ボックスプロットとは?
品質管理における外れ値の可視化
ボックスプロットとは箱ひげ図とも呼ばれ品質管理、統計学、データ分析などの分野で広く用いられるグラフの一種です。データの分布やばらつきを視覚的に表現し、データの特性を把握するのに役立ちます。
ボックスプロットとは?
ボックスプロットは、データの分布を示すデータ可視化ツールです。外れ値を示すのに優れたツールです。箱ひげ図とも呼ばれるこの手法では、最小値、第 1 四分位値 (Q1)、中央値、第 3 四分位値 (Q3)、最大値の 5 つの統計量を使用して、数値 y 変数とグループ化 x 変数の関係を示します。ボックスプロットには、下限値 (LAV)、上限値 (UAV)、および四分位範囲 (IQR) も含まれます。この方法は、外れ値、つまり LAV と UAV の外側にあるポイントを示すのに非常に効果的です。
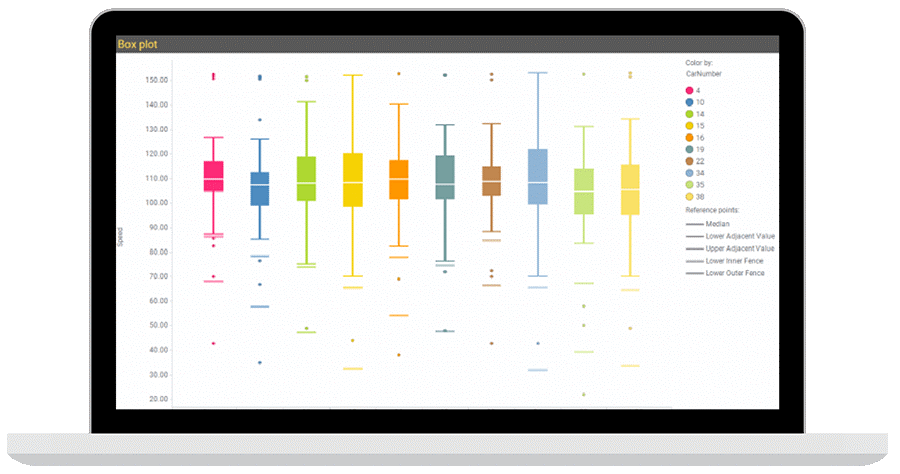
ボックスプロットは、数値データのグループがどのように局在し、ばらつき、または歪んでいるかを識別し、表示し、グラフで示すために使用されます。つまり、データ値がどの程度広く拡散しているかを示します。これは、直感的でコンパクトなデザインで情報を表示する方法です。中央値、データのばらつき、全体の範囲が明確であるため、ボックスプロットではデータ分布の変化がすぐに明らかになります。
この統計的視覚化の方法は、記述統計の概念に属します。これは主に、データの四分位数を通じて、数値データのグループを標準化された方法で描写するために使用されます。統計学における四分位数とは、データ観測方法を定義された4つの間隔に分割することを指す用語です。これらの4つの観測間隔は、関係するデータの値と、観測グループ全体との比較に基づいています。簡単に言うと、四分位数は、データを4分の1に分割する値を指します。したがって、最初の四分位数は25パーセンタイル、2番目の四分位数は50パーセンタイル (中央値とも呼ばれます) となります。
ボックスプロットはデータ分析に非常に役立つツールであり、次の情報を確認するために使用されます。
- 分布形状
- 中心値
- ばらつき
ボックスプロットは、データを効果的にボックス図で表現したものと考えてください。
幹葉図やヒストグラムは分布を適切に表現しますが、ボックスプロットは分布が正規分布か分布に偏りがあるかを示し、異常な観測値があればそれを示します。これらの外れ値は、問題のデータセットの「ひげ」とも呼ばれます。ひげ、または外れ値は、外部四分位より外側のデータの分布を示します。データセットの主な部分と大きく異なる外れ値は、ボックスプロットのひげの外側に個別にマークされることがあります。
ボックスプロットはノンパラメトリックです。つまり、統計値の変動を表示しますが、分布については何も仮定しません。分散の度合いはボックスプロットの各部分間の距離で示され、5つの統計量は偏ったデータを表現します。ボックスプロットは水平または垂直に表示することができ、複数のデータセットを比較するときに協力に役立ちます。
ボックスプロットは、データの中心を示す重要な方法の1つでもあります。中心統計量は、データ分布の中央を表す単一の中心値を使用してデータセット全体を説明しようとする要約統計量です。中心統計量では、平均、中央値、最頻値、中心範囲の4つの統計量が使用されます。中心統計量自体は非常に便利ですが、詳細な分析には中心統計量以上のものが必要です。ボックスプロットは、データ値が全体的にどのように広がっているかを判断するのに役立ち (データの中心と広がりが一目でわかるため)、ユーザーは分布を比較しやすくなります。さらに、ボックスプロットは他のグラフよりも場所を取らないという利点もあります。
データプロットの仕組み
ボックスプロットには、箱とひげという 2 つの主要な部分があります。下側ひげの底 (または点) はデータセットの0パーセンタイルであり、外れ値は含まれません。上側ひげの上限、つまり最高点は、データセットの最大値であり、これも外れ値は含まれません。箱は第1四分位から第3四分位まで描かれ、中央値を表す水平線が箱の中に描かれます。
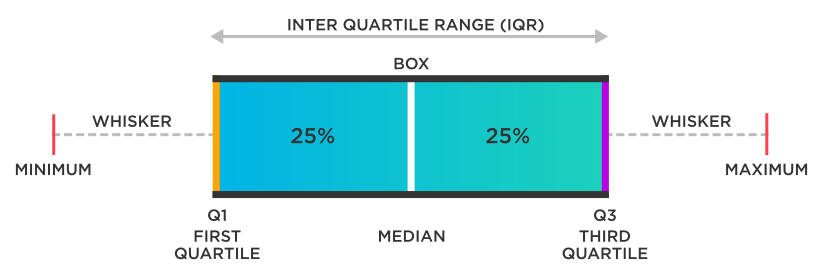
ひげはいくつかのものを表現することができます。
- 最高スコアと最低スコア
- 平均値より下と上に1シグマ
- 9パーセンタイルと91パーセンタイル
- 2パーセンタイルと98パーセンタイル
ボックスプロットには、多くの場合、ひげがあります。2パーセント、9パーセント、91 パーセント、98パーセントのパーセンタイルがあります。これらの通常とは異なるパーセンタイルは、「ひげのクロスハッチ」または「ひげの端」を表現することがあります。対象のデータが正規分布している場合、これらの7つのポイントの位置はボックスプロット上で均等に配置されます。
ボックスプロットのバリエーション
最もよく見られる2つのボックスプロットの派生形は、可変幅ボックスプロットとノッチ付きボックスプロットです。
可変幅ボックスプロット
可変幅ボックスプロットは、ボックスの幅で各データグループの大きさを表示します。ボックスの幅をグループの大きさの平方根に比例させることもできます。
ノッチ付きボックスプロット
ノッチ付きボックスプロットでは、中央値マークのボックスにノッチまたはインデントがあります。これらのノッチは、中央値の差の有意性について大まかに説明します。2つのボックスのノッチが重なり合っていない場合は、中央値の間に統計的に有意な差があることを示します。
調整済みボックスプロット
調整済みボックスプロットは、分布の歪度を示します。これは、単変量分布の歪度を表す メドカップル統計を表現します。これは、分布の右半分と左半分の中央値の差としてさらに定義できます。そのロバスト性から、調整済みボックスプロットの外れ値を識別するのに役立ちます。
通常のボックスプロットは、分布が歪んでいる場合には最適な視覚化ツールではありません。長く非対称な裾を外れ値として認識してしまうからです。そのため、歪んだ分布に合わせてボックスプロットのひげを調整するには、メドカップルを使用します。これにより、非対称分布の外れ値をより正確に表現できます。
バイオリンプロット
バイオリン・プロットは、カーネル密度プロットとボックスプロットのハイブリッド版です。一般的に、データの集中度を示すのに役立ちます。通常のボックスプロットと同様に、数値データの分布を視覚化しますが、ボックスプロットは統計の要約のみを表します。バイオリン・プロットは、要約統計とデータ の密度の両方を示します。
バイオリン・プロットは、グループ間の分布を比較するためのシンプルかつコンパクトな方法です。バイオリン・プロットにさらに多くのマークを追加してボックスプロットと同じ情報を表示できますが、これによりプロットにノイズが多くなり、読みにくくなる場合があります。
文字値プロット
ボックスプロットは、データセットの要約された分布を表示する優れた方法ですが、データセットが大きいほど不正確になります。また、ボックスプロットは理解しにくいものです。Boxen (文字値プロット) は、通常のボックスプロットを進化させたもので、分布をより正確に視覚化するために特別に設計されています。
文字値プロットでは、表示されるのは四分位数だけではありません。残りのスペースは、ボックスを追加してデータ セットのより小さなスペースを表すように分割されます。この手順は、最後のデータ ポイントに到達するまで無制限に継続して繰り返すことができますが、プロットが非常に複雑になり、読みにくくなるため、外れ値を検出して視覚化する必要が残ります。
このため、最後の文字値(「k」で示される)を決定するために停止基準が使用されます。各文字値の信頼性は、文字値の周囲の 95 パーセント信頼区間を計算することによって決定されます。この区間が前の区間と重なる場合、現在の値の不確実性は非常に高くなります。その場合、その後の文字値は表示されなくなります。
ボックスプロットの有用性と欠点
ヒストグラムやカーネル密度推定と比較すると、ボックスプロットは少し原始的な印象を受けますが、いくつかの明らかな利点があります。
- 統計学者が1つまたは複数のデータセットをグラフィカルに素早く調べることができる
- スペースをあまり取らず、複数のデータセット間の分布を並べて比較するのに便利
- 外れ値を表示し、わかりにくい結果を視覚化する
ボックスプロットには、いくつかの欠点もあります。
- 外れ値を含む大規模なデータセットの視覚化は不正確になる
- 特に複雑なデータの場合、理解や解釈が困難になることがある
- 分布結果の正確な値や詳細を保持しない。これは、大量のデータを処理する場合に問題となる可能性がある。
- 平均や分布の多峰性などの一部の情報が不明瞭になる可能性がある。
ボックスプロットの比較と読み取り
ボックスプロットを読み取って解釈する方法はいくつかあります。
- 各ボックスプロットのそれぞれの中央値を比較する場合、中央線の位置に注意してください。中央線がボックスの外側にある場合、比較対象の2つのグループ間に差がある可能性があります。
- ボックスの長さ (四分位範囲) を比較して、各サンプル間のデータの分散を調べます。ボックスが広いほどデータの分散は大きくなり、ボックスが狭いほどデータの分散は大きくなります。
- データの全体的な広がりは、最低値の端にあるひげで表されます。これは、データの範囲を示します。範囲が大きいほど、分布が広くなり、データがより散在していることを意味します。
- 外れ値とは、ボックスプロットのひげの外側にあるポイントです。データを正しく分析するには、潜在的な外れ値を探すことが必要です。
- 中央値と最大値の間の距離が中央値と最小値の間の距離よりも大きい場合、ボックスプロットは正に歪んでいます。
- 中央値と最小値の間の距離が中央値と最大値の間の距離よりも大きい場合、ボックスプロットは負に歪んでいます。
- 中央値が最大値と最小値の両方から等距離にある場合、ボックスプロットは対称であると言われます。
結論として、ボックスプロットは、最小限のスペースで多くの情報を表示する便利なグラフであり、データ分析の初期に使用して、データの初期パターンをより適切に認識するのに最適です。ボックスプロットを理解している読者なら、一目で豊富な情報が表示されます。ただし、ボックスプロットを理解していないユーザーにとっては、混乱を招いたり、誤解を招いたりする可能性があります。
関連製品
-
Spotfire組織全体でのデータ分析・活用を実現するオールインワンのデータ分析ソフトウェア詳しく見る
高い評価と実績