テキストマイニングの使い方や事例、注意点を解説
1.テキストマイニングとは
テキストマイニングとは文章を対象としたデータマイニングのことです。
マイニングは「mining」と表記し、「採掘」という意味です。
データ分析と鉱山の採掘をかけて、機械学習や統計解析によって有益な情報を得ることをデータマイニングと呼んでいます。テキストマイニングは日本語だけでなく、英語やフランス語などどんな言語に対しても行うことができます。
データマイニングとテキストマイニングの違い
テキストマイニングはデータマイニングの一種です。
他のデータマイニングとテキストマイニングの違いは、分析の対象が「解析対象のデータが文章かどうか」です。
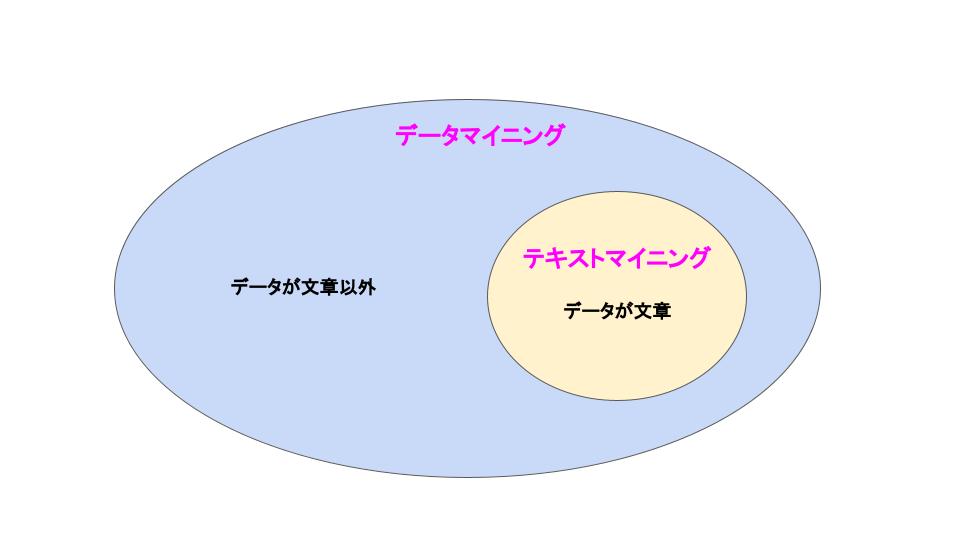
氏名や地名などのデータは文字ですが、たいていは文章ではなく単語として扱えます。
単語はダミー化などで簡単に数値に変換できるため、これらの分析をテキストマイニングということはありません。
一方、自由回答のアンケートや書籍のタイトルなど解析データが文章の場合は、簡単に数値化できず特殊な処理が必要なため、テキストマイニングと呼ばれます。
文章を数値化するために行われる特殊な処理については後ほどご紹介します。
テキストマイニングの利点
テキストマイニングの利点は、今まで分析ができなかった定性的な「文章」というデータを定量的に分析できるようになる点です。
これによりアンケートや商品レビューのような大量の文章を分析することができるようになりました。
最近のAIが発達した背景には文章や画像など、従来は解析できなかったものを解析できるようになったことが一つの要因でもあります。
そのように考えるとテキストマイニングはデータ分析の現場において、画期的な分析手法であることが分かります。
2.テキストマイニングを使った事例
迷惑メールの判別
テキストマイニングを使った有名な事例として、迷惑メールのフィルター機能があります。
大量のメール文章を学習データとして使用して、AIが文章の内容から迷惑メールかそうでないか判別をしています。
この技術によって一時は問題になっていた大量の迷惑メールの大半を淘汰することができました。
テキストマイニングとAIが実生活で役に立った分かりやすい事例です。
商品レビューの集約
テキストマイニングはネットショップの商品レビューの集約にも使われています。
大量のレビューを集約し、
「その商品に対して全体でどんなキーワードが一番使われているのか?」
「高評価の人、低評価の人はそれぞれどんなキーワードを使っているのか?」
など調査をすることができます。
この分析により消費者からみた商品の特徴や、評価が高いまたは低い理由を推察することができます。
実際にAmazonの商品レビューにはレビューで頻出している単語がピックアップされて表示されるようになっています。
この技術によってレビューを一つ一つ見なくても、全体としてその商品がどのような評価をうけているか一目で知ることができます。
ツイートの感情分析(ソーシャルリスニング)
テキストマイニングはX (旧Twitter)上であるキーワードに対して、どのような感情のツイートが多いか分析することも出来ます。
代表的な方法は、ポジティブかネガティブかなどのような感情です。
気になるキーワードに対して、ポジティブなツイートとネガティブなツイートがそれぞれどのくらい行われているのか知ることができます。
自社商品について書かれているツイートがポジティブなものが多いか、ネガティブなものが多いか解析して対策案の材料にする企業もあります。
テキストマイニングの発達により、最近はこのようなSNSの分析も行われるようになってきました。
3.テキストマイニングの使い方
単語の出現頻度の集計
テキストマイニングによって、全対象または特定の対象で出現頻度が多い単語を特定することができます。
例えば製品のアンケートで、高評価だった人たちの回答と低評価だった人たちの回答では使われている単語が異なります。
食品であれば高評価の人たちは「おいしい」や「コストパフォーマンス」などポジティブな単語が多いのに対して、低評価の人たちは「辛い」「高い」などネガティブな単語が多く使われているでしょう。
このように単語の出現頻度を集計するだけでも多くの情報を得ることができます。
テキストマイニングを最初にする場合は、どのような単語がよく出現しているのか、集計するところから始めることが多くあります。
予測
テキストマイニングによって教師あり学習を行うことで、文章から特定の事象を予測することができるようになります。
商品のレビュー内容から再購入率を予測したり、アンケート結果から将来の特定の行動を予測したり、様々な予測が可能です。
テキストマイニングは解析の過程で文章を数値に変換しているため、年齢や性別など他の情報を加えて予測をすることで、より精度を上げることも可能です。
分類
テキストマイニングは教師あり学習だけでなく、教師なし学習を行うことも可能です。
特にクラスター分析は教師なし学習の中でよく使われる分析の一つです。
例えば大量のツイートのデータにクラスター分析を行うことで、ツイート毎にグループ分けをすることができます。
そのグループ毎に使われている単語をみて、例えば「前向きなツイートグループ」「日常のツイートグループ」「宣伝のツイートグループ」などグループに意味付けを行うことも可能です。
同様の方法を用いてアンケート結果で消費者のタイプをグループ分けするなど、様々な応用ができます。
ここまでで代表的な3つのテキストマイニングの使い方を紹介しました。
もちろんこれら全ての方法を組み合わせて分析することもでき、テキストマイニングは非常に幅広い使い方が可能です。
しかしテキストマイニングは確かに便利ですが、何でもできるわけではありません。
ここからはテキストマイニングの限界についてもお伝えします。
4.テキストマイニングの限界
機械は文章の意味を理解しているわけではない
テキストマイニングによって、確かに文章の解析ができるのですが、コンピュータが文章の意味を理解しながら解析しているわけではありません。
あくまでも文章中で使われる単語の数や単語の種類を認識しているだけです。
そのため人間ほど文章を理解出来てはいません。
例えば「あなたのことを嫌いなわけがない」という文章をポジティブな文章か、ネガティブな文章か、分類するとしましょう。
もちろん嫌いではないということは好きだという意味ですので、ポジティブな文章であることが分かります。
しかしテキストマイニングだとこの文章はネガティブな文章に分類されてしまいます。
実はこのテキストマイニングでは単語の出現頻度だけをみて分類をしていたからです。
文章の「嫌い」というキーワードだけ拾ってしまい、その後の「ない」は別の単語としてカウントされてしまっていたのです。
もちろん「嫌い」も「ない」も否定的な単語ですので、ネガティブな文章に分類されてしまったというわけです。
このように単語の出現頻度だけを使ってテキストマイニングを行う場合、二重否定のような文章表現を反対の意味に誤解してしまう危険性があります。
また「それ」などといった指示詞の分析もテキストマイニングは苦手です。
なぜなら機械は文章の前後関係を理解していないため、「それ」が何を指すのか特定できないからです。
このようにテキストマイニングはあくまでも文章の特定の特徴を認識して解析しているだけであり、機械は文章を理解しているわけではないことを覚えておきましょう。
大量のデータが必要
テキストマイニングは基本的に文章中の単語を解析に利用しています。
しかしどの国の言語でも、単語の数は膨大です。
知らない単語が出てくると分析の精度が下がるため、単語の漏れがなるべくないようにデータを集めなければなりません。
そのためテキストマイニングを行うためには、大量の文章データを集める必要があります。
データ数がたとえば50程度しか集まらないような場合は、一つ一つ目視で確認しながら手作業で分析したほうがよい場合もあります。
処理に時間がかかる
テキストマイニングは大量のデータを使って大量の使用単語やその特徴を分析します。
そのためデータ数、特徴量ともに膨大な数となり、計算に時間がかかります。
テキストマイニングに取り掛かる場合はこの点も考慮しながら分析計画をたてるようにしましょう。
結果の解釈が難しいことも多い
テキストマイニングを行ってみたものの、予想したものと違う結果になり解釈が難しい場合があります。
高評価レビューなのに「だめ」という単語が多く出現していたり、解釈不能な単語が多く出現しているようなパターンです。
前者は「癖になるから食べちゃだめです」などのような文章が多いのかもしれませんが、後者は非常に厄介です。
このような場合は一つ一つレビューを実際に確認していく作業が必要になり、それでも分からない場合もあります。
テキストマイニングに限らず他の分析でも同じですが、必ずしも思った通りの結果が出てくるわけではないことは、覚えておきましょう。
5.文章を処理する方法
ここではテキストマイニングが、どのように文章を数値に変換しているのか、代表的な手法を紹介していきたいと思います。
処理①~文章を単語ごとに区切る~
分析の対象が日本語の場合、形態素解析という処理などを行うことによって文章を単語ごとに区切ることができます。
例:私/は/社会人/です/。/去年/から/社会人/に/なり/まし/た/。
形態素解析では文章を区切るだけでなく、動詞や名詞などの品詞を特定することも可能です。
ちなみに英語の場合はすでに単語間がスペースで区切られているため、形態素解析の必要はありません。
文章の区切りやすさという点では英語よりも日本語のほうが難しいです。
処理②〜単語の出現数をカウントする〜
ここでは文章を数値化した代表的な形であるBoW(Bag of Word)という形を紹介します。
形態素解析で単語ごとに区切った文章を、単語の出現数でカウントしていきます。
例:社会人:2、私:1、去年:1、です:1、、、、など
エクセルで表すと以下のような形になります。
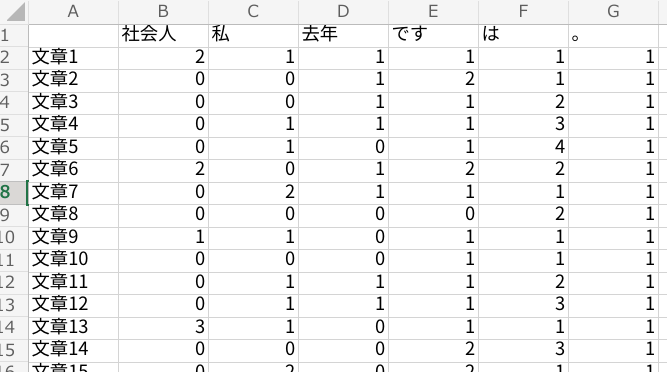
この形をBoWといいます。
これで文章を数値化することができました。
ちなみに単語ごとだけでなく、追加で2語ごとや3語ごとに区切ってカウントする方法もあります。
この方法では単語の出現する順番を考慮できる利点がある反面、情報量が増えるためより大量のデータが必要になる欠点があります。
処理③〜データマイニングを実施する〜
BoWなどの形にすれば、すでにデータは文章から数値に変換されていますので、通常のデータマイニングと同様の方法でデータ分析が実行可能です。
特定の単語を対象にピボットテーブルなどを使って集計をしたり、機械学習を使って教師なし学習、教師あり学習を行うことも可能です。
目的に合わせて適切な分析手法を選択するようにしましょう。
6.まとめ
最後におさらいをします。
- テキストマイニングは文章を対象としたデータ分析のことをさす
- 商品レビューやアンケート結果の分析などでテキストマイニングが使われている
- テキストマイニングは「単語の出現頻度の集計」「文章から特定の要素の予測「複数の文章のグループ分け」など様々な使い方が可能
- テキストマイニングは大量のデータと処理時間を要する点に注意が必要
- 機械は文章の特徴を学習しているだけで、文章の意味を理解して分析しているわけではない
- テキストマイニングは文章を単語ごとに区切り、単語の出現数をカウントするなどの手法を使って文章を数値に変換した後で、データマイニングを実行している。
テキストマイニングは通常のデータマイニングでは扱えなかった「文章」というデータを分析できる便利な分析方法です。
他のデータマイニングと比べて歴史も浅いため、これからますます発展していくことが予想されます。
文章には定量的なデータだけからは得られない重要な情報を持っています。
分析を諦めていた文章のデータなどがあれば、是非一度検討してみることをおすすめします。
最後までお読み頂きありがとうございました。
