![]()
![]()
![]()
![]()

2020/12/21
統計分析
このコンテンツでは、データの相関を調べる方法について説明していきます。なお、本コンテンツで利用したSpotfireのバージョンは10.10/11.4です。ご利用環境によって、一部画面構成が異なる可能性がありますので、ご了承ください。

本コンテンツで利用するサンプルファイルは、こちらからダウンロードしてください。
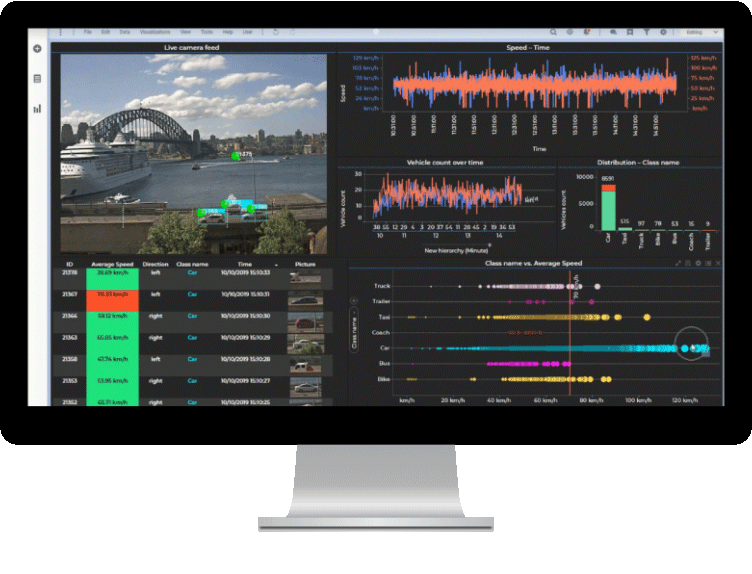
Baseball.dxpファイルをダブルクリックすると、Spotfireが起動します。起動時の画面です。Baseball.dxpは、野球に関するデータを可視化したファイルとなっており、2ページ構成になっています。最初のページはカバーページです。
新規ページを作成します。左下「Getting Started」タブの右にある「+」ボタンをクリックします。
以下の新規ページが立ち上がりました。
カラムの相関性を調べるには、Data Relationshipsを使用します。この機能を使用して、様々なカラム間の相関性を見ることができます。
上部メニュー「ツール」をクリックして、Data Relationshipsをクリックします。
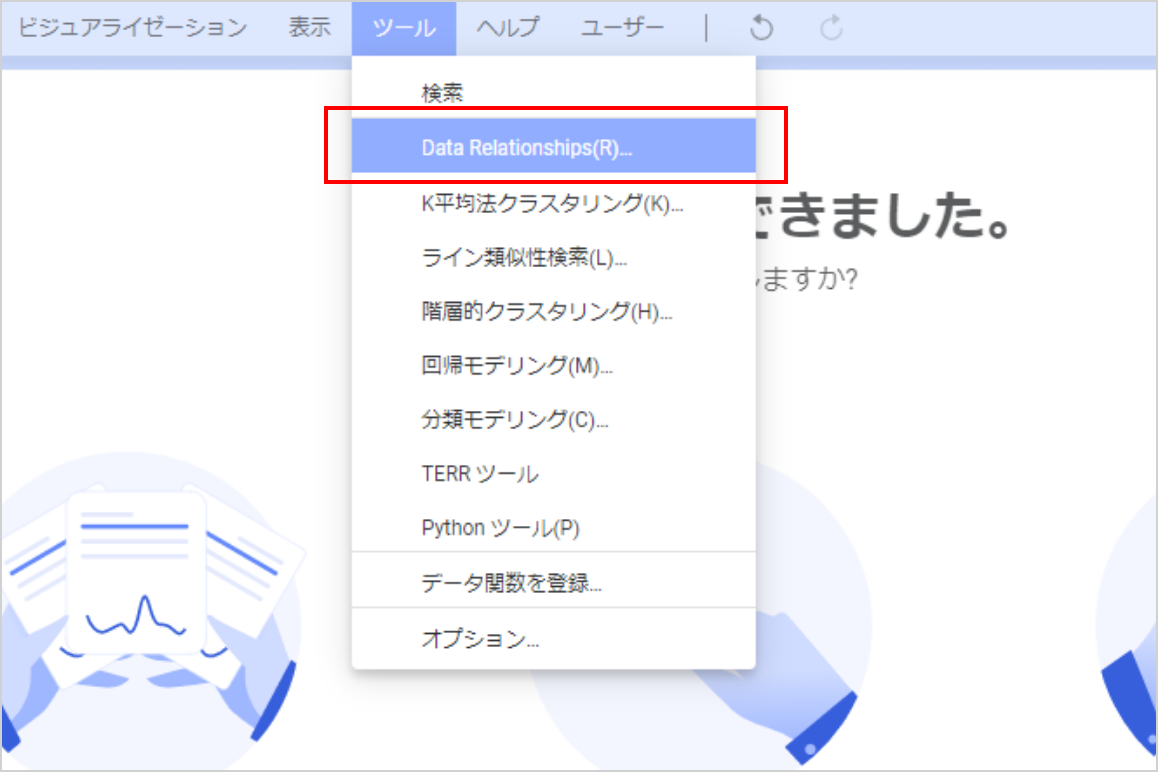
Data Relationshipsでは比較方法、X軸、Y軸の3つの設定項目があります。データの方式に応じて比較方法を選択し、X軸×Y軸のペアの総当たりで比較を行います。
データには数値データとカテゴリデータがあります。「数値×数値」が2つ、「数値×カテゴリ」が2つ、「カテゴリ×カテゴリ」が1つで計5つのアルゴリズムを選択できます。
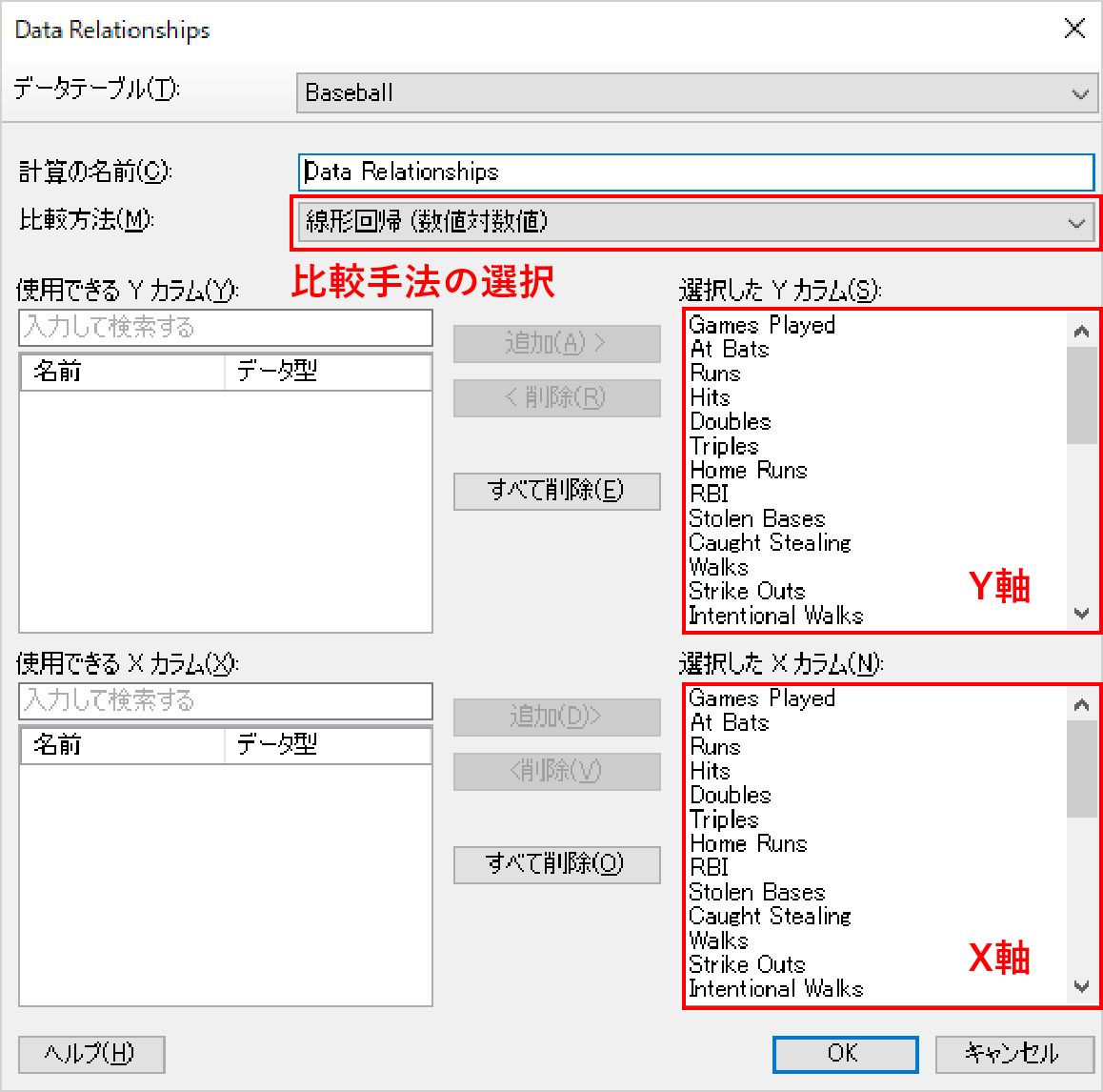
数値カラム同士を比較したければ、「線形回帰」か「スピアマンR」を使用します。カテゴリデータと数値データを比較する場合は、「Anova」か「クラスカル・ウォリス」を選択します。カテゴリカラム同士を比較する場合は「カイ 2 乗オプション」を使用します。
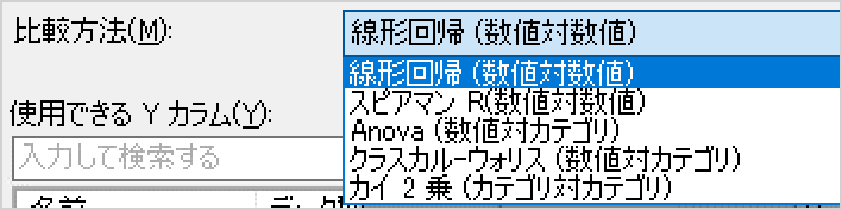
「スピアマンR」と「クラスカル・ウォリス」はノンパラメトリック手法となっています。悩んだ場合は「数値×数値」の場合は「線形回帰」、「数値×カテゴリ」の場合は「クラスカル・ウォリス」を選択します。
実行すると、カラムペアについてそれぞれp-valueが計算されます。p-valueは、最初のカラムの値から 2 番目のカラムの値をどの程度予測できるかを示すものです。p-valueが0に近ければ近いほど、2つのカラムの相関性は強いと考えられます。
今回の比較方法は「線形回帰」を選択してみます。
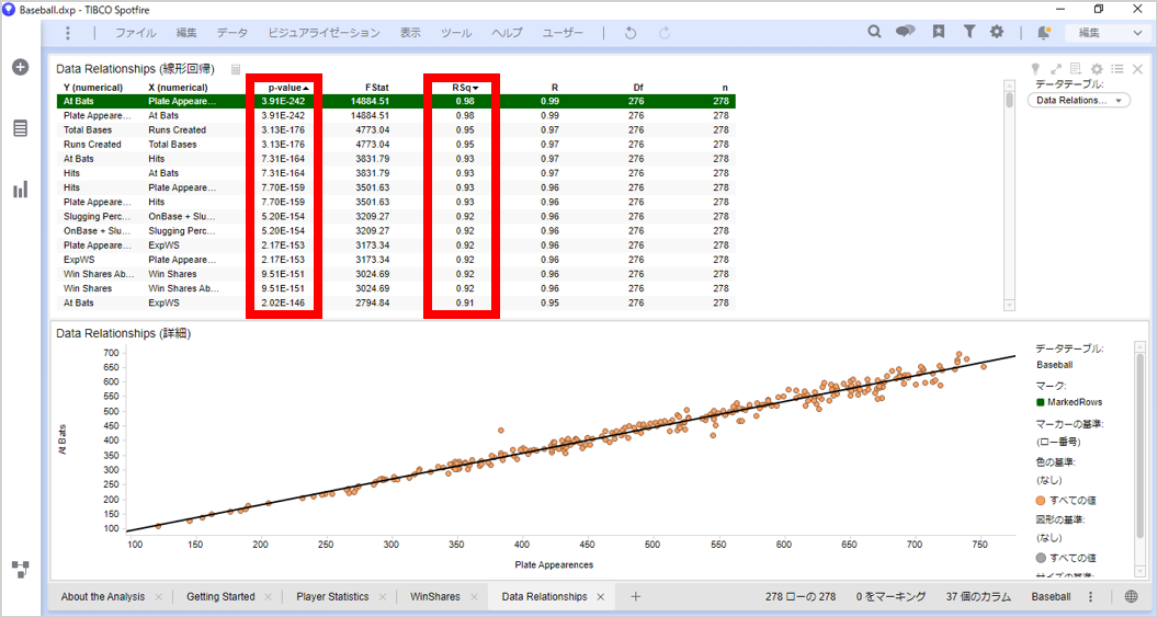
線形回帰の場合は、p-valueだけでなくRSq(相関係数)にも注目します。その値が1に近いときは正の相関、-1に近ければ負の相関があることがわかります。
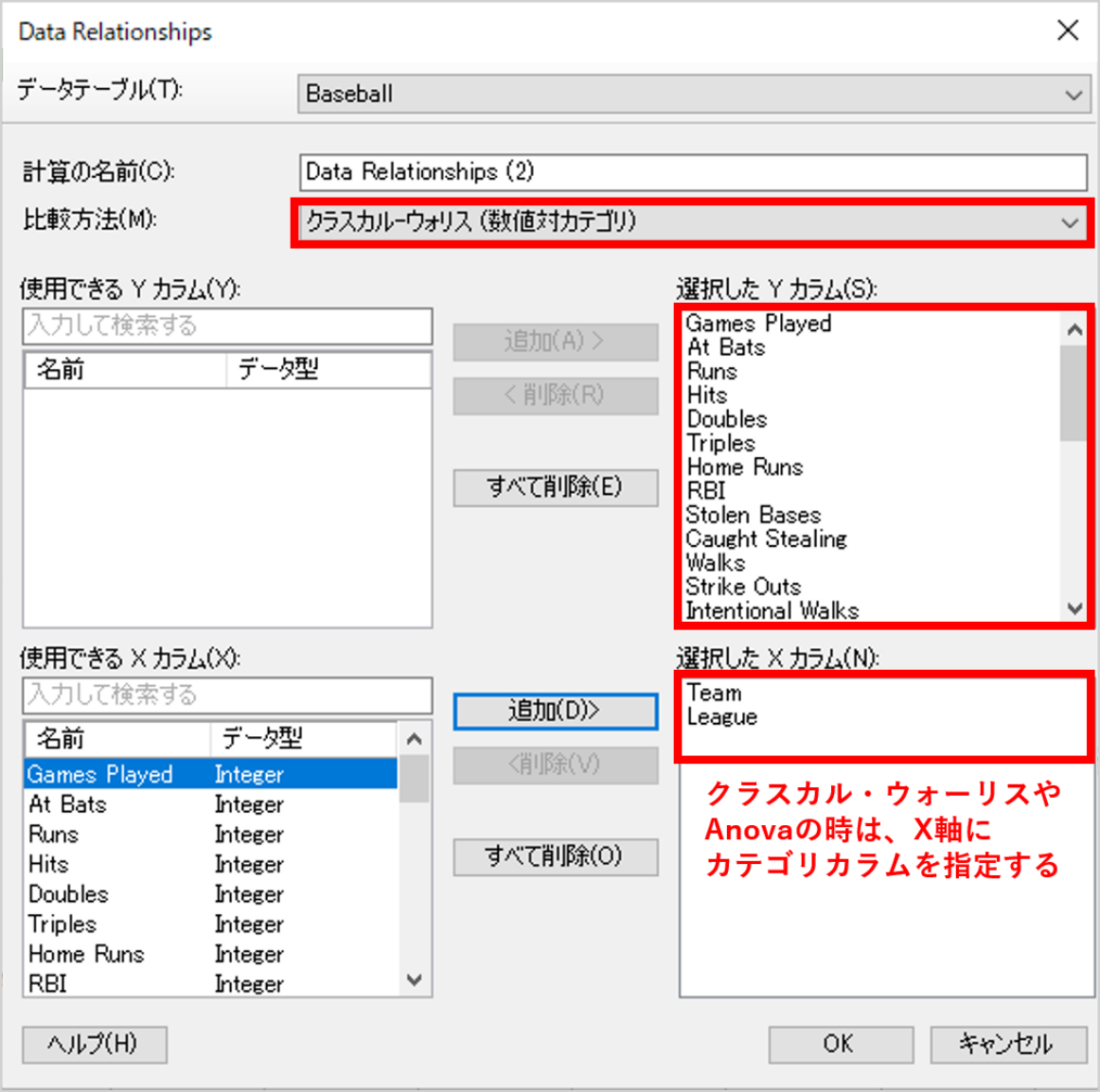
比較方法で「Anova」か「クラスカル・ウォリス」を選択した場合は、「選択したXカラム」にカテゴリデータを入れてください。
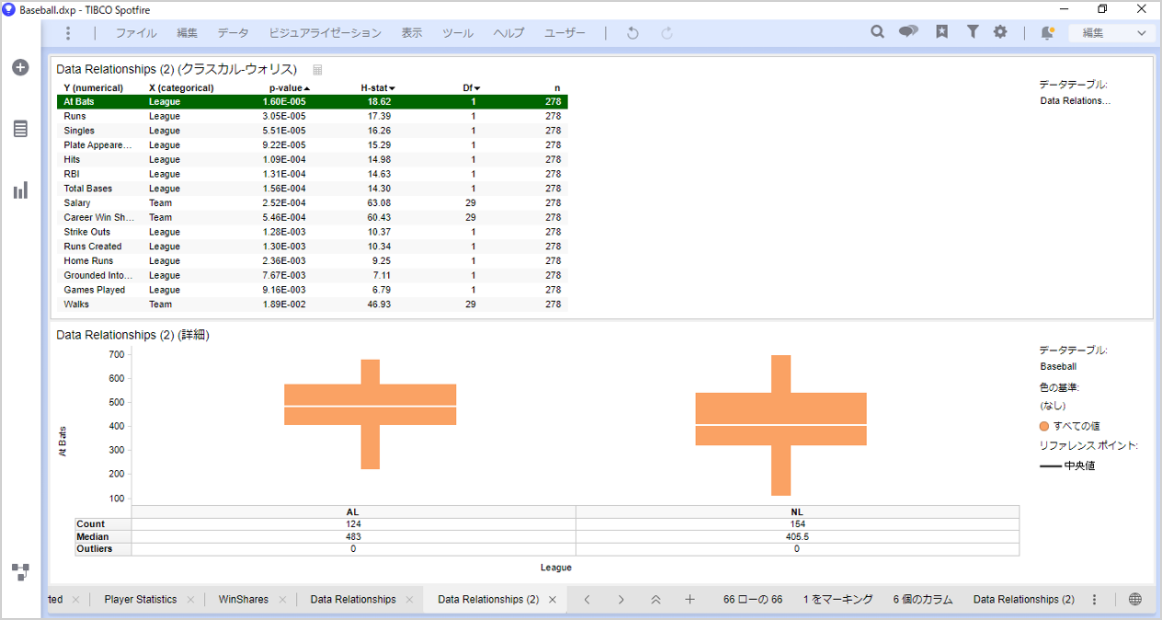
「数値・カテゴリ」の場合は分散分析になるので、結果は箱ひげ図になります。
箱ひげ図の解釈に不慣れな方は、プロパティの表示から「分布を表示する」にチェックを入れると分かりやすいです。
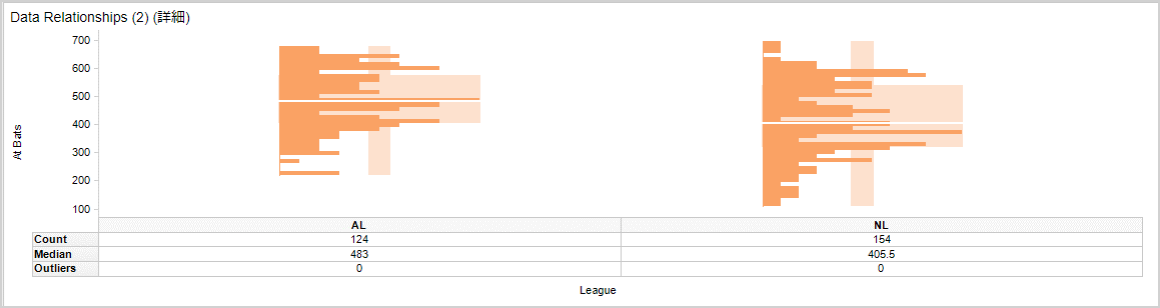
分布を表示すると、横向きのヒストグラムのような表示になります。
現在表示しているデータで、カテゴリごとに大きな違いがある場合などは、個別に比較する必要が出てきます。
フィルターをかけて比較するのが便利ですが、その際計算表は自動的には更新されません。
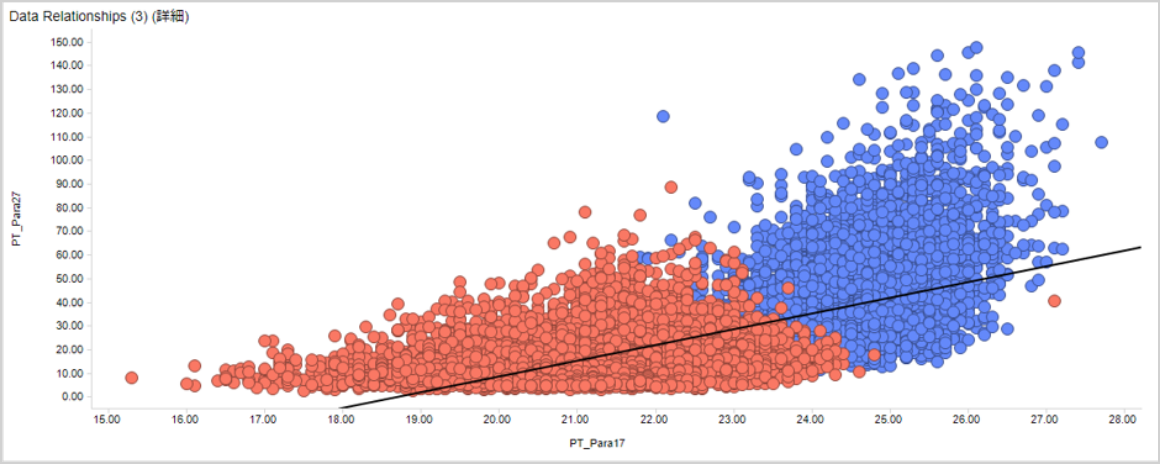
↑は半導体のデータを使用した線形回帰です。このように、全体では相関がありそうでも、2つのカテゴリ間で大きく分散が異なっている場合があります。その際はカテゴリごとに分けて見ましょう。
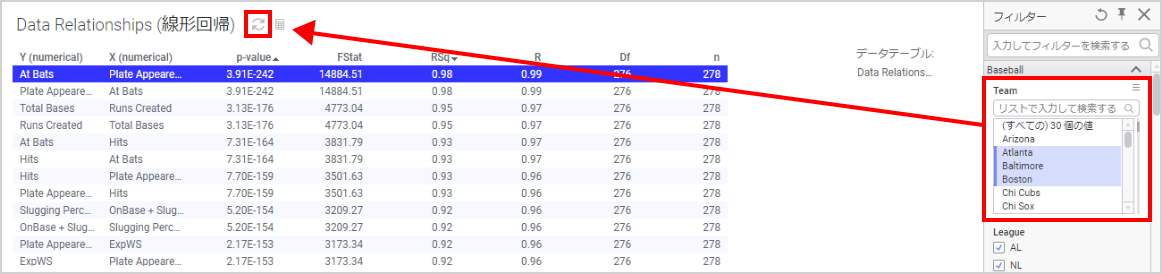
フィルター後には、結果表のタイトルに更新ボタンが表示されます。クリックすると、現在のデータを元に再計算されます。
前の記事
回帰分析の実行次の記事
データを類似度でグループ化【統計分析】最新の記事


