回帰分析の具体例から活用方法を解説
1.回帰分析とは
回帰分析とはある要素とある要素の関係性を以下のような回帰式という式に当てはめる分析です。
“(要素A)=(要素B)×係数+切片+誤差”
簡単な例を挙げましょう。
親の身長と子供の身長の関係性を検証することになりました。
まずは親の身長と子供の身長の相関を確かめるため散布図を作成しました。
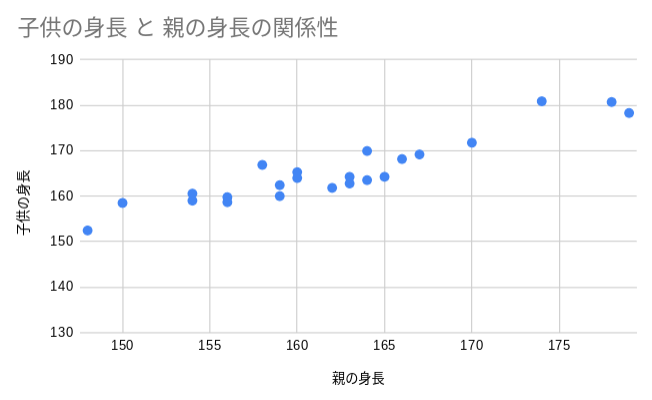
x軸は親の身長、y軸は子供の身長です。
どうやら親と子供の身長には強い相関がありそうです。
次にいよいよ回帰分析を実行してみましょう。
子供の身長は親の身長の影響を遺伝的に受けるため、以下のような回帰式になります。
(子供の身長)=(親の身長)×回帰係数+切片+誤差
回帰係数は親の身長が子供の身長にどのくらい影響するか(直線の傾き)を示し、切片は直線の位置を示します。
実際のデータは必ず理論値とのズレが生じるため、そのズレを誤差として示しています。
回帰分析の結果、回帰係数と切片は以下のようになりました。
(子供の身長)=(親の身長)×0.9+20+誤差
どうやら親の身長の大半は子供の身長にも受け継がれるようですね。
この回帰式(直線)を先ほどの散布図に追加すると以下のようになります。
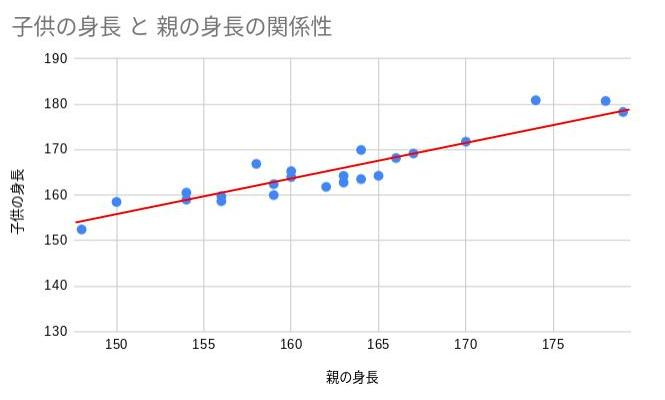
直線が点の密集しているところのちょうど中間を通るように引かれていますね。
この回帰式を元に考えると、親の身長が160cmの場合、子供の身長の理論値は164cmということになりますね。
このように回帰式はある要素とある要素の関係を簡単な式で表したものです。
ちなみに回帰式で説明される要素のことを目的変数(従属変数)と表現し、目的変数を説明する要素のことを説明変数(独立変数)と表現します。
まとめると回帰分析は、回帰式を用いることで目的変数と説明変数の関係性を明らかにする分析です。
2.代表的な回帰分析
単回帰分析
単回帰分析は、1つの目的変数に対して説明変数が1つしかない回帰分析のことです。
先ほどの例も単回帰分析でした。
ある要素とある要素の関係性をシンプルに確認したい時に使われる回帰分析です。
重回帰分析
重回帰分析は、1つの目的変数に対して説明変数が複数ある回帰分析のことです。
そのため回帰式は以下のような形になります。
目的変数=(説明変数1)×(偏回帰係数1)+(説明変数2)×(偏回帰係数2)+...+誤差
重回帰分析の場合は回帰係数ではなく、偏回帰係数と表現します。
重回帰分析はある要素に対して、複数の要素がそれぞれどのように関係しているのか検証する際に、よく使われます。
回帰分析の中では最も有名な手法です。
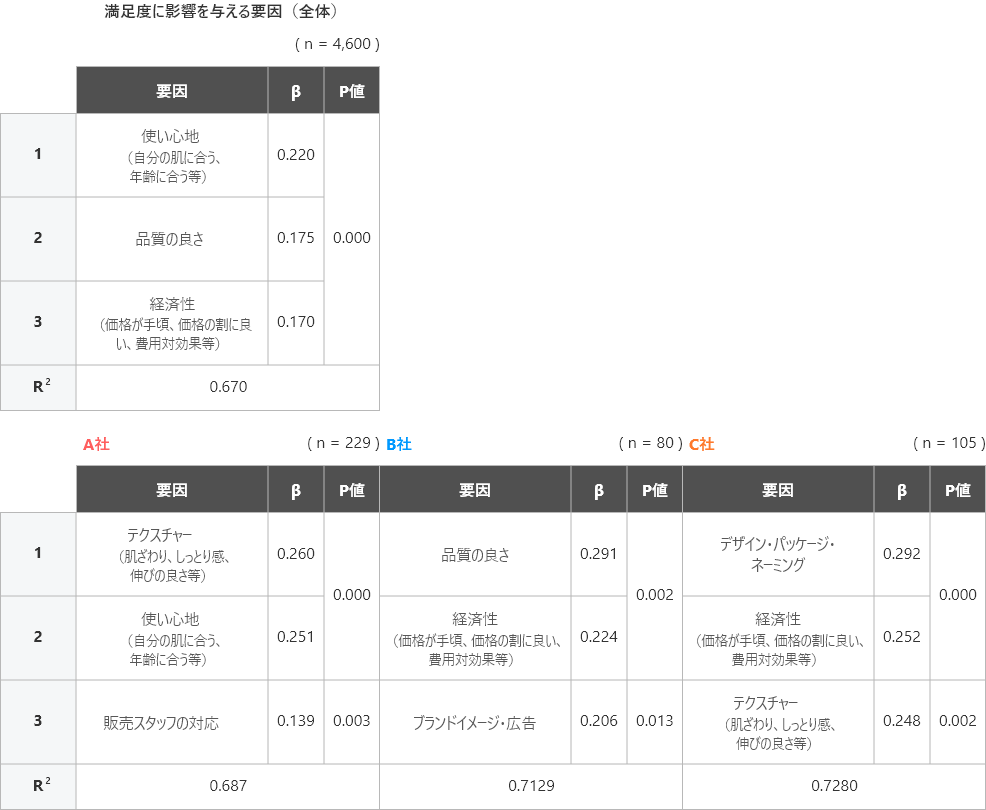
重回帰分析の結果は以下のようになり、p値と回帰係数(β)、決定係数(R2)が算出されます。
それぞれの値の解釈と活用方法については後ほどご説明します。
ロジスティック回帰分析
重回帰分析と同様に、1つの目的変数に対して説明変数が複数ある回帰分析のことです。
重回帰分析との違いは、目的変数が連続値ではなく2値である点です。
例を挙げると、目的変数が年齢や身長のような連続値は重回帰分析を使いますが、性別や配偶者の有無のような2値で表せる変数はロジスティック回帰分析を使います。
目的変数が2値変数であることはよくあるため、重回帰分析と並んで使用頻度が高い回帰分析です。
3.回帰分析から分かること
どの要素が関係しているか(p値)
回帰分析結果の中のp値をみることで、どの説明変数が目的変数に影響しているのか知ることができます。
基本的にはp値が0.05を下回っている変数は目的変数に影響しており、p値が0.05以上の変数は目的変数に影響しているとは言い切れないと解釈します。
p値が0.05以上であったとしても”影響していない”と断言できるわけではなく、あくまでも” 影響しているとは言い切れない”という意味であることに注意しましょう。
反対にp値が0.05以下の変数は、今回解析したデータからは”影響している”と言い切ることができます。
p値が有意水準(今回は0.05)を下回った場合、統計学では「ある説明変数が目的変数に有意に影響している」と表現します。
ただし有意に影響していたとしてもあくまでも今回のデータ分析に基づく理論上の話であり、データが変われば異なる結果が出ることがあることも留意しておきましょう。
回帰分析からどの要素が目的変数と関係しているのか知りたい時は、回帰分析結果のp値が0.05を下回っている要素をみれば、確認することができます。
各要素がどれくらい影響を与えているか(偏回帰係数)
回帰分析結果の偏回帰係数(単回帰分析の場合は回帰係数)をみることで、どの説明変数が目的変数に影響しているのか知ることができます。
この偏回帰係数は、”その説明変数の値が1増えた時に目的変数がどれくらい増える(または減る)か”を表しています。
つまり偏回帰係数が5である変数の場合、その変数が1増えれば目的変数が5増えるという意味になります。
また他の変数と比較してどの説明変数が目的変数に影響を与えているのか知りたい場合は、データを事前に標準化してから回帰分析を実行します。
データを標準化することで変数間の尺度がそろうため、説明変数同士の比較が可能となります。
標準化されたデータの偏回帰係数のことを標準化偏回帰係数と呼び、通常の偏回帰係数と区別します。
標準化偏回帰係数の絶対値が大きければ大きいほど目的変数への影響が強いと解釈します。
例えば、変数Aと変数Bの標準化偏回帰係数がそれぞれ0.5と-0.6であった場合、”変数Bの方が目的変数に強く影響しており、変数Bが増えれば増えるほど目的変数は減少する”と解釈します。
まとめると、偏回帰係数はその説明変数が目的変数にどれくらい影響するか、標準化偏回帰係数はその説明変数が他の変数と比べてどれくらい目的変数に影響するかを意味します。
偏回帰係数と標準化偏回帰係数は解釈の仕方が変わってくるため、結果を見る時は注意しましょう。
作成した回帰式の妥当性(決定係数)
回帰分析結果の決定係数をみることで、今回使用した説明変数全体が目的変数をどれだけ説明しているのか知ることができます。
決定係数は最大が1、最小が0となり、完璧な回帰式の決定係数は1となります。
ただ実際のデータは必ず誤差が生じますので、決定係数が1になることはありません。
基本的には決定係数が0.5の場合、今回使用した説明変数全体で目的変数の50%を説明できていると解釈します。
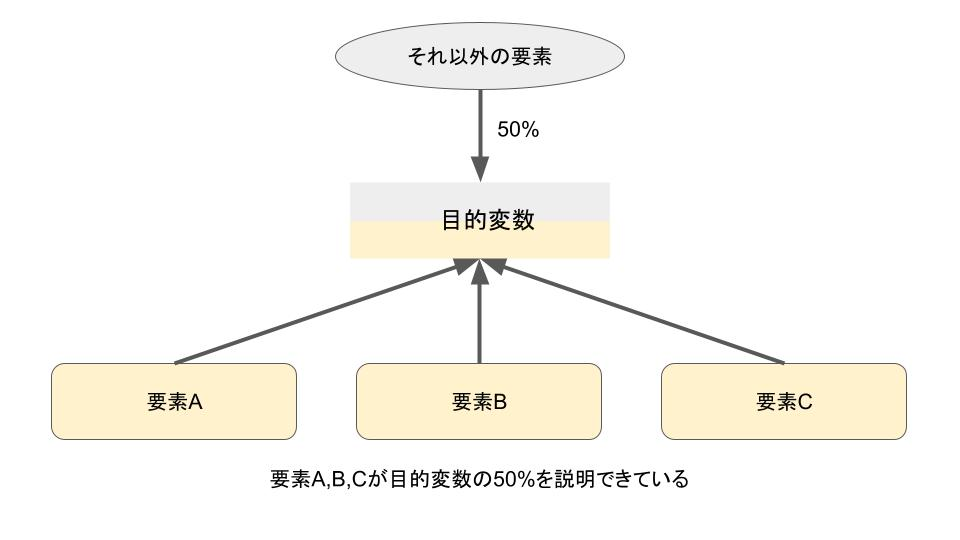
解析するジャンルやデータにもよりますが、決定係数が0.4を超えればそれなりに良好なモデルであり、0.6を超えればかなり良好なモデルだと言えます。
決定係数が低すぎる場合は、説明変数が目的変数を十分に説明できていないため、使う説明変数の再考が必要になります。
4.回帰分析の活用例
マーケティング施策の分析
ある会社が自社製品の売上アップのため、次に打つべき施策を考えています。
候補として上がっているのは広告費の増加や製品価格の見直し、お得キャンペーンの実施の3つです。
幸いその会社は昔からデータを蓄積してきていたため、それぞれの施策の過去の効果が分かっています。
そこで広告費(万円)、製品価格(千円)、キャンペーン(有無)が売上(万円)にどのように影響しているか、重回帰分析を行うことにしました。
分析結果は以下のようになりました。
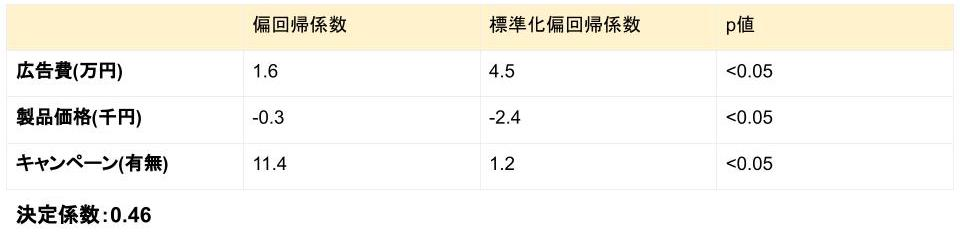
最初に決定係数を確認してみると、決定係数は0.46ですのでまずまずのモデルだと言えそうです。
またp値は全て0.05を下回っていますので、どの変数も売上に関係があると考えてよさそうです。
次に偏回帰係数をみると、広告費を1万円増やせば売上は1万6千円増え、製品価格を千円上げると売上は3千円下がってしまうようです。
キャンペーンを実施すると11万4千円の売上が上がるようです。
偏回帰係数だけをみると一見キャンペーンの実施が良さそうに見えますが、どの施策が一番効果的か標準化偏回帰係数をみて確認しました。
標準化偏回帰係数をみると、売上に一番影響を与えているのは広告費のようです。
このことから優先順位としては広告費を増やすことが1番重要になってきそうだと仮説を作ることができました。
もちろん重回帰分析は過去のデータからの理論上の値であるため、全くこの通りになることはありません。
しかし重回帰分析によって一つの指針を得ることができました。
5.回帰分析を実施する際の注意点
回帰分析は非常に便利ですが、いくつか注意点があります。
多重共線性に注意する
重回帰分析を実行する際は、相関係数が0.9を超えるような相関が強い変数を一緒に説明変数に加えてはいけません。
もしそれらを説明変数に加えてしまうと、分析結果が不安定になり正しい結果が得られないという問題が生じます。
この現象のことを”多重共線性が生じている”と言います。
多重共線性が生じないように事前に変数間の相関を確認しておき、”片方の変数を除く”または”双方の変数を合わせて一つの変数にする”などの対策が必要になります。
解析初心者の方が、多重共線性のことを知らずに失敗するケースがよくありますので、注意しましょう。
説明変数の数
重回帰分析に投入してもよい説明変数の数は”データ総数÷15”までが目安です。
データ総数に対して説明変数の数が多すぎると、実際の値よりも理論上の値が高く出すぎてしまうという問題が生じます。
この問題の生じていることを、”モデルが過学習している”と表現します。
過学習したモデルの結果を鵜呑みにしてしまうと、予想していた結果と違う結果になってしまうリスクがあります。
そのためデータ数に対して説明変数の数が多すぎないか、注意して解析するようにしましょう。
もし説明変数が多すぎる場合は、”データ総数を増やす”または”説明変数を削る”などの対策が必要になります。
これも解析初心者の方がよくやってしまう失敗ですので、上記の多重共線性と合わせて覚えておきましょう。
線形性を仮定できない要素には対応できない
回帰分析は線形性を仮定しているモデルですので、線形性を仮定できない変数には対応出来ません。
線形性とは、説明変数が上がれば目的変数も直線的に増加または減少することです。
たとえば一定の値までは増加するが、その値を超えると減少するような説明変数や、指数関数的に目的変数が増加していくような説明変数は通常の回帰分析で対応できません。
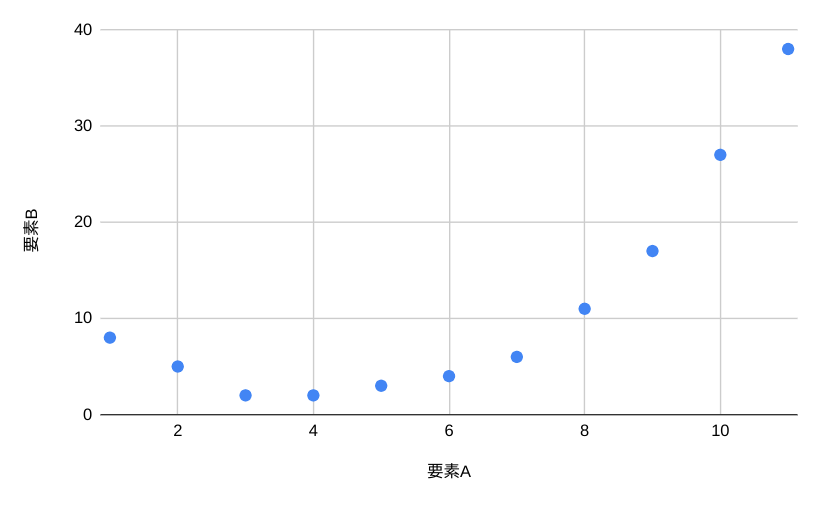
このような変数がある場合は、多項式回帰分析という特殊な回帰分析を使用するか、説明変数をカテゴリー化するなどして線形の形状に変換する必要があります。
線形性を仮定できない変数を重回帰分析で解析すると、本当は関係があるのに関係していないという結果が出てしまうため注意しておきましょう。
回帰係数と相関係数の違い
回帰係数と相関係数はどちらも変数と変数の関係性を示している点でよく似ています。
しかし回帰係数と相関係数は数値の解釈が異なるため注意が必要です。
回帰係数:説明変数が1増えた際に目的変数にどれくらい影響を与えるか示す値
相関係数:説明変数と目的変数の相関の強さを-1〜1の中で表した値
具体性という面では回帰係数のほうが便利な一方で、相関の強さを知りたい場合は最大値と最小値が決まっている相関係数が便利です。
相関係数のほうが計算が簡単なため、最初に相関係数を算出してから必要なものだけ回帰係数を算出することもあります。
このように目的に合わせて回帰係数と相関係数のどちらを使うべきか、考える必要があります。
6.まとめ
最後におさらいをしましょう。
- 回帰分析とはある要素とある要素の関係性を回帰式という式に当てはめる分析
- 代表的な回帰分析は単回帰分析、重回帰分析、ロジスティック分析
- 回帰分析を行うことで、目的変数にどの説明変数がどのくらい影響を与えているのか知ることができる
- 回帰分析を行う際は、多重共線性や説明変数の数、線形性が仮定できるかに注意が必要
たくさんのデータのうち、どの要素とどの要素が関係しているのか調査しなければいけない場面は非常によくあります。
その分析の第一選択として回帰分析が用いられることも多いため、回帰分析はビジネスや研究で最もよく使われる分析手法といっても過言ではありません。
回帰分析を使いこなし、結果を解釈できるだけでも多くの問題に対応が可能です。
もし似たような問題でお悩みであれば、是非一度検討してみてください。
最後までお読み頂きありがとうございました。
