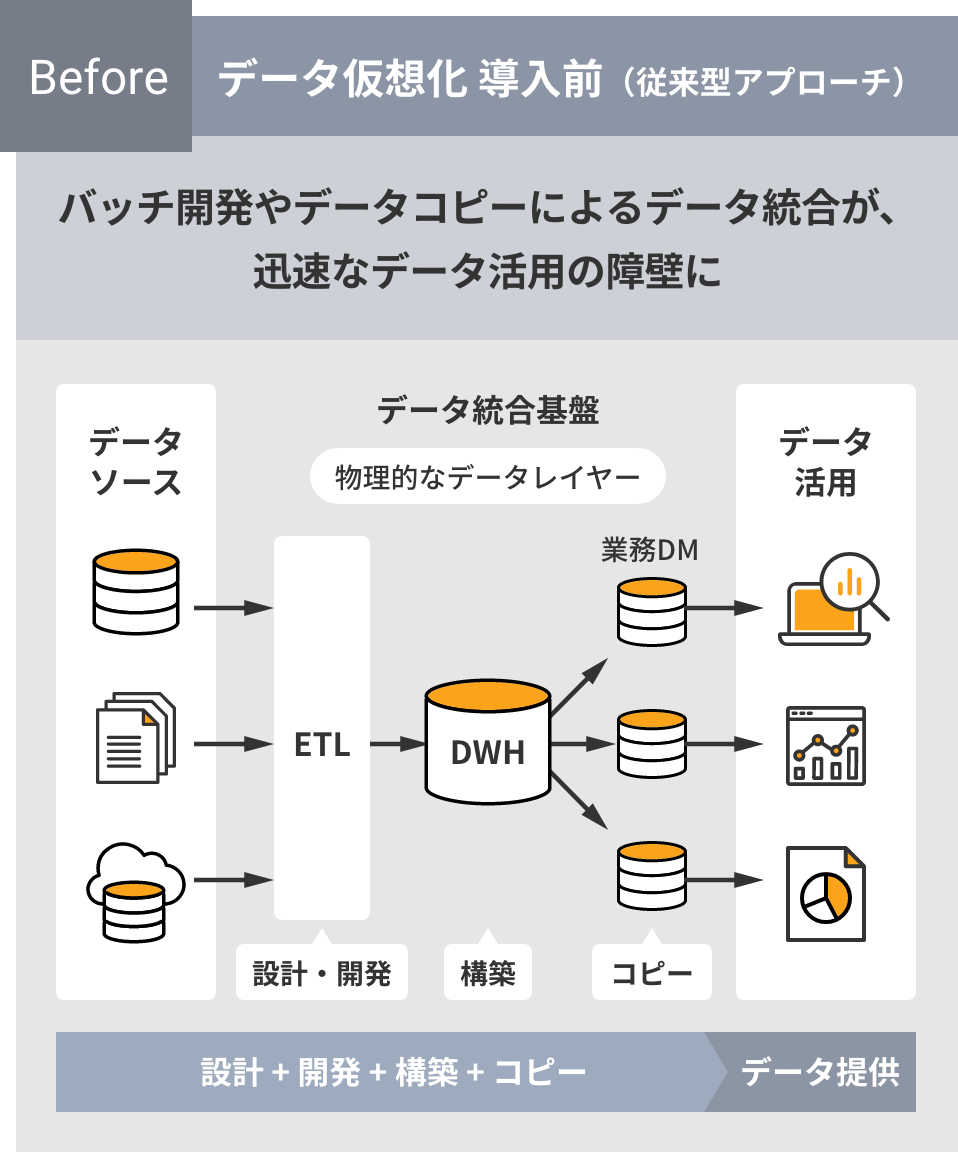
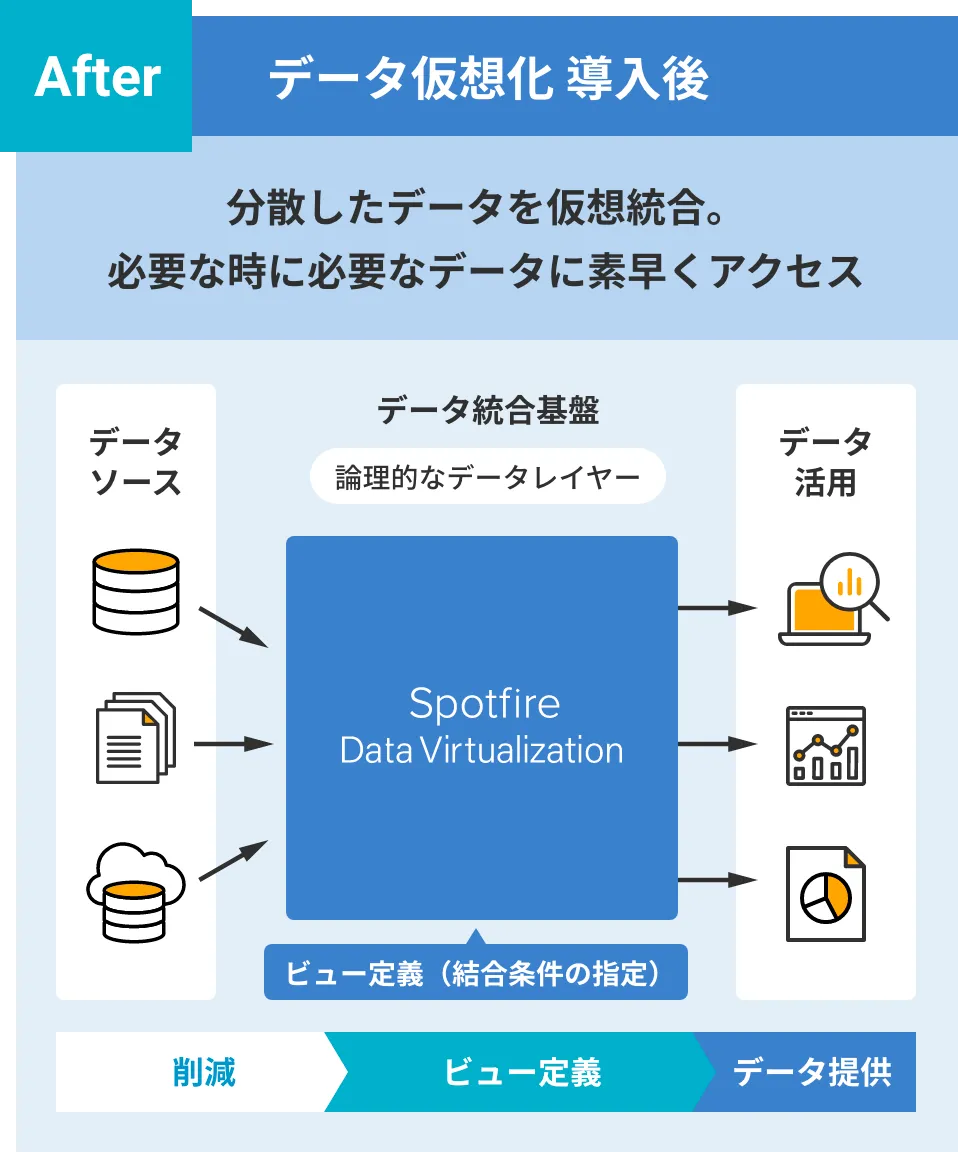
従来のDWHやデータレイクのように、物理的にデータの複製や加工、蓄積などを行うデータ統合手法ではなく、
論理的なデータレイヤーを提供。これにより、データ提供者にかかる設計・開発・構築といった
作業負担や手間を大幅に削減し、データ提供までのリードタイムを短縮します。
従来型 |
データ仮想化 |
|
|---|---|---|
データ |
IT部門や |
ノーコード設定で |
新規追加や |
データ変更の |
柔軟なビューの |
データ鮮度 |
多段階の |
リアルタイム |
データ探索 |
専用ツールが |
データカタログと |
データ |
各ツールで |
リネージュ・ |
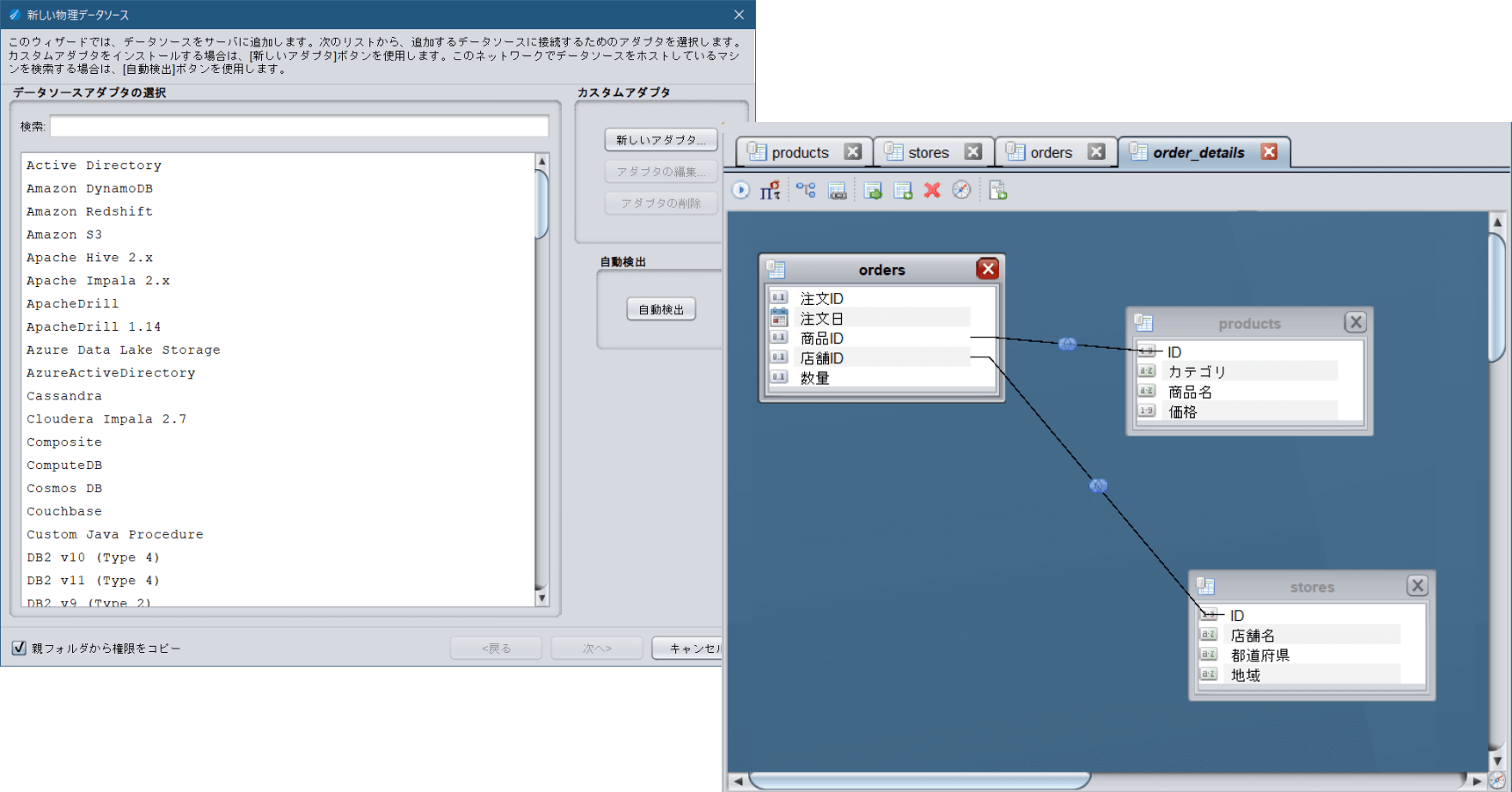
標準搭載アダプターでデータ取得したいシステムへ接続。
ノーコードの直観的操作でデータ統合とビューを作成し、
データ活用ユーザーも確認しながらすぐに使えるデータを取得。
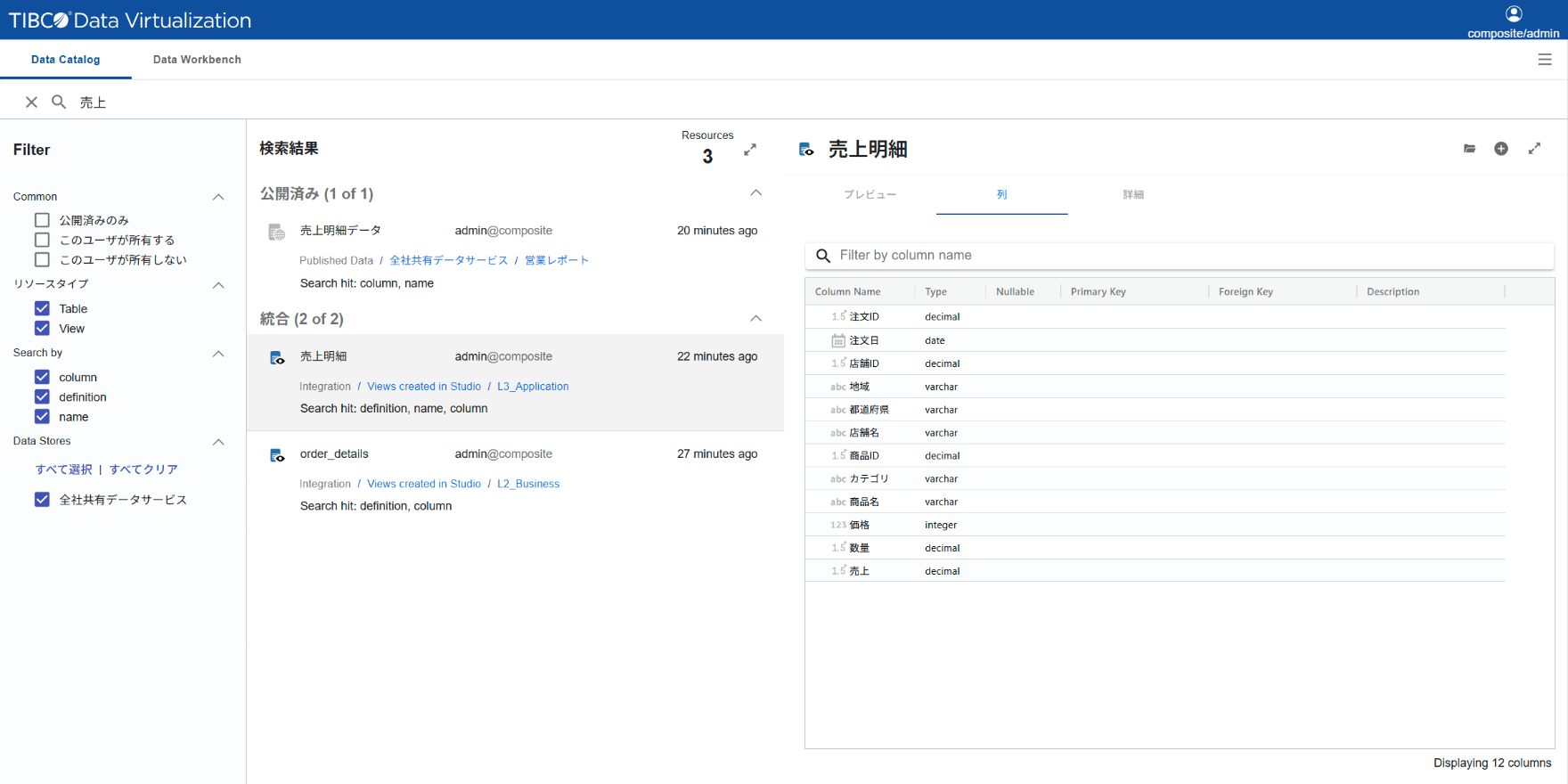
統合元のデータ、新たに統合したデータ、共通化したデータ名称のデータカタログを自動作成。
ユーザーは欲しいデータを検索、すぐに取得、活用。
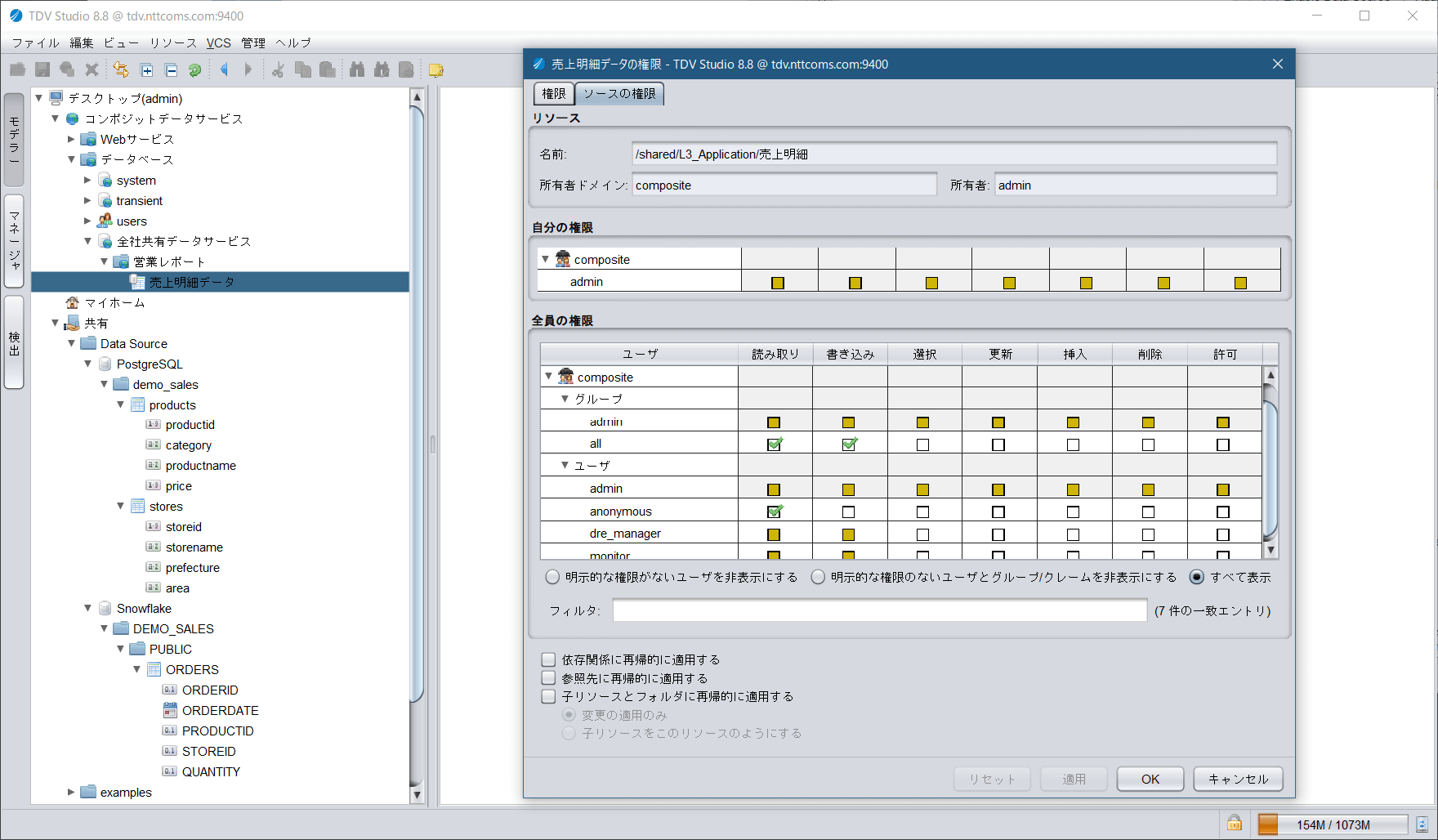
ユーザーまたは組織やグループ毎に、テーブル(ビュー)・
カラム・レコード単位でアクセス権限を設定。
BIや分析ユーザー横断で一元管理。
必要なデータを欲しいときに取得し、
自由に利活用できる
新たなデータ活用アプリや
サービスを
自力でアジャイルに開発できる

ユーザーの新たなデータ要望や改修へ
迅速、
効率的に対応できるようになる
データ管理・監視等を一元化し、
セキュリティ強化と運用コストを削減できる

分散・大量・リアルタイム
データから
仮説ベースの試行錯誤、柔軟な分析ができる
セルフサービスで短期、効率的な
新たなデータ統合と分析ができる

| 対象者 | DX推進・IT企画・経営企画部門向け |
| 概 要 | 本セミナーでは、データ仮想化の技術をどのように活用し データ基盤をつくったのか、実践から得たアプローチ方法を 紹介します。 |

データ仮想化をお考えなら、
まずはお気軽にご相談ください
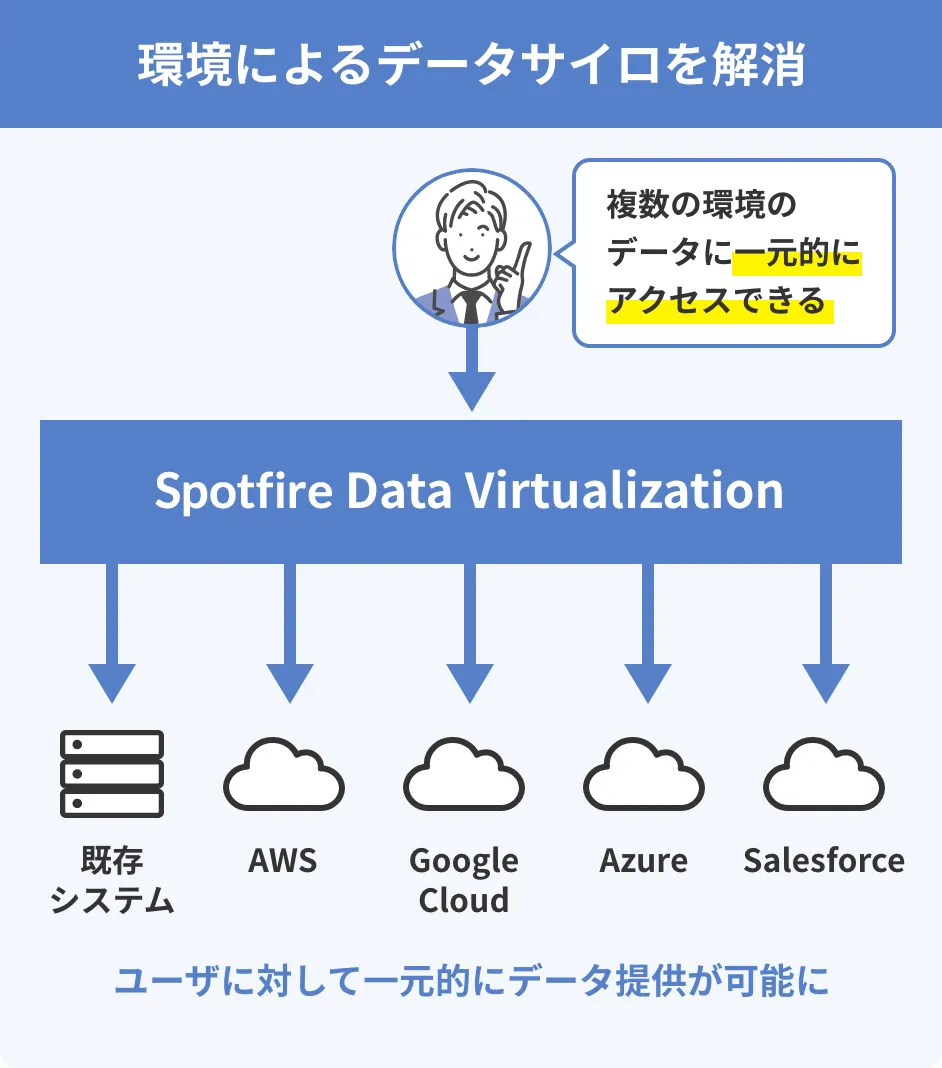
メリット
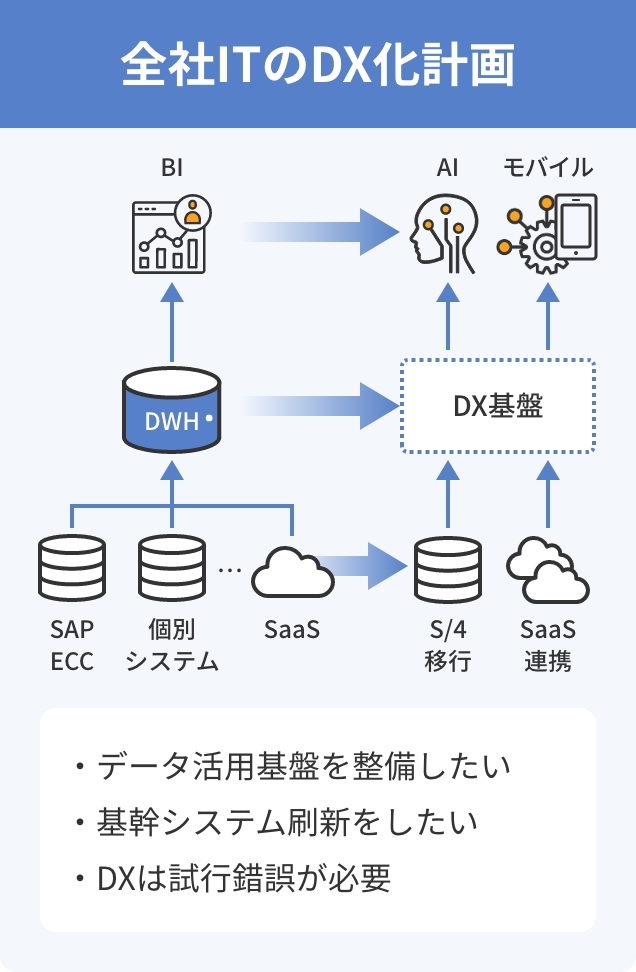
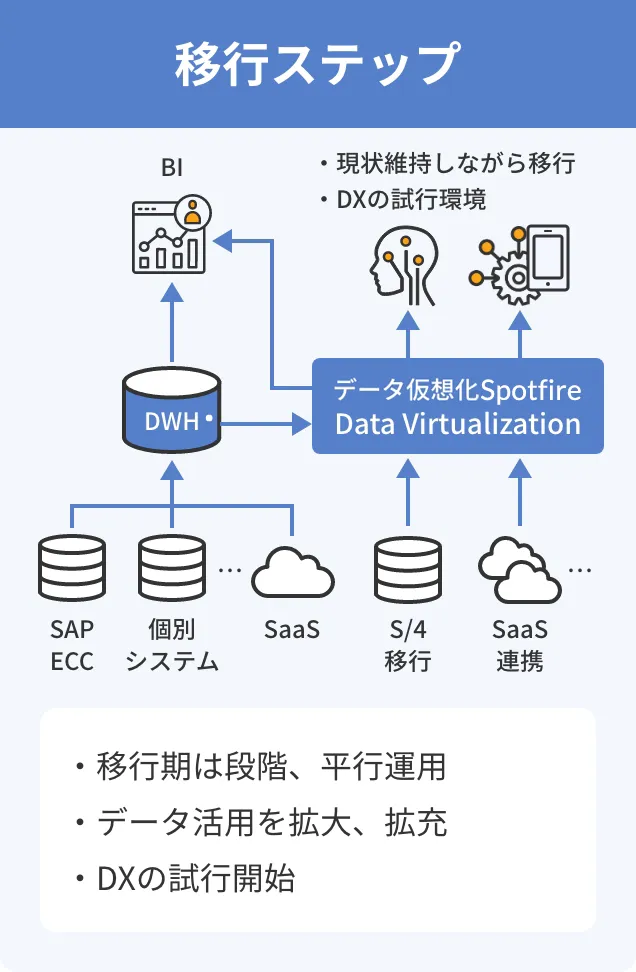
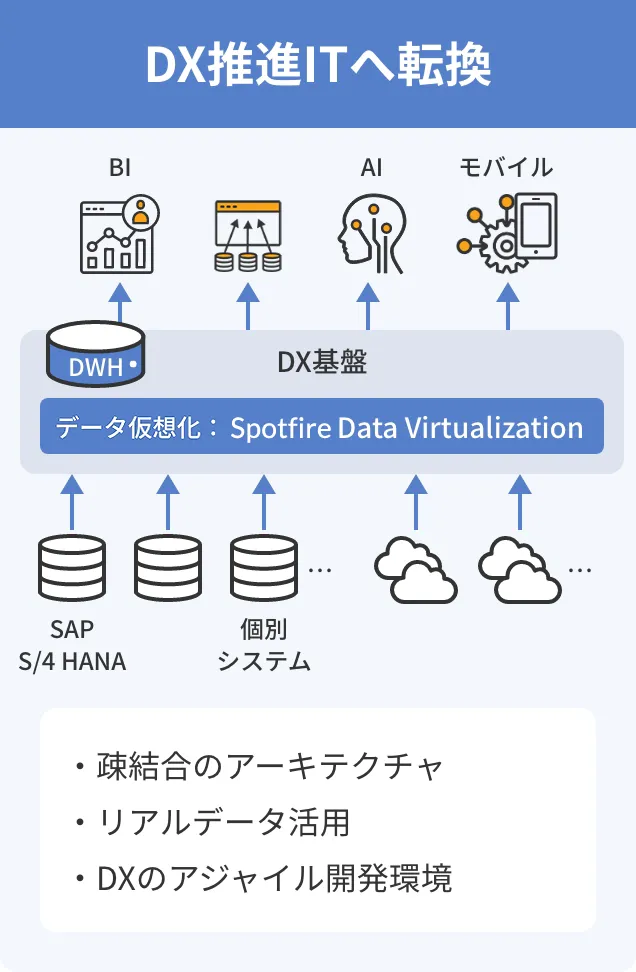
メリット