ランダムフォレストとは?
機械学習での品質管理や予測分析
「ランダムフォレスト」は、多数の決定木を用いて予測分析を行う機械学習アルゴリズムです。分類、回帰、クラスタリングなど多岐にわたる分析に対応し、高精度な予測と多様なモデル構築を可能にします。ビジネスにおいては、品質評価、顧客離反予測、年間消費額の高い顧客の特定など、データに基づく意思決定を支援します。
ランダムフォレストとは?
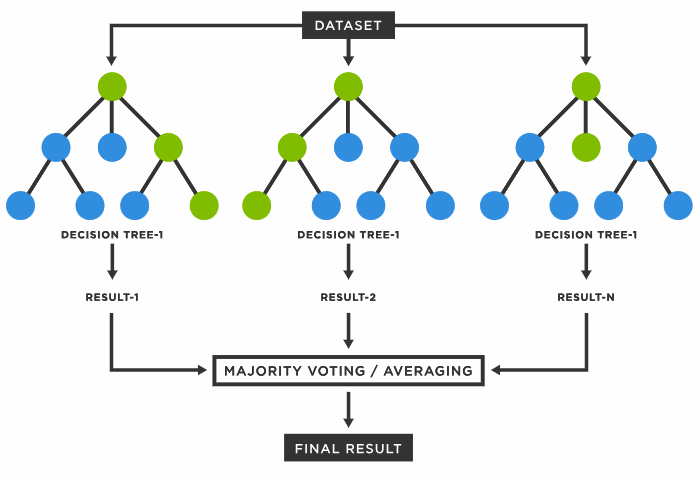
ランダムフォレストとは、分類、回帰、クラスタリングに用いられる機械学習のアルゴリズムであり、その精度、シンプルさ、柔軟性から最も使用されるアルゴリズムの1つです。非線形性に対応することに加えて、分類と回帰の両方に使用できることから、さまざまなデータや状況に高度に適用できます。
ランダムフォレストという用語は、1995年にTin Kam Hoによって最初に提案されました。Hoは、ランダムなデータを使用して予測を行うための式を開発しました。その後2006年に、Leo BreimanとAdele Cutlerがアルゴリズムを拡張し、現在私たちが知っているランダムフォレストを開発しました。これは、この技術とその背景にある数理科学が比較的新しいものであることを意味します。
「フォレスト」と呼ばれるのは、決定木からなる森を育てるためです。これらの木からのデータを結合して、最も正確な予測を行います。単一の決定木は1つの結果と少数のグループしか持たない一方で、フォレストはより多数のグループと決定でより正確な結果を保証します。また、ランダムな特徴のサブセットから最適な特徴を見つけることで、モデルにランダム性を追加する利点があります。これらの利点から、多くのデータサイエンティストに好まれる多様性のあるモデルを作成できます。
決定木とは?
決定木(Decision Tree)とは、おそらくあなたが日常生活で毎日使用しているものです。例えば、ソファを買う際に友人におすすめを聞いた場合、友人はあなたにとって何が重要かを尋ねます。サイズや色、生地は革がよいか?など、これらの決定に基づいて、あなたの選択に沿った完璧なソファを見つけることができます。決定木は、答えにつながる一連の真偽の質問を行います。
各「テスト」(たとえば革か布か?)はノードと呼ばれます。各枝はその選択の結果(布)を表します。各葉(Leaf)ノードはその決定のラベルです。実際の進め方では、観察値を分割して、全体を異なるグループに分けながら、内部ではお互いは似ているが、他のグループとは異なるサブグループが生成されます
「決定木」と「ランダムフォレスト」の違いとは?
ランダムフォレストは、決定木のグループです。ただし、2つにはいくつかの違いがあります。決定木は、決定を下すためのルールを作成する傾向があります。ランダムフォレストは、ランダムに特徴を選択し、観察を行い、決定木からなる森を構築し、その結果を平均化します。
理論的には、相関のない多数の木の群は単体の決定木よりも正確な予測を作成するとされています。これは、複数のツリーがお互いのエラーや過剰学習が発生しないように協調するためです。 ランダムフォレストがうまく機能するためには、次の3つが必要です。
- モデルが推測だけでなく識別可能な信号を持っていること
- ツリーによって行われる予測が他のツリーと低い相関関係を持っていること
- 予測力がある程度ある特徴:GI=GO
ビジネスにおけるランダムフォレストアルゴリズムの活用法
ビジネス環境では、ランダムフォレストを使用する多くの応用例があります。例えば、単一の決定木は、ワインに関するデータセットを分類し、さまざまなワインを軽いワインと重いワインに分類することができます。
ランダムフォレストは多数の木を作成し、最終的な予測結果をはるかに洗練されたものにします。ワインを例に取ると、価格、タンニン、酸味、アルコール含有量、糖分、入手可能性など、幅広い特性を比較する複数の木を持つことができます。その後、結果を平均化することで、膨大な数の基準に基づいて、総合的なワインについての予測を行うことができます。
ビジネスでは、ランダムフォレストアルゴリズムは特定範囲を持った入力データと複雑な条件がある場合に使用できます。例えば、顧客離れの時期を特定する場合です。顧客の離反要因は複雑であり、一般に、製品のコスト、製品の満足度、顧客サポートの質、支払いの容易さ、契約期間の長さ、提供される追加機能などの要因が含まれる上に、顧客の性別、年齢、居住地も関係します。ランダムフォレストアルゴリズムはこれらすべての要因に対して決定木を作成し、どの顧客が離反リスクが高いかを正確に予測できます。
もう1つの複雑な例は、1年間で最も多く出費する顧客を予測することです。幅広い変数と属性が分析され、マーケティング部門がその年にターゲットにすべき顧客を予測することができます。
ランダムフォレストにおけるバギングとは?
バギング(ブートストラップ集約)は、個々の決定木をデータセットからランダムにサンプリングし、データを置き換えて、個々の木で非常に異なる結果を作成できるようにします。つまり、利用可能なすべてのデータを使う代わりに、各ツリーは一部のデータのみ利用します。これらの個々のツリーは、与えられたデータだけに基づいて結果を予測します。
つまり、各ランダムフォレストは、異なるデータでトレーニングされ、異なる属性を使用して予測したツリーで構成されます。これにより、ツリーにエラーや不正確な予測を防ぐバッファが提供されます。 バギングのプロセスでは、データの約3分の2しか使用されないため、残りの3分の1はテストセットとして使用できます。
ランダムフォレストの利点
相対的な重要性を簡単に測定できる
各ツリーでその属性を使用して不純度を減らすノードを見ることで、属性の重要性を測定することができます。変数を置換する前後の違いが簡単に分かるため、その変数の重要性を測定することができます。
多用途性
ランダムフォレストは分類と回帰の両方のタスクに使用できるため、非常に多目的です。ランダムフォレストは、2値および数値特徴量だけでなく、カテゴリカル特徴量も簡単に処理でき、変数変換や再スケーリングの必要がありません。多くの他のモデルと異なり、あらゆるタイプのデータに対して非常に効率的です。
過学習を防ぐ
ランダムフォレストに十分な数の木がある場合、過学習のリスクはほとんどありません。決定木も過学習することがありますが、ランダムフォレストは複数の異なるサブセットから異なるサイズの木を構築し、その結果を組み合わせることでそれを防ぎます。
高い精度
ランダムフォレストでは、サブグループ間に大きな差異がある木を複数使用することで、非常に正確な予測になります。
データ管理に費やす時間を短縮
従来のデータ処理では、貴重な時間の大部分がデータのクレンジングに費やされることが多いです。ランダムフォレストは、欠損データをうまく扱うため、クレンジングを最小限に抑えることができます。完全なデータと不完全なデータからの予測を比較したテストでは、ほぼ同じ性能レベルが示されました。外れ値のデータや非線形特徴量は基本的には無視されます。
ランダムフォレスト手法は、集団内のエラーとその他の不均衡なデータセットのエラーを均衡させるためにも機能します。これは、エラー率を最小限に抑えることで行われます。つまり、大きなクラスはより低いエラー率を持ち、小さなクラスはより高いエラー率を持ちます。
トレーニングの速さ
ランダムフォレストは特徴量のサブセットを使用するため、数百の異なる特徴量を迅速に評価できます。生成されたフォレストは将来にわたって保存および再利用できるため、予測速度が他のモデルよりも速くなります。
ランダムフォレストの課題
出力の遅さ
アルゴリズムが多数の木を構築するため、予測の洗練度と精度が向上します。ただし、数百または数千の木を構築するため、モデリングの速度が低下します。これにより、リアルタイム予測には適していません。
【解決策】
Out-of-bag(OOB)サンプリングを使用することができます。この場合、予測に2/3のデータのみを使用します。ランダムフォレストプロセスは並列化も可能であるため、処理を多数のマシンに分割して実行することで、単独システムよりもはるかに高速に処理できます。
外挿ができない
ランダムフォレストの予測は、それ以前に観測されたラベルの平均に依存するため、その範囲はトレーニングデータの最小値と最大値の間に制約されます。これは、トレーニングと予測の入力が異なる範囲と分布を持つ入力データでのみ問題となりますが、この共変量シフトにより、一部の状況では異なるモデルを使用する必要があります。
解釈可能性の低さ
ランダムフォレストモデルは究極のブラックボックスです。説明できないため、どのようにして、またなぜそのような決定に至ったのかを理解することは困難です。この不透明性は、モデルをそのまま信頼して、結果をそのまま受け入れる必要があることを意味します。
ランダムフォレストの代替手段
ニューラルネットワーク(NN)
ニューラルネットワークは、データ内の関係を決定するために多数のアルゴリズムが一緒に動作します。それは、人間の脳がどのように機能するかを再現しようと設計されており、常に変化し、入力されたデータに合わせて反応します。音声や画像などの非構造化データでも扱えるため、ランダムフォレストよりも大きな利点があります。また、データと必要な結果に合わせて多数のハイパーパラメータを細かく調整することもできます。 ただし、作業するデータが表形式の場合は、ランダムフォレストを使用することが最善です。ニューラルネットワークは工数とコンピュータリソースを必要とし、不必要な細かい計算を多く行う場合があります。単純な表形式のデータでは、ニューラルネットワークとランダムフォレストは予測に関して類似の結果を示します。
エクストリーム勾配ブースティング(XGBoost)
XGBoostはランダムフォレストよりも正確で強力だと言われています。ランダムフォレストと勾配ブースティング(GBM)を組み合わせて、より正確な結果を生成します。XGBoostは、独立して予測するのではなく、順次に予測することで、よりゆっくりとしたステップを踏みます。残差のパターンを使用してモデルを強化します。これにより、予測誤差がランダムフォレストよりも少なくなります。
線形モデル
線形予測モデルは、最も単純な機械学習手法の1つです。広く使用されており、適切なデータセットで実行されると、強力な予測ツールになります。また、解釈が容易であり、ランダムフォレストのようなブラックボックス化はありません。ただし、線形データのみを使用するため、ランダムフォレストよりも大幅な制約を持ちます。データが非線形の場合、ランダムフォレストが最良の予測を提供します。
クラスターモデル
クラスタリング方法の上位5つには、ファジークラスタリング、密度ベースのクラスタリング、分割法、モデルベースのクラスタリング、階層的クラスタリングが含まれます。いずれもある形式で、オブジェクトのグループを類似のグループまたはクラスターにまとめます。これは、データサイエンスの多くの領域で使用され、データマイニング、パターン認識、機械学習の一部です。ランダムフォレスト内でクラスタリングを使用することができますが、それ自体が単独の技術です。 クラスターモデルは、新しいサンプルに適応し、クラスターサイズや形状を一般化し、その結果は貴重な洞察を提供します。 ただし、クラスタリングは外れ値や非ガウス分布に対してうまく対処できません。大量のサンプルを処理する場合、クラスタリングにはスケーリングの問題が発生する場合があります。最後に、特徴量の数がサンプル数よりも多くなることがあります。
サポートベクターマシン(SVM)
サポートベクターマシンは、データを分析し、回帰分析と分類に使用されます。これはロバストな予測方法であり、信頼性の高い分類モデルを構築します。これらのモデルは、データポイント間の距離の考え方に依存していますが、すべての場合で意味があるわけではありません。ランダムフォレストは、分類問題でクラスに属する確率を算出しますが、サポートベクターマシンは境界までの距離を算出するため、さらに確率に変換する必要があります。
ベイジアンネットワーク
ベイジアンネットワークは、変数、依存関係、および確率を示すグラフィカルモデルです。これらは、データからモデルを構築し、結果を予測し、異常を検出し、推論を提供し、診断を実行し、意思決定を支援するために使用されます。ベイジアンネットワークは生成的であり、与えられたランダム変数から確率分布をモデル化します。それはランダム変数への複雑な問合せに最も適しています。ランダムフォレストは記述的なモデルであり、一般的には分類に使用されます。因果関係が関心の対象である場合は、ランダムフォレストよりもベイジアンネットワークの方が適している場合があります。データプールが大きい場合は、ランダムフォレストが好ましいです。
ランダムフォレストの未来
ランダムフォレストは、多くのデータサイエンティストにとって優れた教師あり機械学習モデルであり、高い効果、適応性、高速性があります。多くの別の手段より優れた正確な予測と分類を提供します。ただし、結果がどのように得られたかについては、大部分が説明できず、ブラックボックスになる可能性があります。
将来的には、従来のランダムフォレストを他の戦略と組み合わせることで、予測をより正確にし、さらに結果を最適化することが可能になるかもしれません。また、「説明可能な機械学習」への飛躍は現実味を帯びており、ランダムフォレスト予測のいくつかの謎を解明するのに役立つかもしれません。
関連製品
-
Spotfire組織全体でのデータ分析・活用を実現するオールインワンのデータ分析ソフトウェア詳しく見る
高い評価と実績