クラスター分析とは? メリットや実際の活用例を紹介
1.クラスター分析とは
クラスター分析とは
クラスター分析とは、個々のデータから似ているデータ同士をグルーピングする分析手法です。
クラスター分析ではグルーピングされたデータの集まりをクラスター(集団)と表現します。
クラスターの数に決まりはなく、必要に応じて任意の数のクラスターにグループ分けすることが可能です。
学習手法としては目的変数を設定しない教師なし学習に分類されます。
クラスター分析を行うと、各データが以下のように特定のクラスターに分類されます。
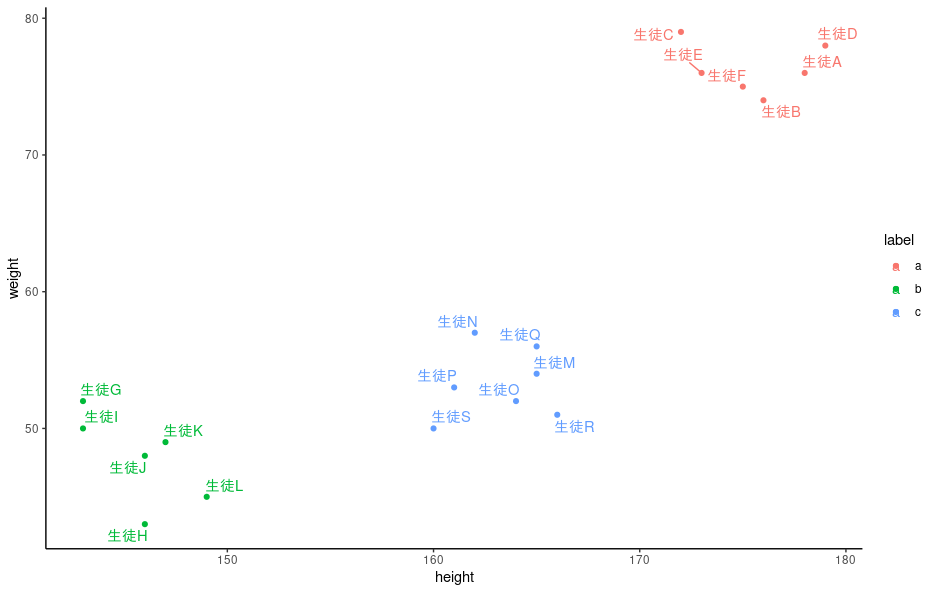
各生徒の身長と体重のデータがきれいに3つのグループに分類されています。
クラスター分析のメリット
クラスター分析の最大のメリットは、大量のデータを単純化して理解、考察しやすくしてくれるところです。
複数の似たデータを集約して1つのクラスターとして扱えるため、各クラスターの特性を分析するだけでデータのおおまかな特性を把握することが出来ます。
簡単な例を使って説明していきましょう。
ある学校の生徒達の学力にはどのような特性があるか分析することになったとしましょう。
手元に使えそうなデータは、各生徒が先日受けたテストの5教科分(国語、数学、英語、理科、社会)の点数があります。
しかしデータ量が多すぎて、この状態からはまだ何も分かりません。
そこで生徒の各教科の点数の取り方はいくつかの傾向に分かれるだろうと推察して、クラスター分析を使って分析してみることにしました。
まずはテストの点数を元にクラスター分析で各生徒を4クラスターに分類しました。
その後クラスター毎に各教科の平均点を算出すると、以下の結果になりました。

この結果から各クラスターの特徴は以下のように考察できます。
クラスター1→全体的に点数が高い
クラスター2→数学と理科の点数が高く、国語と社会の点数が低い
クラスター3→国語と社会の点数が高く、数学と理科の点数が低い
クラスター4→全体的に点数が低い
今回の分析結果から、生徒は「総合学力が高い生徒」、「総合学力が低い生徒」、「理系科目が得意な生徒」、「文系科目が得意な生徒」の4種類のタイプに分かれる傾向があることが判明しました。
このようにクラスター分析を行うことで、複雑なデータを単純化して考察することができるようになります。
2.クラスター分析の種類
クラスター分析には2種類の方法がある
クラスター分析には”階層性クラスター分析”と”非階層性クラスター分析”の2種類の方法があります。
それぞれのクラスター分析は、クラスターを作成する方法が異なります。
どちらの分析にもメリットとデメリットがあり、目的に応じて使い分けます。
各クラスター分析の特徴とメリット、デメリットを解説していきましょう。
階層性クラスター分析
階層性クラスター分析は以下のようなデンドログラム(樹形図)を作成してクラスターを作成していくクラスター分析です。
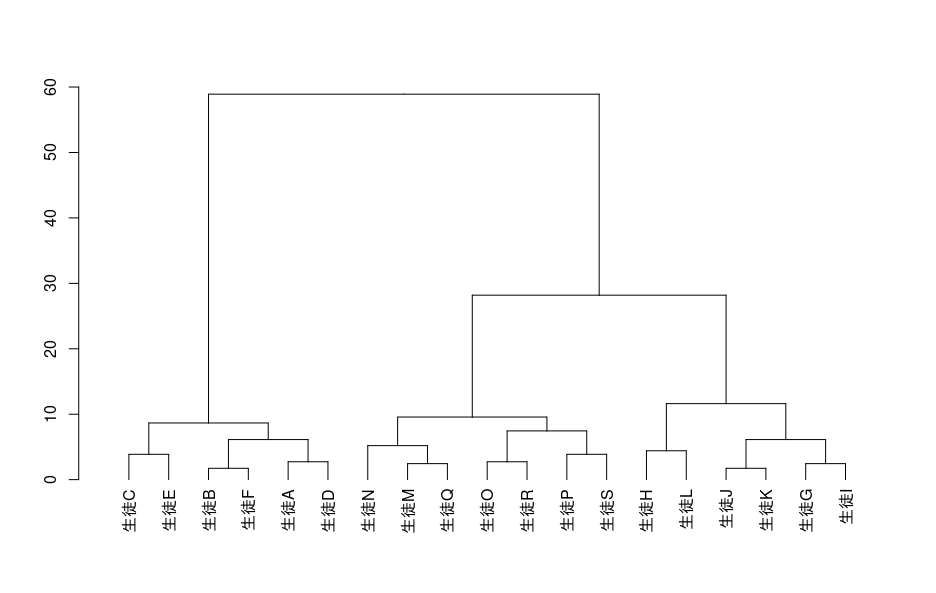
階層性クラスター分析のメリットは2つあります。
1つ目のメリットは、どのようにクラスターが作られているか、視覚的に把握しやすいことです。
デンドログラムを確認すると、下から上に向けてデータ同士が統合され、最初は小さかったクラスターが徐々に大きいクラスターにまとめられていることが分かります。
2つ目のメリットは、最初にクラスター数を指定する必要がない点です。
分析の最初の段階では、いくつのクラスターに分類するのが最適か、判断が難しいケースがしばしばあります。
そのような場合でもデンドログラムを確認して、任意のラインで区切ることで適切なクラスター数を決めることができます。
一方で階層性クラスター分析のデメリットは、この後紹介する非階層性クラスター分析と比べて計算に時間がかかることです。
そのためデータ数が多くなると、困る場合が出てきます。
以上のメリットとデメリットから階層性クラスター分析は以下のケースに向いています。
- デンドログラムを確認したい
- クラスター数が決まっていない
- データ数がそこまで多くない(1万以下が目安)
非階層性クラスター分析
非階層性クラスター分析は、あらかじめ定めたクラスター数でクラスターを作成します。
非階層性クラスター分析ではデンドログラムは作成されず、各データがそれぞれどのクラスターに属するかのみが分かります。
非階層性クラスター分析のメリットは、計算時間がかからないことです。
特に10万を超えるようなデータに対してクラスター分析を実行する際に、役立ちます。
一方で非階層性クラスター分析のデメリットは、あらかじめクラスター数を定めなければならない点です。
適切なクラスター数がどれくらいか分からない場合だと、いくつに設定すべきか迷ってしまします。
反対にあらかじめいくつのクラスターに分類するか決めている場合は、計算速度の速い階層性クラスター分析が向いています。
以上のメリットとデメリットから非階層性クラスター分析は以下のケースに向いています。
(樹形図)を作成してクラスターを作成していくクラスター分析です。
- クラスター数が決まっている
- データ数が多い(10万以上)
3.クラスター分析の活用事例
例①顧客のグルーピング
ある会社が化粧品について顧客満足度調査を実施しました。
20代以上の女性を対象にアンケート調査にて化粧品利用の満足度や意向を調査し、加えて化粧品利用者の傾向を知るために15項目の化粧品に対する意識調査も実施しました。
利用者の数パターンの傾向を知り、傾向毎に利用者の満足度と意向を知ることが今回の分析の目的です。
15項目の意識調査の結果を分析するために、まずは15項目のデータを因子分析であらかじめ「情報分析因子」と「エコ・自然派因子」、「無関心・無頓着因子」の3つの因子を抽出しました。
その後クラスター分析にて各因子の得点が近い利用者のグルーピングを実施し、利用者を3グループにグループ分けしました。
クラスター分析は、すでに3グループに分けることが決まっていたため非階層性クラスター分析を実施しました。
クラスター別の因子得点は以下のようになりました。
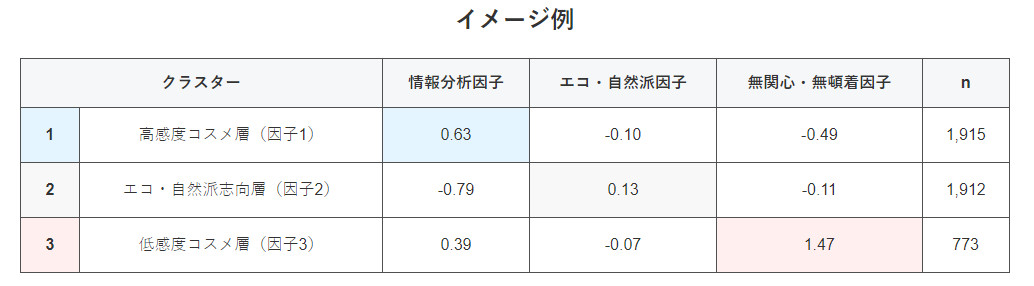
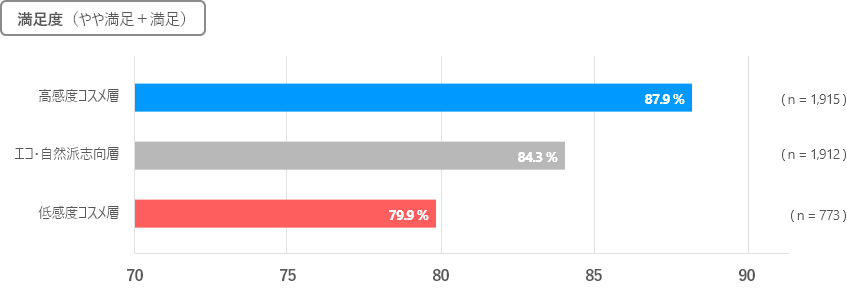
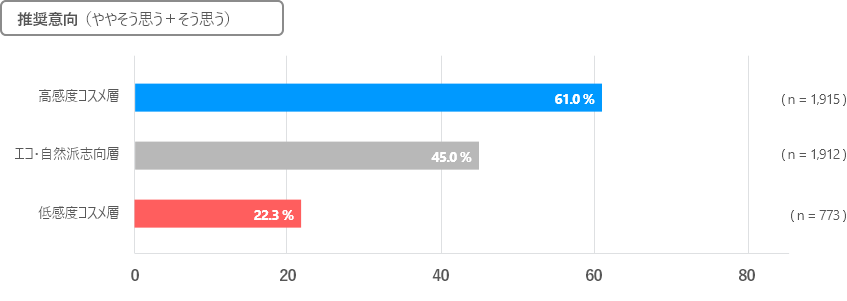
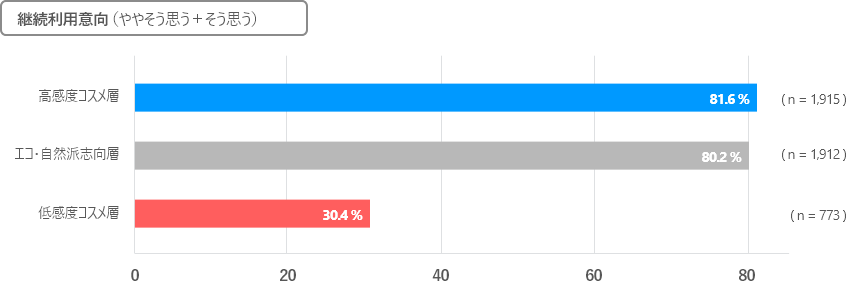
またクラスター別に、現在利用している化粧品に対する満足度・継続利用意向・推奨意向をみてみると、すべてにおいて高感度コスメ層が最も高い結果となりました(87.9%、81.6%、61.0%)。
一方で低感度コスメ層は、継続利用意向が30.4%と低く、知人・友人に奨める割合も2割に留まっていました。
クラスター分析を実施することで、利用者の傾向をより捉えやすくなり、満足度や意向の特徴を把握できました。
この例のように、クラスター分析は因子分析などと組み合わせて使うことも可能です。
例②アンケートデータの分析
ある塾が生徒の特徴を捉えるため、性格や勉強へのやる気など8項目のアンケート調査を実施することにしました。
「真面目な性格で勉強へのやる気がある子」や「不真面目な性格でやる気も少ない子」など生徒はいくつかのパターンに分かれることが予測されます。
そこでまずはクラスター分析を使用することで、生徒の性格ややる気などには何パターンの傾向があり、パターン毎にそれぞれどのような特徴があるのか調査してみることにしました。
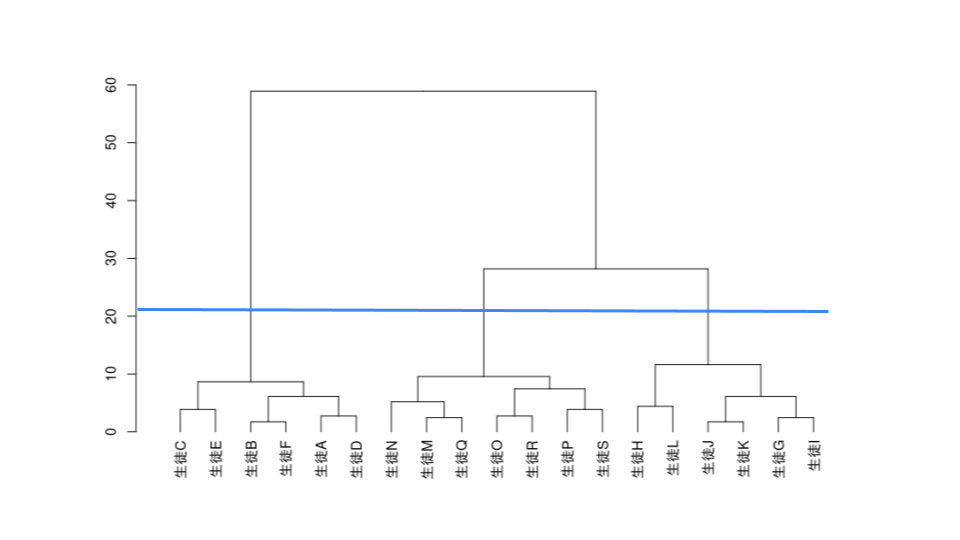
適切なクラスター数が不明であったため、階層性クラスター分析を実施してデンドログラムから適切なクラスター数を探索することにしました。
分析の結果、以下のようなデンドログラムが生成されました。
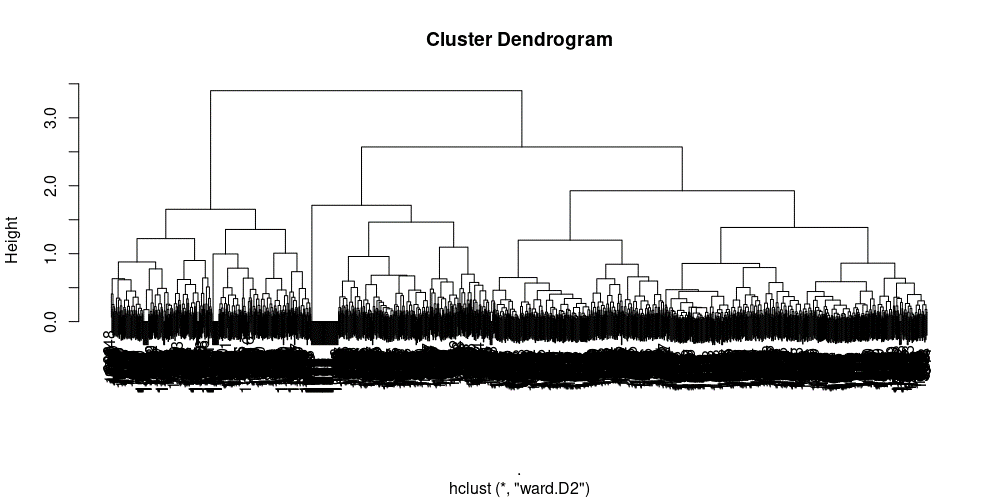
クラスター毎にサンプル数の偏りが少なく、3~7程度のクラスター数になると良いと考え、以下のラインで4つのクラスターに生徒を分類することにしました。
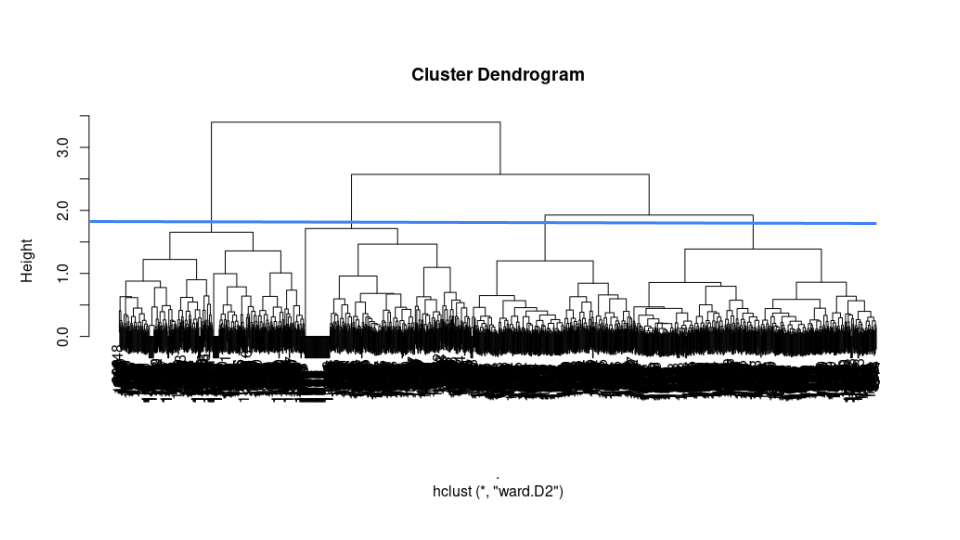
またクラスター毎にアンケート項目の平均点を集計すると、以下のような特徴が分かってきました。

今回の分析結果から、生徒の性格と勉強へのやる気の傾向はおおまかに以下の4パターンの特徴に分類することができました。
クラスター1:受験への意欲や主体性が強く、やる気のある生徒
クラスター2:受験への意欲はあり真面目だが、勉強のやる気がいまいち出ない生徒
クラスター3:受験への意欲が低く勉強も楽しくないため、勉強のやる気がない生徒
クラスター4:受験への意欲は低いが、主体性があり勉強が楽しいため勉強のやる気がある生徒
今後はパターン毎に勉強の成績や伸び率を分析したり、パターン毎に指導の方法を変えてみたり、様々な応用が出来そうです。
4.クラスター分析の注意点
データの類似性を判断する方法は数パターン存在する
クラスター分析では、各データが似ているかどうかを判断するための基準がいくつかあります。
代表的なものはユークリッド距離と呼ばれ、以下の図のように点(データ)と点(データ)の直線距離が近いものを似ているデータと判断して、同じクラスターに分類します。
ユークリッド距離はクラスター分析を行う際の第一選択としてよく使用されます。
他にもマハラノビス距離やマンハッタン距離、コサイン類似度など様々な基準があるため、分析時にどの基準を使用するかによって結果が変わることも多々あります。
どの基準が良いかは解析するデータによって異なるため、解析する前の段階ではどの基準が最適か分かりません。
そのためうまく分類が出来ない時は基準を変えてみるなど、分析を実施する上で試行錯誤が必要になります。
各クラスターの特徴は自分で考察しなければならない
クラスター分析によってグルーピングされた各クラスターがどのような特徴、意味を持っているかは、クラスター分析を実行した後に自分自身で考察しなければなりません。
クラスター分析は似ているデータをまとめてクラスターを作ることしかできないからです。
クラスター分析はあらかじめ指定した基準によってデータの類似度を判断していることを先ほど説明しました。
クラスター分析は基本的にデータ間の類似度を計算し、類似度が近い者同士をまとめていくことしか行いません。
つまり最終的に作成されたクラスターがどのような意味を持つかまでは考慮されていません。
そのため作成されたクラスターの意味は、分析結果を見た人の判断に委ねられることになります。
どうしても主観が入ってしまう部分ですので、各クラスターの意味を考察する際は複数人に意見をもらうなど、偏った考えにならないよう注意が必要です。
各クラスターの特徴を探索する際は、クラスター毎にデータを集計していく方法が一般的です。
必ずしもきれいに分類できるとは限らない
先ほどご説明したようにクラスター分析は作成したクラスターの意味や特徴を考慮しません。
そのためクラスター分析できれいに分類できないこともよくあります。
クラスター毎にデータを集計しても想定していたパターンに分類されていないケースや、全てのクラスターに全く特徴がないケースなどです。
その場合は”データの類似度を決める基準を変える””クラスター数を変えてみる”などといった対策が必要です。
そもそもクラスター分析が合わないデータであった可能性もあるため、上手くいかない時は因子分析などの他の分析手法も検討するようにしましょう。
5.まとめ
最後におさらいをしましょう。
- クラスター分析とは、個々のデータから似ているデータ同士をグルーピングする分析手法(教師なし学習)
- クラスター分析の最大のメリットは、大量のデータを単純化して理解、考察しやすくしてくれるところ
- クラスター分析には”階層性クラスター分析”と”非階層性クラスター分析”の2種類の方法があり、目的に応じて使い分ける
- クラスター分析は行動ログやアンケートデータなどを使用してデータの傾向を掴む際によく使用される
- クラスター分析はデータの類似度を算出する基準が複数存在し、どれが最適かはデータによって変わる
- クラスター分析によって生成された各クラスターの特徴や意味は、自分で考察しなければならない
クラスター分析は大量のデータから特定の傾向を得たい場合に使用され、活用できる場面は幅広くあります。
生データを見ているだけでは気づかない新しい発見があることもしばしばありますので、是非一度お試しいただければと思います。
複雑だと思っていたことが実は単純な数パターンの集まりでしかなかった、なんてことがあるかも知れません。
最後までお読みいただきありがとうございました。
