データサイエンスとは?
仕組みやスキル、業界毎課題例について
データサイエンスは、大量のデータから有用な情報やパターンを見つけ出し、ビジネスに活かすための学問です。統計学や機械学習などの手法を用いて、過去のデータから未来を予測したり、新たなビジネスチャンスを発見したりすることができます。
高い評価と実績

データサイエンスとは?
データサイエンスとは、様々な分析手法、専門知識、テクノロジーを組み合わせ、組織のデータに隠されているパターンを発見し、抽出し、インサイトを明らかにするためのアプローチです。このアプローチには、一般的に、データマイニング、予測、機械学習、予測分析、統計学、テキスト分析などの分野が含まれます。
データは今、驚異的なスピードで増えています。それに伴い、企業はデータに隠されたインサイトをいかに活用していくかが重要になってきています。しかし、ほとんどの企業において、自社のビッグデータを分析し、新たなインサイトを発見したり、潜在的な問題を探求できる人材が不足しているのが現状です。データサイエンスの価値を社会実装し収益に結びつけるためには、予測インサイトや最適化戦略をビジネスや運用システムに取り入れる必要があります。現在、知識労働者に独自の機械学習プロジェクトやタスクの遂行を支援するプラットフォームを提供するサービスが多く存在しています。膨大な量のデータの中から、トレンドやビジネスチャンスを抽出できるようになれば、市場において大きなアドバンテージを得ることができるでしょう。
データサイエンスには記述的分析、診断的分析、予測的分析、処方的分析が含まれます。つまり、データサイエンスによって、何が起こったか、なぜ起こったか、何が起こるか、何をすべきかということをデータから判断することができます。
データサイエンスの仕組み
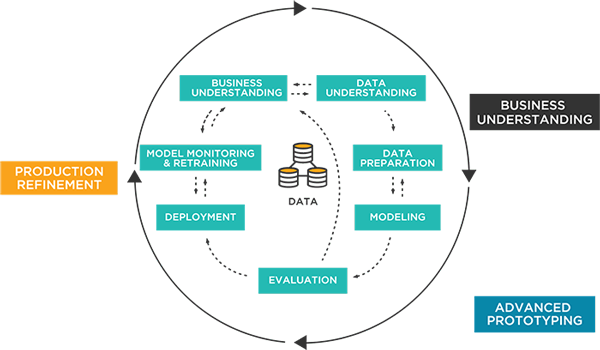
概念的にデータサイエンスのプロセスを理解するのは難しいことではありません。以下のステップで構成されます。
- ビジネス上の問題の理解
- 生データの収集と統合
- データの探索、変換、クレンジング、準備
- データモデルの作成と選択
- モデルのテスト、チューニング、デプロイ
- モデルの監視、テスト、更新、管理
ビジネスの問題を理解する
データサイエンスの第一歩は、ビジネスユーザーの課題を理解することから始まります。例えば、あるビジネスユーザーが「どうすれば売り上げを伸ばせるか?」や「顧客に販売するにはどのような手法が効果的か?」という課題を持っています。課題を理解したいと思っても、このように大雑把で曖昧な課題では、すぐに検証できるような仮説には繋がりません。データサイエンティストの役割は、このようなビジネス上の課題を、研究・検証可能な仮説に落とし込むことです。例えば、「どうすれば売り上げを伸ばせるか?」という質問の粒度を下げると、「売上の増加につながる条件は何か?プロモーションなのか?天候なのか、あるいは季節性なのか?」「制約に基づいて売上を最適化するにはどうすればよいか?」「各店舗の明日/来週/来月の売上はどのくらいになるだろうか?」といった具合に、より具体的な内容に落とし込めます。ここで重要なことは、判断を下すべき意思決定をよく理解し、そこから逆算する必要があるということです。もし1時間先、1日先、1週間先、1ヶ月先を予測できるとしたら、ビジネスプロセスはどのように変わるでしょうか。
生データの収集と統合
ビジネス上の問題を理解できたら、次は生データの収集と統合を行います。最初に、アナリストは利用可能なデータを確認する必要があります。多くの場合、データはさまざまな形式やシステムに分散して存在しているため、データラングリングやデータ前処理の技術を用いて、生データを分析に適した形式に変換する必要があります。もしデータが利用できない場合は、データサイエンティスト、データエンジニア、IT部門と協力して、新しいデータをテスト用のサンドボックスに取り込むこともあります。
データの探索と準備
次にデータを探索しましょう。データサイエンティストは、グラフや他のビジュアライゼーションを使ってデータを整理し、データの中に隠れたパターンや相関関係、異常値を発見するために、データビジュアライゼーションツールを使用します。ここで初めて、アナリストは問題解決に繋がる要因を発見できます。データの挙動や考慮すべき潜在的な要因が明らかになれば、データを変換し、新しい特徴(あるいは変数)を作成し、モデリングのためにデータを準備します。
モデルのテスト、チューニング、デプロイ
このプロセスでは、機械学習、深層学習、予測、自然言語処理(あるいはテキスト分析)などの手法を用いて、入力されたデータからアルゴリズムを使ってモデルを作成し、それぞれのモデルをテストします。統計モデルやアルゴリズムをデータセットに適用し、予測変数(例えば、ターゲットに影響を与える要因)に基づいてターゲット変数(例えば、予測しようとしているもの)の挙動を一般化するプロセスです。
このプロセスにおいて得られるアウトプットは、予測、異常検出、最適化であり、ダッシュボードや埋め込み型レポートとして表示されます。また、ビジネスシステムに直接取り込まれて、影響力のある意思決定を行うことができます。モデルが可視化ツールやビジネスシステムにデプロイされた後は、新しい入力データをスコアリングするために使われます。
モデルの監視、テスト、更新、管理
モデルがデプロイされた後は、現実世界の事象の変化に伴うデータの変化に応じて、モデルを更新したり再トレーニングできるように監視する必要があります。したがって、組織は、本番モデルの変更を管理するためのモデル運用戦略を策定しておくことが不可欠です。
ダッシュボードや本番システムにモデルをデプロイするだけでなく、データサイエンティストは、可視化ツールやダッシュボードツールから呼び出すことができる高度なデータサイエンスパイプラインを作成することもできます。たいていの場合、これらのパイプラインはシチズンデータサイエンティストが調整できるよう、パラメータや要因のセットを減らして、簡略化されています。これは、上述したスキル不足に対処するのに役立ちます。つまり、シチズンデータサイエンティスト(多くの場合、ビジネスや特定分野の専門家)は、複雑な背景を理解せずとも、関心のあるパラメータを選択するだけで、非常に複雑なデータサイエンスのワークフローを実行できます。これにより、データサイエンティストを介することなく、さまざまなシナリオをテストできるのです。
要約すると、データサイエンティストは、データを使ってストーリーを語り、現実世界のアプリケーションに使える予測インサイトを提供します。使用されるプロセスは、次のようなものです。
- 入力データ
- データ準備
- 機械学習の適用
- モデルのデプロイ、スコアリング、管理
- 出力データ

データサイエンスプロセスの主なステップ
ビジネス理解
- ビジネス上の意思決定を理解する
- 意思決定に必要なデータを決める
- 意思決定の結果、ビジネスがどのように変わるかを認識する
- 意思決定をサポートするために必要なアーキテクチャを決める
- 部門横断的な技術チームとプロジェクト管理チームを編成する
機械学習プロセスの理解
- データの収集と統合
- データ探索、準備、クレンジング
- データ前処理、変換、特徴量の生成
- モデルの開発と選択
- モデルのテストとチューニング
- モデルのデプロイ
運用モデルとガバナンスプロセスの理解
- モデルリポジトリ、ドキュメント、バージョン管理
- モデルのスコアリング、APIフレームワーク、コンテナ戦略
- モデルの実行環境
- モデルのデプロイ、統合、結果
- モデルの監視、テスト、更新
データサイエンスに必要なスキルとは?
ビジネススキル:コラボレーション、チームワーク、コミュニケーション、ドメイン知識/ビジネス知識
分析スキル:データ準備、機械学習、統計学、地理空間分析、データビジュアライゼーション
コンピュータサイエンス/ITスキル:データパイプライン、モデルデプロイメント、監視、管理、プログラミング/コーディング
どのような人がデータサイエンスを使うのか?
シチズンデータサイエンティスト:日常的にデータ活用と分析を行っており、ポイントアンドクリックのインターフェースで特定のビジネス課題を解決している。
ビジネス主導の人:事業部主導の取り組みや、業務改善に注力している。
スペシャリスト:事業部門を横断して問題解決に取り組み、IT部門と協力して機械学習モデルの運用を行っている。経営幹部からの賛同と資金提供を得ている。
ハイエンドユーザー:多様なデータソースを活用して新たな問題を解決し、機械学習を使ったソリューションのプロトタイプを作成する。データサイエンスワークフローを大規模に実行している。R、Python、Scala、Hadoop、Sparkなどのツールを好む。
潜在ユーザー:データサイエンスに興味はあるが、サポートやトレーニングがないと感じたり、再利用可能なテンプレートを提供する技術を持つ組織で働いていないため、まだ実行に移せない人たち。
データサイエンスの主なタスク
- 問題の理解と分析
- データの収集、データ準備/クレンジング、基本的な探索的データ分析
- モデルの開発とテスト
- モデルのデプロイ、監視、ガバナンス
- ビジネス意思決定者に対する調査結果の伝達
データサイエンスが対処している課題
データサイエンスがさまざまな業界で対処している課題をいくつか紹介します。
エネルギー
エネルギー分野では主に、掘削、生産、操業を最適化しながら、次のような予測のために使われています。
- 設備の故障予測
- 将来の石油量と価格の予測
- 流通の最適化
- 排出量の削減
- 地盤組成の分析
- 貯留層の特性評価
金融/保険
金融、保険業界では、主にリスクの低減、不正行為の検出、顧客体験の最適化に重点を置いています。具体的には、以下の通りです。
- 信用リスクの予測
- 不正行為の検出
- 顧客分析
- ポートフォリオリスクの管理
- 解約可能性の判断
- SOXやバーゼルⅡなどの規制への対応
医療
医療分野では、医療の質の向上、業務改善、コストの削減に使われています。
- 疾患リスクの予測
- 不正請求の検出
- 個々人の投薬量の処方
- 画像解析による癌の検出
- 保険金請求の管理
- 患者の安全性向上
- リスクの高い患者の特定
製薬
製薬業界では、安全性、製品品質、薬効などを確保するために使われています。
- ゴールデンバッチの決定
- 臨床試験の分析
- 製品のトレース
- 安定性と保存期間の分析
- 規制遵守のための報告と分析の検証
- 製造プロセスとデータの分析
製造業
製造業では、プロセスの最適化、品質の向上、サプライヤーの監視に役立ちます。
- 歩留まりの向上
- 廃棄、出戻り、リコールの削減
- 保証不正の検出
- 規制遵守の確保
- 設備の故障予測と防止
データサイエンティストが直面する課題
データにアクセスできない
<対処方法>
- 複数のデータソースからのデータを仮想データレイヤーに統合する。
- データを視覚的に操作、クレンジング、変換し、分析に適した状態にする。
- データの関係を理解し、モデル構築のために検証する。
ダーティデータ
<対処方法>
- AIを活用したビジュアルラングリングにより、自動的に変換を提案し、異常値を除去し、データをクレンジングする。
- 欠損値を補完したり、重要でない変数を除去するなど、分析用データの健全性チェックを自動化する。
- 異なるソースのデータを大規模にフォーマットし、準備する。
限られた人材と専門知識
<対処方法>
- 自動化されたレコメンデーションとビジュアルインサイトを用いて複雑性を理解する。
- 少数のデータサイエンティストだけでなく、チーム全体の創造性を活用し、エンドツーエンドの分析ライフサイクルで協働する。
- シチズンデータサイエンティストが実行できるパラメータ化されたテンプレートを作成し、機械学習をスケールする。
結果が活用されない
<対処方法>
- 業務システムへのデプロイを簡素化し、影響のあるビジネスプロセスに機械学習を組み込む。
- モデルのモニタリング、再トレーニング、ガバナンスでデータサイエンスを運用化する。
- データパイプライン、モデル構築、スコアリング、アプリ開発など、エンドツーエンドの分析ライフサイクル全体でスムーズな連携を成功させる。
データサイエンスの課題を解決するために
みんなのデータサイエンス:自動化、再利用可能なテンプレート、クロスファンクショナルチームのための共通のコラボレーションフレームワークにより、データサイエンスを民主化とコラボレーションを実現させる。
イノベーションの加速: ネイティブアルゴリズム、オープンソース、パートナーエコシステムにより、ガバナンスを確保しながら、柔軟なソリューションを迅速にプロトタイプ化する。
AnalyticOps: パイプラインのモニタリング、管理、更新、ガバナンスを通じて、データサイエンスの運用に重点的に取り組み、データサイエンスの価値を収益化する。
トレーニング: データサイエンスの実践を学びたいシチズンデータサイエンティストやその他の人々に教育とトレーニングを提供する。
センター・オブ・エクセレンス: ベストプラクティスを促進し、イノベーションと再利用性を促進するために、CoEを設立し、データサイエンスを企業全体にスケールさせる。
関連製品
-
Spotfire組織全体でのデータ分析・活用を実現するオールインワンのデータ分析ソフトウェア詳しく見る
高い評価と実績

