テキストマイニング
テキストマイニングとは?
テキストマイニングは、テキストデータから有益な情報を抽出する分析手法です。一部の分野ではテキストデータマイニングとも呼ばれ、テキスト分析と類似した点も見られます。テキストマイニングは、コンピュータを使用して様々な情報源からテキストデータを自動的に抽出し、新しい有益な情報を発見したり、価値のある知見を抽出することが可能です。
テキストマイニングは、知識集約型の組織で広く採用されています。主に研究目的で、大量のドキュメントを調査することが含まれます。テキストマイニングは、テキストのビッグデータの深い層に埋もれたパターンを発見し、それに基づいてパターンや関係を明らかにするツールです。
抽出された情報は、構造化データに変換され、さらに分析に活用されたり、クラスター化されたHTMLテーブル、マインドマップ、グラフに分類して表示することができます。また、分析のため、データウェアハウスやデータベース、ビジネスインテリジェンスのダッシュボードに統合されることもあります。
テキストマイニングによって抽出されたデータの応用
テキストマイニングによって抽出されたデータは、様々な分析に応用できます。
- 処方的分析
- 予測分析
- 記述的分析
- 字句解析:単語の頻度分布調査
- タグ付け・アノテーション
- パターン認識
- リンクと関連性
- 可視化
テキストマイニングの目的は、基本的には自然言語処理(NLP)やさまざまな種類のアルゴリズム、分析手法を用いて、テキストをデータに変換し、分析に利用することです。収集した情報の解釈が、このプロセスにおいて重要な部分です。
現在の自然言語処理(NLP)システムの能力
自然言語理解は、機械がテキストや音声を読み取るのを手助けする自然言語処理の最初のステップです。ある意味、これは英語やフランス語、中国語などの実際の言語を理解する人間の能力を模倣しています。
自然言語処理は、自然言語理解と自然言語生成の両方を兼ね備えています。これにより、人間の能力に似た自然言語テキストの生成が可能となります。自然言語処理には、情報を要約したり、会話や対話への参加なども該当します。
自然言語処理はこの10年間で大きく発展し、今後も進化と成長を続けると言われています。AlexaやSiri、Googleの音声検索などの主流製品では、自然言語処理を使用してユーザーの質問や要求を理解し、応答することができるようになりました。
自然言語処理システムは、テキストデータの分析において欠かせない自動化の形態です。その能力は多岐に渡ります。
- 文字通り無制限の量のテキストデータに対して、一貫して偏りのない方法で分析を実行できる
- 高度で複雑な概念を理解できる
- 言語の曖昧さを検出し、関連する事実を抽出し、関係性を特定できる
- 要約ができる
現代におけるテキストマイニングの重要性
現代のビジネスは、リモートワークの広がりや、オンライン空間でのビジネスが発展し、毎分膨大な量のデータを生成しています。このデータは複数のソースから収集され、データウェアハウスやクラウドプラットフォームに格納されています。このように急速に増加する膨大なデータを分析するには、従来の方法やツールでは不十分な場合もあり、企業にとって大きな課題となっています。
テキストマイニングが採用されたもう一つの大きな理由は、ビジネス競争の激化です。競争に勝ち抜くために、企業はより付加価値のあるソリューションを求めています。
こうした背景のもと、テキストマイニングのアプリケーション、ツール、技術が広く利用されるようになりました。テキストマイニングは収集されたデータを活用する方法を提供し、企業の成長を支えています。
テキストマイニングと自然言語処理の連携
テキストマイニングの重要性の一例は、機械学習の文脈で見ることができます。機械学習は広く使用される人工知能の応用分野であり、プログラミングをせず、経験から自動的に学習する能力をシステムに与えます。この技術は、複雑な問題を高い精度で解決することにおいて、人間に匹敵するか、または人間を凌駕することさえあります。
しかし、機械学習が最良の結果を出すためには、トレーニングに使用するデータが適切に整備されている必要があります。利用可能なデータの大部分が非構造化テキストの場合、機械学習のトレーニングは困難となります。電子カルテ、臨床研究データセット、またはフルテキストの科学文献などがこれに該当します。
自然言語処理は、機械学習に使用される高度な予測モデルの学習の基礎となる、構造化データを抽出するための優れたツールです。これにより、上記のようなトレーニングデータを手作業によりアノテーションする必要性が減り、コストを節約することができます。
さらに、テキストマイニングにより、大量の文献やデータの分析が可能となり、パイプラインの早い段階で潜在的な問題を特定することができます。これにより、企業は研究開発リソースを最大限に活用し、後期臨床試験などでこれまでに報告されている既知の失敗を回避することができます。
テキストマイニングの多様性と学際性
テキストマイニングは、本質的に多分野にまたがる分野です。データマイニング、情報検索、機械学習、計算言語学、統計学などのツールを統合し、取り入れています。テキストマイニングは、半構造化または非構造化形式で保存されている自然言語のテキストに関連しています。
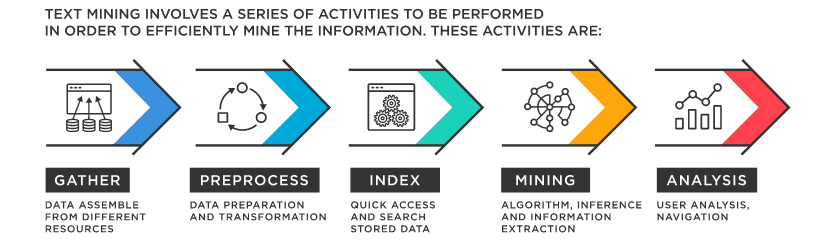
テキストマイニングのプロセス
前処理
- 複数のデータソース(プレーンテキスト、ワードファイル、PDFファイル、ウェブページ、ブログ、メール、ソーシャルメディアなど)から非構造化テキストデータを収集する。
- テキストマイニングツールやアプリケーションを使用してデータを整理し、異常や重複を検出・削除する。データの中から適切な情報のみを抽出・保持し、特定の単語の起源を特定する。
- 上記を分析に適した構造化データに変換する。
分析
- MIS(経営情報システム)を通じてデータ内のパターンを分析する。
- 価値あるインサイトを抽出し、情報を安全なデータベースに移動してトレンド分析を行う。
- インサイトを意思決定に活用する。
テキストマイニングの技法
テキストマイニングでよく使われる効果的な技法を5つご紹介します。
情報抽出
この技法は、非構造化データまたは半構造化データにかかわらず、テキストデータの塊から意味のある情報を抽出するプロセスを指します。エンティティやその属性、それらの関係を識別し、抽出することに焦点を置いています。抽出された情報は、今後のアクセスや検索を容易にするためにデータベースに保存されます。これらの結果の関連性と有効性を評価するために、Precision(適合度)とRecall(再現度)の指標が使用されます。
情報検索
特定の単語やフレーズの集合に基づいて、より具体的に関連するパターンを抽出する技法です。情報検索システムは、アルゴリズムを利用してユーザーの行動を追跡し、関連するデータを収集します。一例として、Google検索エンジンが挙げられます。
カテゴライズ
これは、教師あり学習の一つの形態であり、通常の言語テキストを、その内容に基づいてあらかじめ定義されたトピック群に分類します。システムはテキスト文書を収集し、それらを分析することで、すべての文書に関連するトピックや正しいインデックスを見つけ出します。テキストデータセットから、意味だけでなく、実際の同義語や略語を抽出するため、自然言語処理の一部として共参照プロセスが用いられています。現在、このプロセスは自動化されており、パーソナライズされた広告やスパムのフィルタリングまで、幅広く応用されています。また、ウェブページを階層的に分類する際にも使われており、その用途は多岐にわたります。
クラスタリング
その名の通り、テキストデータベース内の本質的な構造を特定し、それをサブグループ(または、「クラスタ」)に分類して、さらに分析するというものです。これは重要かつスタンダードなテキストマイニング技法です。
クラスタ形成プロセスにおける最大の課題は、お手本となる情報が事前になく、分類もラベル付けもされていないテキストデータから、意味のあるクラスタを作成することです。クラスタ分析はデータ全体の分布を明らかにするために使用されます。また、検出されたクラスタに下流で適用できる他のテキストマイニングアルゴリズムやテクニックの前処理ステップとしても機能します。
要約
テキスト要約とは、エンドユーザーにとって有用な情報を含む特定のテキストの圧縮版を自動生成するプロセスです。要約技術の目的は、テキストデータの複数のソースに目を通し、大量の情報を含むテキストを簡潔な形式でまとめることです。元の文書の全体的な意味や意図は基本的に変更されることはありません。テキスト要約は、決定木、ニューラルネットワーク、群知能、回帰モデルなど、テキスト分類を使用する様々な手法を統合しています。
テキストマイニングの用途と利点
テキストマイニングツールや技法は、学術、医療、企業、ソーシャルメディアプラットフォームなど、現代では様々な業界や分野で導入されています。
リスク分析、評価、リスク管理のためのテキストマイニング
企業が十分なリスク分析を行わずに新製品や新サービスを発売することは珍しくありません。不適切なリスク分析によって、重要な情報やトレンドに遅れをとり、成長の機会を逃したり、ターゲットとなる顧客との関係構築の機会を逃してしまう可能性があります。
テキストマイニングは、通常の業務に組み込むためのリスク管理ソフトウェアのベースとなる機能で、多数のテキストデータソースから情報を照合し、関連するインサイト同士を紐づける役割を担っています。
テキストマイニングを採用することで、企業は現在の市場の動向を常に把握し、適切なタイミングで適切な情報を入手し、潜在的なリスクをタイムリーに把握することができます。これは、リスクを減らし、ビジネス上の意思決定を迅速に行えることを意味しています。
テキストマイニングとテキスト分析による不正検出
テキスト分析とテキストマイニングが用いられているアプリケーションは、保険会社や金融会社にとっては頼みの綱です。保険・金融業界では、データの大部分をテキスト形式で収集しています。このようなテキストデータを構造化し、テキストマイニングツールや技法を使ってテキスト分析にかけることは、不正行為の検出と防止に役立っています。また、テキストマイニングは、保証や保険請求の迅速な処理にも役立ちます。
優れたビジネスインテリジェンスのためのテキストマイニング
様々な業界において、多くの企業は、優れたビジネスインテリジェンスのためにテキストマイニング技術を活用するようになってきました。テキストマイニングにより、顧客や消費者の行動や市場動向に関する深いインサイトが得られます。
また、テキストマイニングは、企業が自社と競合の強み、弱み、機会、リスクを分析し、市場で優位に立つために役立ちます。
テキストマイニングのツールや技術は、マーケティング戦略やキャンペーンがどのように実行されているか、顧客は何を求めているか、購買の嗜好や傾向、市場の移り変わりに関するインサイトももたらします。
テキストマイニング技術を用いたカスタマーサポートの改善
テキストマイニング技術は、顧客体験の向上のため、カスタマーサポート分野における採用が広がっています。自然言語処理がこの分野を牽引しており、企業は、顧客アンケート、フィードバックフォーム、音声通話、電子メール、チャットからのテキストデータをパトロールするテキスト分析ソフトウェアに投資しています。
この分野におけるテキストマイニングとテキスト分析の目的は、電話や問い合わせに対する応答時間を短縮し、顧客からのクレームに対して、より迅速かつ効率的に対応することです。これにより、LTV(顧客生涯価値)の延長や解約の減少、苦情の迅速な解決といったメリットが得られます。
テキストマイニングツールを使ったソーシャルメディア分析
テキストを多用するソーシャルメディアの性質上、テキストマイニングツールは、投稿数、「いいね!」数、コメント数、紹介数、フォロワー傾向の分析という点で本領を発揮します。実際、様々なソーシャルメディアにおける投稿のパフォーマンスを分析するためだけに設計されたテキストマイニングツールがいくつかあります。
ソーシャルメディア上のテキストマイニングは、多くの場合リアルタイムで、自社のブランドやブログなどのオンラインコンテンツと接している多くの人々の反応や行動パターンを理解するための貴重なツールでもあります。
これにより、テキストマイニングとテキスト分析は、ターゲットオーディエンスを虜にしている、その時々のトレンドを活用するのに役立ちます。何が流行っているのか?どのようなコンテンツがユーザーを惹きつけているのか?この情報を有意義に活用できれば、市場シェアを拡大し、売上を伸ばすことにもつながるでしょう。
テキストマイニングのデメリット
テキストマイニングやウェブマイニングの技術自体に問題が生じることはありませんが、個人的な性質が関連するデータセットに適用すると、倫理的な懸念が生じる可能性があります。個人の医療記録に対するテキストマイニングの使用や、グループプロファイルの作成などがこれに該当します。プライバシー問題は、テキストマイニングの不謹慎な使用と関連して、非常に批判の多い倫理的問題となっています。
また、企業はある目的のためにテキストマイニングを行いますが、そのデータを別の、明言されていない、あるいは公表されていない目的のために使用する可能性もあります。個人データが商品になってしまうこの世界では、このような悪用は個人のプライバシーに対する大きな脅威となります。
それにもかかわらず、テキストマイニングは依然として非常に強力なツールであり、多くの企業が日常業務の合理化から戦略的なビジネス上の意思決定まで、あらゆることに活用することができます。
関連製品
-
Spotfire®組織全体でのデータ分析・活用を実現するオールインワンのデータ分析ソフトウェア詳しく見る


